本文主要是介绍[SQL] 通过工商信息筛选潜在客户,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今日心情 :佛系的很
对于业务来说,经常会碰到一种需求:手里有一个公司名单(可能也就十几二十个公司名称),深入接触了几次之后,发现这类公司似乎合作意向都很大,具有很大的开发潜力。如果能找到跟这些公司相类似的企业,说不定能扩大客户池,进而带来业绩的增长,收获很多小钱钱。
如果还不会数据挖掘算法,如何先给出一份比较可靠的同类公司名单呢?头大。。。
不过既然要找相似企业,免不了要检索全国所有公司,如果数据库里有全国企业的工商信息数据,可以考虑用SQL先来应个急。
声明:本文重点在于介绍处理这类问题的思路,数据都是东拼西凑的。如有相同,纯属巧合
第一步:获取样本企业的相关信息
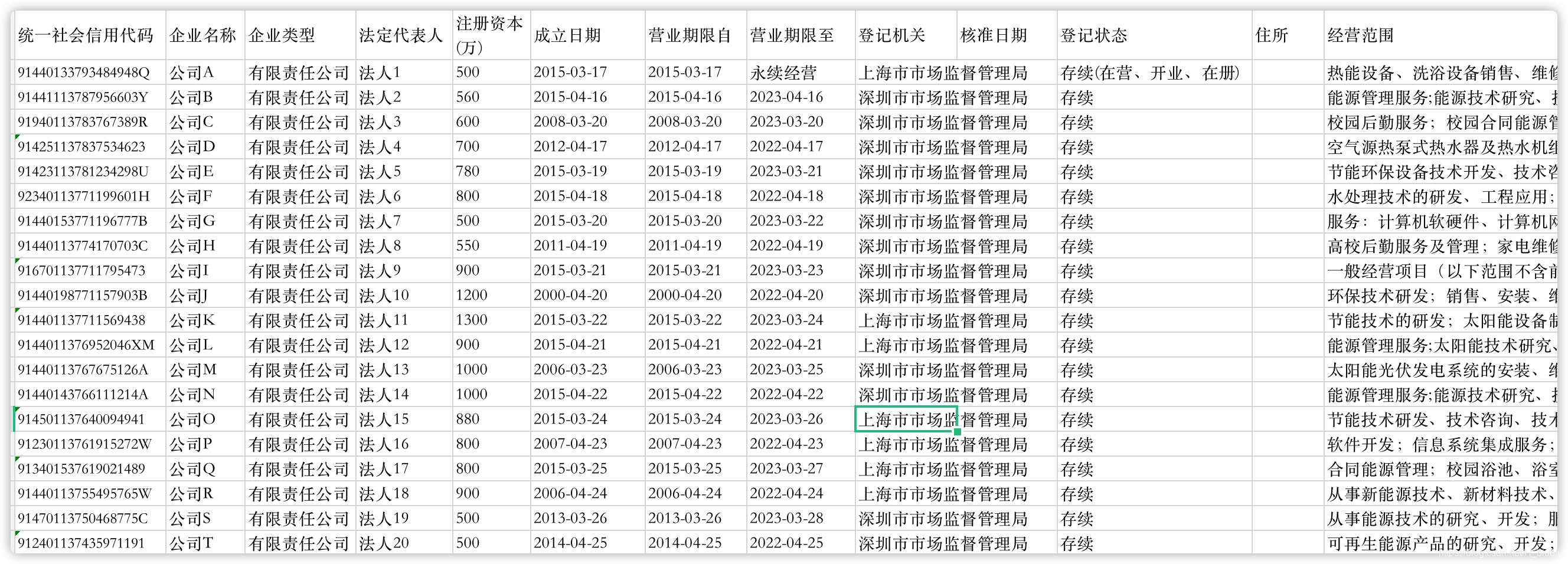
已知,样本企业名单如下:
公司A、公司B、公司C、公司D、公司E、公司F、公司G、公司H、公司I、公司J、公司K、公司L、公司M、公司N、公司O、公司P、公司Q、公司R、公司S、公司T
企业工商信息表结构(表结构参考 国家企业信用信息公式系统 中企业的营业执照信息)如下:
表名:enterprise (企业工商信息表)
| 字段含义 | 字段名称 |
|---|---|
| 统一社会信用代码 | crn |
| 企业名称 | entity_name |
| 企业类型 | entity_type |
| 法定代表人 | legal_repr |
| 注册资本(万) | regist_capital |
| 成立日期 | establish_date |
| 营业期限自 | start_from |
| 营业期限至 | start_to |
| 登记机关 | register_org |
| 核准日期 | approve_date |
| 登记状态 | status |
| 住所 | address |
| 经营范围 | scope |
在工商数据表中查询样本企业的工商信息:
select * from enterprise where entity_name in ('公司A','公司B','公司C','公司D','公司E','公司F','公司G','公司H','公司I','公司J','公司K','公司L','公司M','公司N','公司O','公司P','公司Q','公司R','公司S','公司T')
第二步:提取样本企业的特征
能作为特征的,都是有具有较强标识性的。比如一个人,性别可以作为TA的一个特征,但是过于宽泛。我们若是想进一步知道TA是哪一类人,就得再给他贴一些标识,或者标签。而且这些标签得是简短、概括性的。比如:长发、胸大、腰细等,这样,这个人就会在我们的脑海里更加的具象化(想太多的,自行面壁去)。
而对于一个只知道工商信息的企业来说,能用来判断是否是同类企业的最重要字段也就是经营范围了。但是经营范围都是一大段一大段的,所以我们得对它进行语义上的分析,用更简短的词语,去标识这个企业。
经营范围分词
将刚刚获取的样本企业的工商数据导出为csv文件(文件名:sample_enter.csv),用python对所有样本企业的经营范围进行分词
1.也可以用python连接数据库,执行sql语句获取结果。考虑到之后这部分数据可能会频繁使用,我就直接导出成文件了。
2.分词用的是百度的自然语言处理API接口,主要是想用它的词性分析功能。如果想简单点,可以用一些分词的在线工具,对每个企业的经营范围依次进行分词。但是如果样本企业过多,可能会比较费事
import timefrom aip import AipNlp
import pandas as pd''' 创建API的client '''APP_ID = '24037821' # 替换成自己的
API_KEY = 'gSH3nPHazXwsjGtZHdqQxRaR' # 替换成自己的
SECRET_KEY = '3SOC3G45LSXwmKeyZsdgQZ9uMySQrbHL' # 替换成自己的client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
client.setConnectionTimeoutInMillis(3600)sample_enter 这篇关于[SQL] 通过工商信息筛选潜在客户的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






