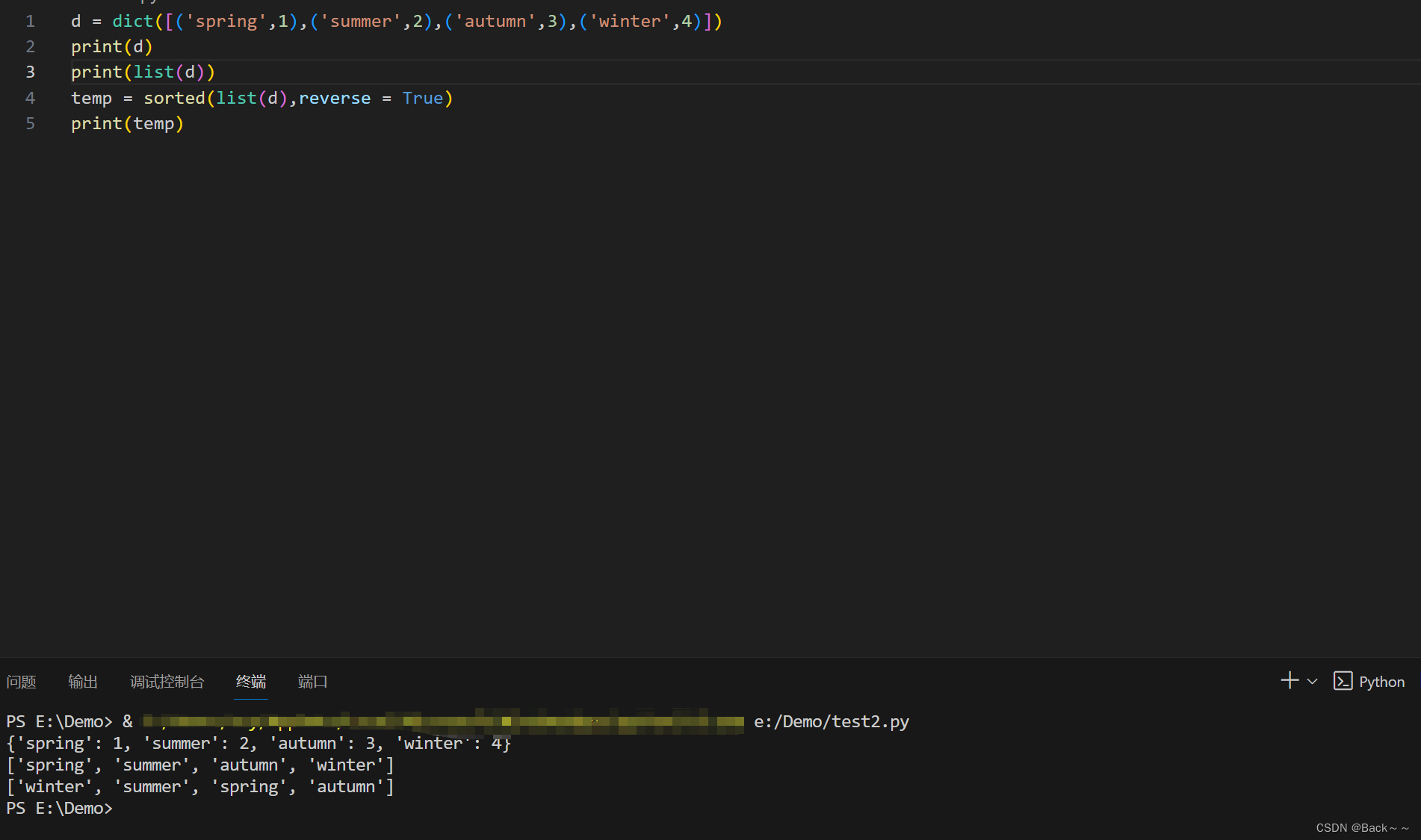
本文主要是介绍python(ch3),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

语句 dict2={[1,2,3]:'uestc'} 不能创建字典,因为字典的键必须是唯一的,而列表不能作为字典的键。
错误原因
在 Python 中,字典是无序的键值对集合。字典的键必须是唯一的,并且可以是任何可哈希的对象,例如字符串、数字或元组。
列表是可变的有序元素集合。列表不能作为字典的键,因为列表的元素可以重复,并且列表的顺序可以改变。
解决方案
要创建包含列表的字典,可以使用以下方法:
- 将列表转换为元组。元组是不可变的有序元素集合,可以作为字典的键。
dict2 = {(1, 2, 3): 'uestc'}
- 将列表转换为字符串。字符串可以作为字典的键。
dict2 = {str([1, 2, 3]): 'uestc'}
- 使用自定义函数将列表转换为哈希值。
def hash_list(list):return sum(list)dict2 = {hash_list([1, 2, 3]): 'uestc'}
总结
列表不能作为字典的键,因为列表的元素可以重复,并且列表的顺序可以改变。要创建包含列表的字典,可以将列表转换为元组、字符串或使用自定义函数将列表转换为哈希值。
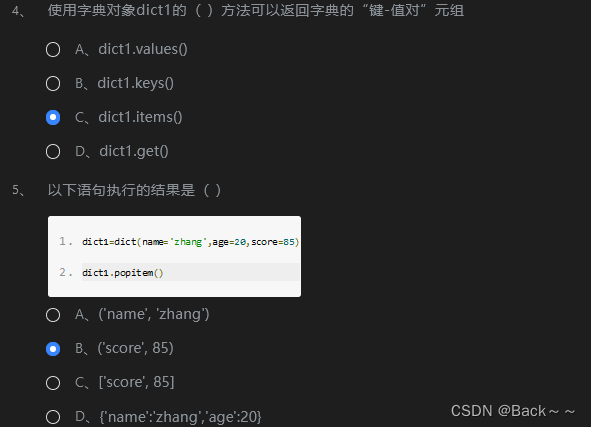
答案是 C、dict1.items()。
解释
dict1.values()返回字典中所有值的列表dict1.keys()返回字典中所有键的列表dict1.items()返回字典中所有键值对的元组列表dict1.get()根据键获取值
示例
dict1 = {'a': 1, 'b': 2, 'c': 3}# 返回所有值
values = dict1.values()
print(values)# 返回所有键
keys = dict1.keys()
print(keys)# 返回所有键值对
items = dict1.items()
print(items)# 根据键获取值
value = dict1.get('a')
print(value)
输出
[1, 2, 3]
['a', 'b', 'c']
[('a', 1), ('b', 2), ('c', 3)]
1
总结
dict1.items() 方法可以返回字典的“键-值对”元组
答案是 B、(‘score’, 85)。
解释
dict1=dict(name='zhang',age=20,score=85)创建一个字典dict1,其中包含三个键值对:name、age和scoredict1.popitem()删除字典中的最后一个键值对,并返回该键值对
示例
dict1 = dict(name='zhang', age=20, score=85)# 删除最后一个键值对
item = dict1.popitem()# 打印删除的键值对
print(item)# 打印字典
print(dict1)
输出
('score', 85)
{'name': 'zhang', 'age': 20}
总结
dict1.popitem() 方法删除字典中的最后一个键值对,并返回该键值对。
注意
dict1.popitem()方法会随机删除字典中的最后一个键值对- 如果字典为空,则
dict1.popitem()方法会引发KeyError异常
其他相关方法
dict1.pop()根据键删除字典中的键值对,并返回该键值对dict1.clear()删除字典中的所有键值对
()、[]和{}
()、[]和{} 是 Python 中常用的三种符号,它们分别用于不同的目的:
1. ():
-
圆括号主要用于以下几种情况:
- 函数调用:例如,
print()、len()、max()等函数都需要使用圆括号来调用。 - 运算符优先级:例如,
2 + 3 * 4中,乘法运算优先于加法运算,因此需要使用圆括号来改变运算顺序。 - 条件判断:例如,
if x > 0:中,圆括号用于包含条件表达式。
- 函数调用:例如,
2. []:
-
方括号主要用于以下几种情况:
- 列表创建:例如,
[1, 2, 3]表示一个包含三个元素的列表。 - 访问列表元素:例如,
list[0]表示列表中的第一个元素。 - 切片操作:例如,
list[1:3]表示从列表第二个元素到第三个元素(不包括第三个元素)的子列表。
- 列表创建:例如,
3. {}:
-
花括号主要用于以下几种情况:
- 字典创建:例如,
{'name': 'zhang', 'age': 20}表示一个包含两个键值对的字典。 - 集合创建:例如,
{1, 2, 3}表示一个包含三个元素的集合。 - 格式化字符串:例如,
f'Hello, {name}!'表示一个格式化字符串,其中name将被替换为实际值。
- 字典创建:例如,
总结
()主要用于函数调用、运算符优先级和条件判断。[]主要用于列表创建、访问列表元素和切片操作。{}主要用于字典创建、集合创建和格式化字符串。
以下是一些示例:
# 函数调用
print("Hello, world!")# 运算符优先级
print(2 + 3 * 4)# 条件判断
if x > 0:print("x is positive")# 列表创建
list = [1, 2, 3]# 访问列表元素
print(list[0])# 切片操作
print(list[1:3])# 字典创建
dict = {'name': 'zhang', 'age': 20}# 集合创建
set = {1, 2, 3}# 格式化字符串
print(f'Hello, {name}!')
输出
Hello, world!
14
x is positive
[1, 2, 3]
1
[2, 3]
{'name': 'zhang', 'age': 20}
{1, 2, 3}
Hello, zhang!
Python 中字典、元组、列表三者的区别
1. 存储方式
- 字典:使用键值对存储数据,键是唯一的,值可以是任意类型。
- 元组:使用有序的元素存储数据,元素可以是任意类型。
- 列表:使用有序的元素存储数据,元素可以是任意类型。
2. 访问方式
- 字典:通过键来访问值。
- 元组:通过索引来访问元素。
- 列表:通过索引来访问元素。
3. 可变性
- 字典:可变,可以添加、删除、修改键值对。
- 元组:不可变,创建后无法修改。
- 列表:可变,可以添加、删除、修改元素。
4. 应用场景
- 字典:通常用于存储映射关系,例如用户信息、商品信息等。
- 元组:通常用于存储不变的数据,例如日期、时间等。
- 列表:通常用于存储可变的数据,例如学生成绩、商品列表等。
以下是三者的具体区别:
| 特性 | 字典 | 元组 | 列表 |
|---|---|---|---|
| 存储方式 | 键值对 | 有序元素 | 有序元素 |
| 访问方式 | 键 | 索引 | 索引 |
| 可变性 | 可变 | 不可变 | 可变 |
| 常用场景 | 映射关系 | 不变数据 | 可变数据 |
总结
- 字典、元组和列表都是 Python 中常用的数据结构。
- 字典用于存储映射关系,元组用于存储不变的数据,列表用于存储可变的数据。
- 在选择使用哪种数据结构时,应根据具体的需求进行选择。
以下是一些使用示例:
- 字典
# 创建字典
user_info = {'name': '小明', 'age': 18}# 获取值
name = user_info['name']
age = user_info['age']# 添加键值对
user_info['address'] = '北京'# 删除键值对
del user_info['age']
- 元组
# 创建元组
date_tuple = (2023, 12, 25)# 获取值
year = date_tuple[0]
month = date_tuple[1]
day = date_tuple[2]# 元组不可变,无法修改
# date_tuple[0] = 2024
- 列表
# 创建列表
student_scores = [90, 85, 75]# 获取值
score1 = student_scores[0]
score2 = student_scores[1]
score3 = student_scores[2]# 添加元素
student_scores.append(95)# 删除元素
del student_scores[1]
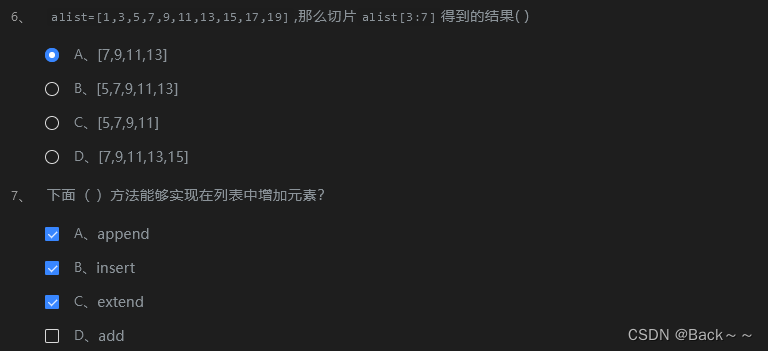
答案是 A、append、B、insert 和 C、extend。
解释
append()方法用于在列表末尾添加一个元素。insert()方法用于在列表的指定位置插入一个元素。extend()方法用于将另一个列表添加到列表末尾。
示例
# 使用 append() 方法在列表末尾添加一个元素
list = [1, 2, 3]
list.append(4)
print(list)# 使用 insert() 方法在列表的指定位置插入一个元素
list = [1, 2, 3]
list.insert(1, 4)
print(list)# 使用 extend() 方法将另一个列表添加到列表末尾
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1.extend(list2)
print(list1)
输出
[1, 2, 3, 4]
[1, 4, 2, 3]
[1, 2, 3, 4, 5, 6]
总结
append()、insert() 和 extend() 方法都可以用于在列表中增加元素。
add() 方法
https://blog.csdn.net/weixin_44851971/article/details/105696294
其他相关方法
list.pop()方法用于删除列表中的最后一个元素。list.remove()方法用于删除列表中指定的元素。list.clear()方法用于清空列表。

代码:
list1 = ['a', 'b', 'c']
list2 = list1
list1.append('de')
print(list2)
输出:
['a', 'b', 'c', 'de']
解释:
list1 = ['a', 'b', 'c']: 这行代码创建一个名为list1的列表,并将其赋值为包含字符 ‘a’、‘b’ 和 ‘c’ 的列表。list2 = list1: 这行代码将list1的引用赋值给list2。这意味着list1和list2都指向内存中的同一个列表对象。它们不是单独的副本,而是同一个底层数据的不同名称。list1.append('de'): 这行代码使用append方法将字符串 ‘de’ 添加到list1的末尾。由于list1和list2引用同一个对象,因此此修改会影响两个列表。
输出解释:
- 即使赋值
list2 = list1没有明确复制元素,但两个列表仍然包含 ‘a’、‘b’ 和 ‘c’。这是因为它们都引用同一个底层列表对象。 - 当您使用
append将 ‘de’ 添加到list1时,它会修改原始列表对象,该对象也被list2引用。因此,list1和list2现在都包含更新后的列表,其中 ‘de’ 位于末尾。
关键要点:
- 将列表赋值给另一个变量不会创建副本,而是分配对同一个对象的引用。
- 对可变对象(如列表)通过一个变量进行的修改也会反映在引用同一个对象的其它变量中。
相关知识:
- Python 中的赋值和引用
- 可变对象和不可变对象
- Python 列表操作
答案是 B、[1, 2, 3, 2]。
解释:
x.pop()方法用于删除列表中的最后一个元素。- 在本例中,
x的初始值为[1, 2, 3, 2, 3]。 - 执行
x.pop()之后,列表中的最后一个元素3将被删除。 - 因此,
x的最终值为[1, 2, 3, 2].
示例:
x = [1, 2, 3, 2, 3]# 删除列表中的最后一个元素
x.pop()# 打印列表
print(x)
输出:
[1, 2, 3, 2]
总结:
x.pop() 方法会删除列表中的最后一个元素,并返回该元素。
其他相关方法:
list.pop(index)方法用于删除列表中指定位置的元素。list.remove(value)方法用于删除列表中指定值的元素。list.clear()方法用于清空列表。
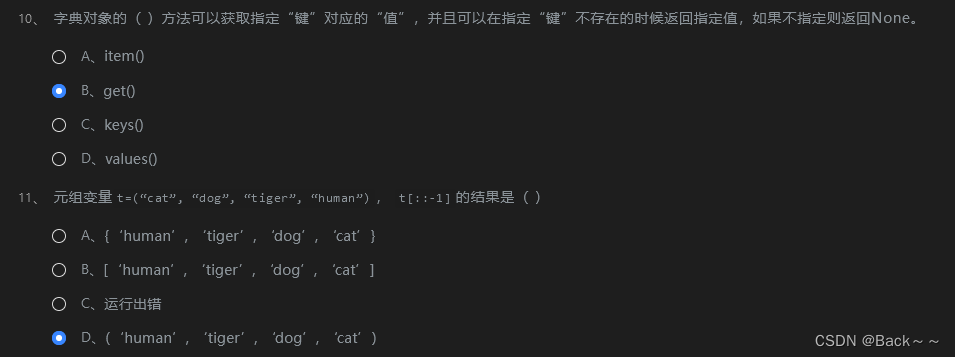
答案是 B、get()。
解释:
item()方法用于获取字典中指定键对应的值,但如果键不存在,则会引发KeyError异常。get()方法用于获取字典中指定键对应的值,但如果键不存在,则可以返回指定值,如果不指定则返回None。
示例:
# 创建字典
dict = {'name': '小明', 'age': 18}# 使用 item() 方法获取值
try:value = dict['address']
except KeyError as e:print(e)# 使用 get() 方法获取值
value = dict.get('address', '北京')print(value)
输出:
'address' not found in dictionary
北京
总结:
get() 方法是字典对象中一个非常有用的方法,可以用于在键不存在时返回默认值。
其他相关方法:
dict.keys()方法用于获取字典中的所有键。dict.values()方法用于获取字典中的所有值。dict.items()方法用于获取字典中的所有键值对。


答案是 A、append(data)。
解释:
append(data)方法用于将数据添加到列表的末尾。该方法的时间复杂度为 O(1),即与列表长度无关。remove(data)方法用于删除列表中第一个匹配指定值的元素。该方法的时间复杂度为 O(n),即与列表长度成正比。insert(i, data)方法用于在列表中指定位置插入数据。该方法的时间复杂度为 O(n),即与列表长度成正比。pop(i)方法用于删除列表中指定位置的元素。该方法的时间复杂度为 O(n),即与列表长度成正比。
原因分析:
append()方法只需要修改列表的末尾,而不需要遍历列表。因此,它的时间复杂度与列表长度无关,始终为 O(1)。- 其他列表方法,例如
remove()、insert()和pop(),都需要遍历列表才能找到指定位置或元素。因此,它们的时间复杂度与列表长度成正比,为 O(n)。
总结:
在需要向列表末尾添加数据的情况下,append() 方法是效率最高的方法。
以下是一些使用示例:
# 创建列表
list = [1, 2, 3, 4, 5]# 添加元素
list.append(6)# 使用其他方法添加元素
list.insert(1, 0) # 时间复杂度为 O(n)## Python 列表操作:append()、remove()、pop() 和 insert()这四个函数都是 Python 中用于操作列表的常用方法。下面分别解释一下它们的用法和特点:**1. append(data)*** 将数据添加到列表的末尾。
* 时间复杂度为 O(1),即与列表长度无关。
* 用法示例:```python
# 创建列表
list = [1, 2, 3, 4, 5]# 添加元素
list.append(6)print(list) # 输出:[1, 2, 3, 4, 5, 6]
2. remove(data)
- 删除列表中第一个匹配指定值的元素。
- 时间复杂度为 O(n),即与列表长度成正比。
- 用法示例:
# 创建列表
list = ['a', 'b', 'c', 'a', 'd']# 删除元素
list.remove('a')print(list) # 输出:['b', 'c', 'a', 'd']
3. pop(i)
- 删除列表中指定位置的元素。
- 时间复杂度为 O(n),即与列表长度成正比。
- 用法示例:
# 创建列表
list = [1, 2, 3, 4, 5]# 删除元素
element = list.pop(2)print(list) # 输出:[1, 2, 4, 5]
print(element) # 输出:3
4. insert(i, data)
- 在列表中指定位置插入数据。
- 时间复杂度为 O(n),即与列表长度成正比。
- 用法示例:
# 创建列表
list = [1, 2, 3, 4, 5]# 插入元素
list.insert(1, 0)print(list) # 输出:[1, 0, 2, 3, 4, 5]
总结:
append()方法用于在列表末尾添加数据,效率最高。remove()方法用于删除第一个匹配指定值的元素。pop()方法用于删除指定位置的元素。insert()方法用于在指定位置插入数据。

答案是 A、False。
解释:
- 在 Python 中,
in运算符用于检查某个元素是否在序列中。 - 表达式
[3] in [1, 2, 3, 4]表示检查元素[3]是否在列表[1, 2, 3, 4]中。 - 由于
[3]不存在存在于列表[1, 2, 3, 4]中,因此表达式[3] in [1, 2, 3, 4]的值为False。
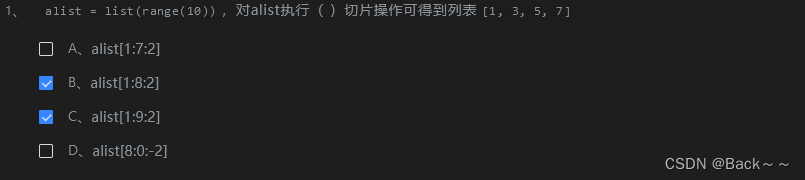
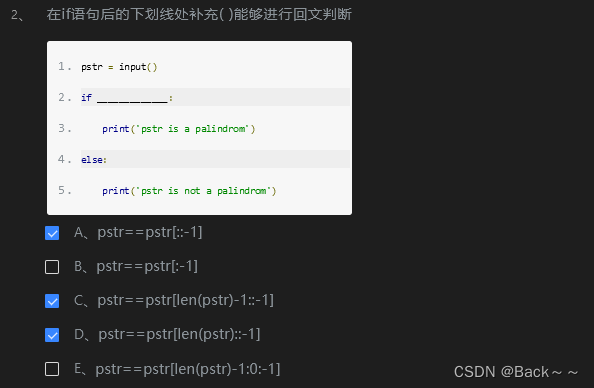
[::-1] 和 [:-1]区别
在 Python 中,[::-1] 和 [:-1] 都是切片操作符,但它们有不同的作用。
1. [::-1]
[::-1]用于对序列进行逆序。- 从序列的开始到结束(不包含结束位置的元素),逆序取值。
示例:
# 对字符串进行逆序
str = 'hello'
print(str[::-1]) # 输出:olleh# 对列表进行逆序
list = [1, 2, 3, 4, 5]
print(list[::-1]) # 输出:[5, 4, 3, 2, 1]
2. [:-1]
[:-1]用于获取序列的所有元素,除了最后一个元素。- 从序列的开始到结束(不包含结束位置的元素),正序取值。
示例:
# 获取字符串的所有元素,除了最后一个元素
str = 'hello'
print(str[:-1]) # 输出:hell# 获取列表的所有元素,除了最后一个元素
list = [1, 2, 3, 4, 5]
print(list[:-1]) # 输出:[1, 2, 3, 4]
总结:
[::-1]用于对序列进行逆序,[:-1]用于获取序列的所有元素,除了最后一个元素。- 两个符号都可以用于任何支持切片操作的序列,包括字符串、列表、元组等。
- 两个符号都不会改变原序列,而是返回一个新的序列。
以下是两个符号的具体区别:
| 区别 | [::-1] | [:-1] |
|---|---|---|
| 作用 | 对序列进行逆序 | 获取序列的所有元素,除了最后一个元素 |
| 取值方向 | 逆序 | 正序 |
| 返回结果 | 新的逆序序列 | 新的包含所有元素(除了最后一个元素)的序列 |
示例:
str = 'hello'# 逆序
print(str[::-1]) # 输出:olleh# 获取所有元素,除了最后一个元素
print(str[:-1]) # 输出:hell
给个示例理解一下
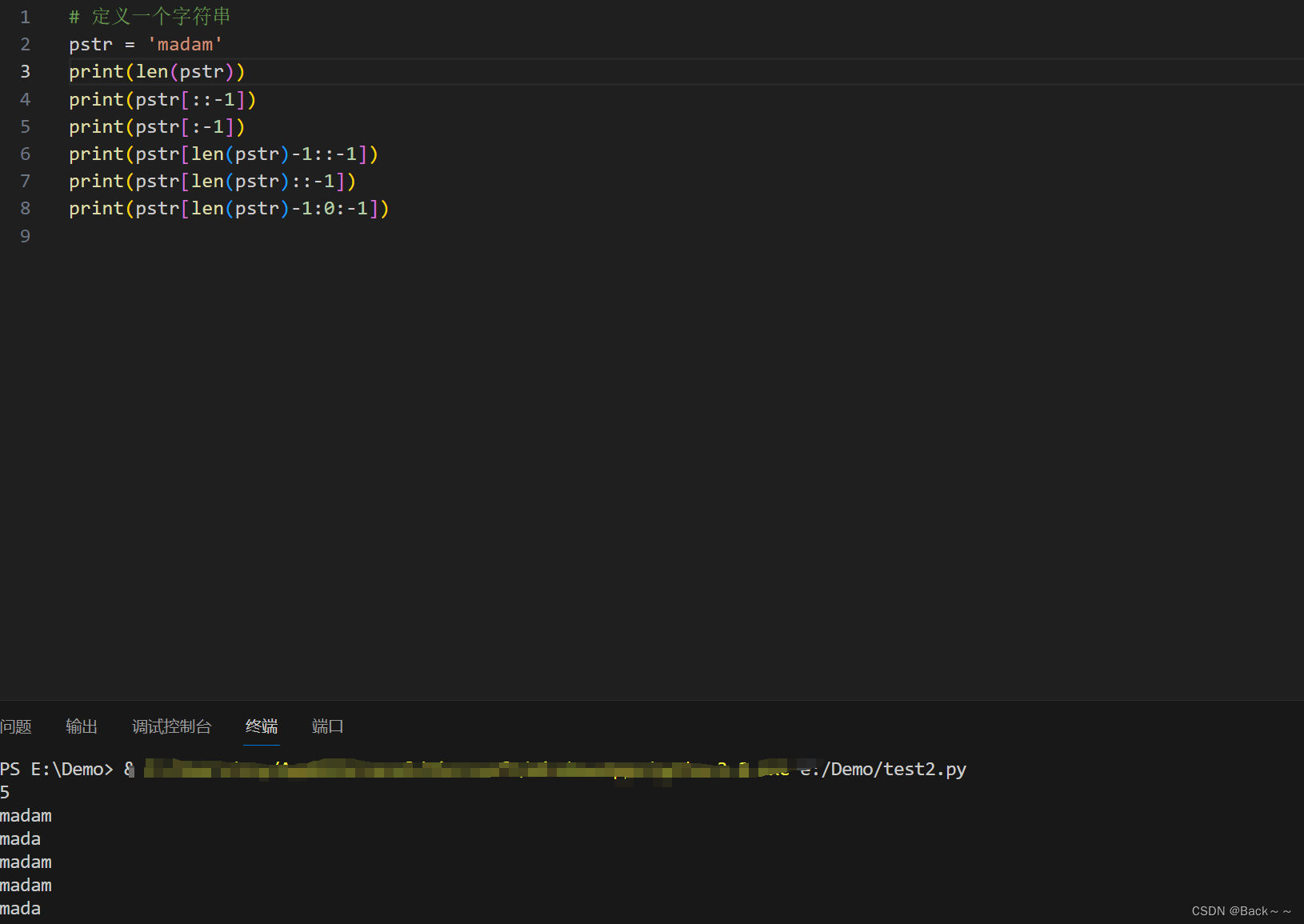

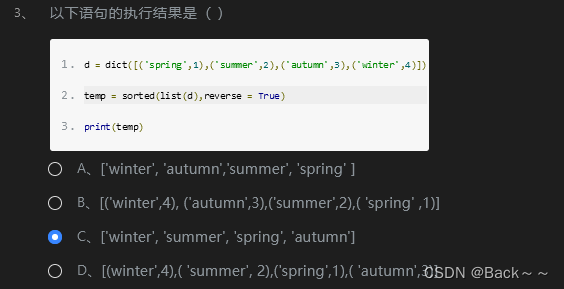
 理解一下看这个https://www.runoob.com/python/att-list-sort.html
理解一下看这个https://www.runoob.com/python/att-list-sort.html
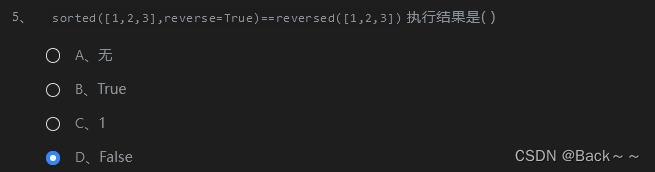
原因:
sorted([1,2,3],reverse=True)会将列表[1, 2, 3]从大到小排序,并返回排序后的 列表[3, 2, 1]。reversed([1,2,3])会返回一个 迭代器,该迭代器会反向迭代列表[1, 2, 3],即[3, 2, 1]。
虽然两者返回的结果相同,但它们的类型不同:
sorted([1,2,3],reverse=True)返回的是 列表。reversed([1,2,3])返回的是 迭代器。
因此,表达式 sorted([1,2,3],reverse=True)==reversed([1,2,3]) 是错误的,因为它们类型不同,即使它们值**相同。
以下是正确的写法:
sorted([1,2,3],reverse=True) == list(reversed([1,2,3]))# True
解释:
list(reversed([1,2,3]))会将迭代器转换为列表,因此它与sorted([1,2,3],reverse=True)返回的列表类型相同。
总结:
表达式 sorted([1,2,3],reverse=True)==reversed([1,2,3]) 是错误的,因为它们类型不同,即使它们值相同。正确的写法是 sorted([1,2,3],reverse=True) == list(reversed([1,2,3])),因为它将迭代器转换为列表,使它们类型相同。
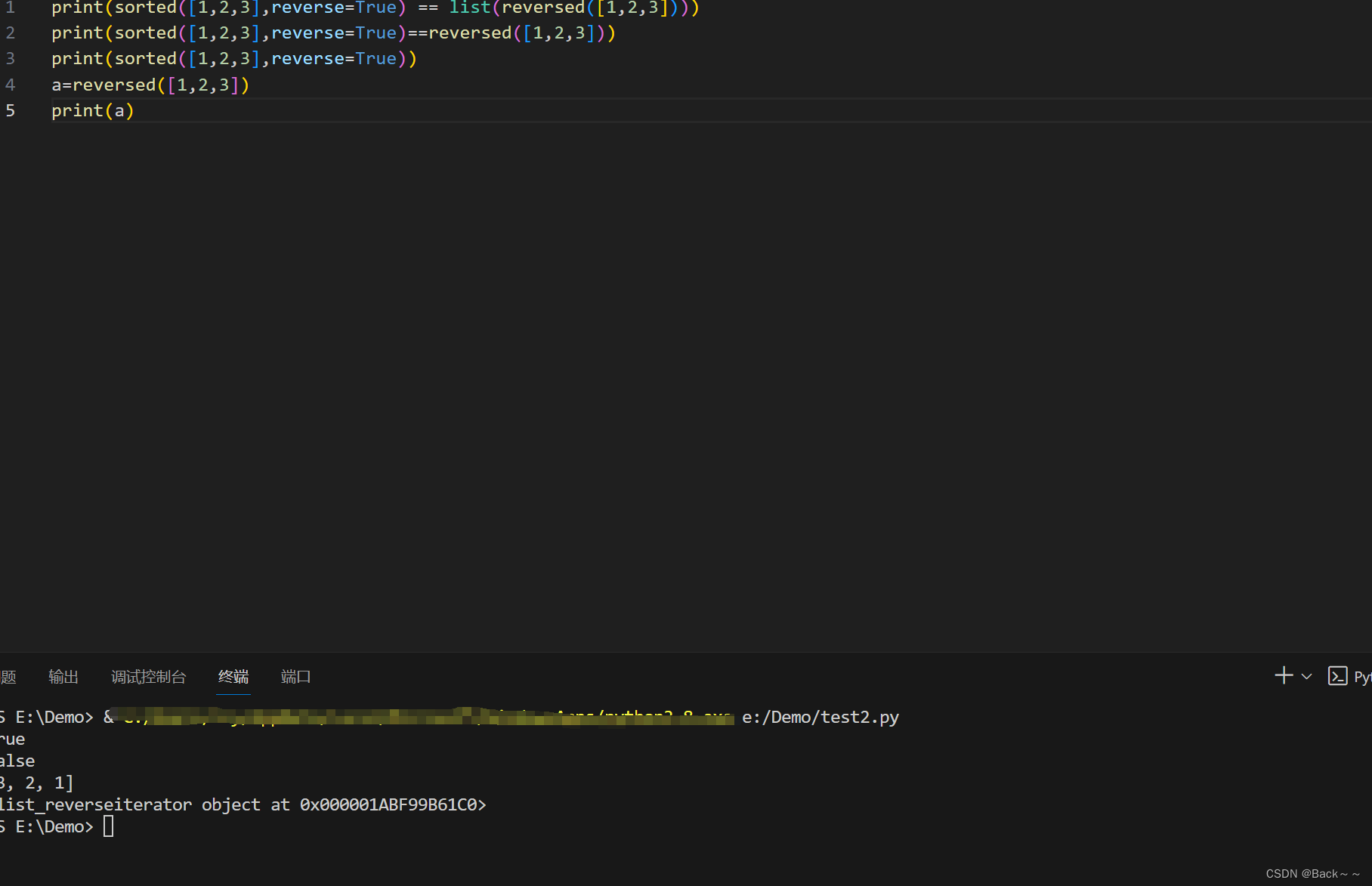 Python 中
Python 中 list_reverseiterator 对象的默认表示。
解释:
list_reverseiterator是 Python 中用于反向迭代列表的迭代器对象。- 当你对一个列表使用
reversed()函数时,它会返回一个list_reverseiterator对象。 list_reverseiterator对象包含指向列表末尾的引用,并会逐个元素反向迭代列表。
默认表示:
- 当你打印一个
list_reverseiterator对象时,它会显示其对象的类型和内存地址。 - 在你的例子中,
0x000001ABF99B61C0是内存地址。
示例:
my_list = [1, 2, 3]# 反向迭代列表
for item in reversed(my_list):print(item)# 输出:
# 3
# 2
# 1# 打印迭代器对象
print(reversed(my_list))# 输出:
# <list_reverseiterator object at 0x000001ABF99B61C0>
总结:
你看到的不是报错,而是 Python 中 list_reverseiterator 对象的默认表示。如果你想查看迭代器中的元素,可以使用 for 循环进行迭代。
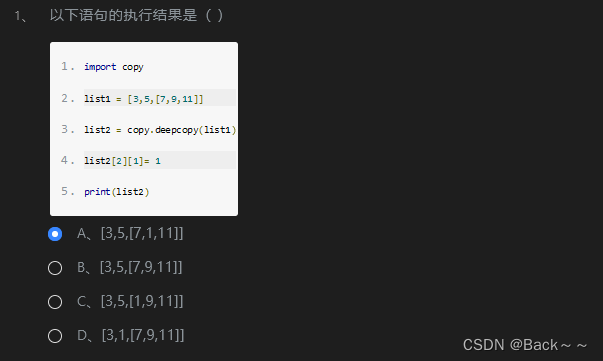
答案是 A、[3, 5, [7, 1, 11]]。
解释:
- 首先,我们导入
copy模块,并创建一个包含三个元素的列表list1:
import copylist1 = [3, 5, [7, 9, 11]]
- 然后,我们使用
copy.deepcopy()函数对list1进行深拷贝,并将其赋值给list2:
list2 = copy.deepcopy(list1)
-
深拷贝意味着
list2中的每个元素都是独立于list1中的对应元素的副本。因此,对list2中的任何元素进行修改都不会影响list1。 -
接下来,我们修改
list2中嵌套列表的第二个元素:
list2[2][1] = 1
- 最后,我们打印
list2:
print(list2)
输出:
[3, 5, [7, 1, 11]]
分析:
- 输出结果表明
list2中嵌套列表的第二个元素已被成功修改为 1。 - 由于使用了深拷贝,
list1中的对应元素保持不变,即仍然为 9。
因此,答案是 A、[3, 5, [7, 1, 11]]。
其他选项的分析:
- B、[3, 5, [7, 9, 11]]:该选项与原始列表
list1相同,未进行任何修改。 - C、[3, 5, [1, 9, 11]]:该选项修改了
list2中嵌套列表的第一个元素,但该元素在代码中并未被修改。 - D、[3, 1, [7, 9, 11]]:该选项修改了
list2的第一个元素,但该元素在代码中并未被修改。
总结:
使用 copy.deepcopy() 函数进行深拷贝可以确保对副本进行的修改不会影响原始对象。
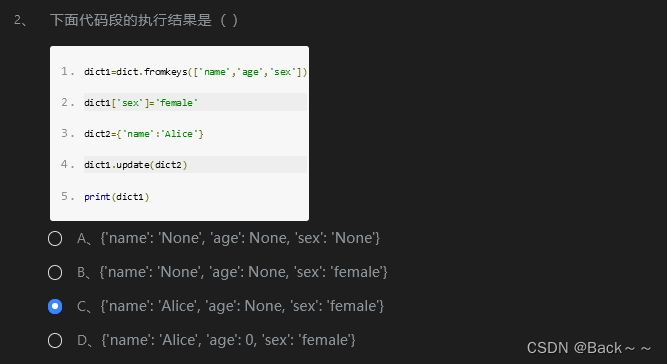
好的,以下是我的中文解释:
代码段:
dict1 = dict.fromkeys(['name', 'age', 'sex'])
dict1['sex'] = 'female'
dict2 = {'name': 'Alice'}
dict1.update(dict2)
print(dict1)
解释:
-
dict1 = dict.fromkeys(['name', 'age', 'sex']):- 使用
dict.fromkeys()函数创建一个字典dict1。 ['name', 'age', 'sex']是包含键的可迭代对象(在本例中是一个列表)。- 可以将可选值作为第二个参数提供,但此处未提供,因此所有键都使用默认值
None。 - 结果:
dict1 = {'name': None, 'age': None, 'sex': None}
- 使用
-
dict1['sex'] = 'female':- 将值
"female"赋值给dict1中的键"sex"。 - 此修改仅影响
dict1,不会影响任何其他字典。 - 结果:
dict1 = {'name': None, 'age': None, 'sex': 'female'}
- 将值
-
dict2 = {'name': 'Alice'}:- 创建一个新的字典
dict2,其中包含键值对{'name': 'Alice'}。
- 创建一个新的字典
-
dict1.update(dict2):- 调用
dict1上的update()方法。 update()将dict2中的键值对合并到dict1中。- 如果
dict1中已存在某个键,则其值将被dict2中的相应值覆盖。 - 结果:
dict1 = {'name': 'Alice', 'age': None, 'sex': 'female'}
- 调用
-
print(dict1):- 打印
dict1的内容。
- 打印
输出:
{'name': 'Alice', 'age': None, 'sex': 'female'}
输出解释:
- 由于
dict2,dict1中键"name"的值从None更新为"Alice"。 - 键
"age"和"sex"保留其之前的值 (None和"female"),因为它们不存在于dict2中。
因此,正确答案是 C. {‘name’: ‘Alice’, ‘age’: None, ‘sex’: ‘female’}.
其他选项的分析:
- A. {‘name’: ‘None’, ‘age’: None, ‘sex’: ‘None’}: 该选项与原始字典
dict1相同,未进行任何修改。 - B. {‘name’: ‘None’, ‘age’: None, ‘sex’: ‘female’}: 该选项仅修改了
dict1中键"sex"的值,但该值在代码中已更新为"female"。 - D. {‘name’: ‘Alice’, ‘age’: 0, ‘sex’: ‘female’}: 该选项修改了
dict1中键"age"的值,但该值在代码中未被修改。
总结:
使用 dict.fromkeys() 函数创建字典时,可以指定键,但默认值将为 None。 使用 update() 方法可以将另一个字典中的键值对合并到现有字典中。
https://zhuanlan.zhihu.com/p/349310163

 对于切片的理解
对于切片的理解
https://zhuanlan.zhihu.com/p/79541418

错误分析:
在代码 for i in range(len(x)-1): 中,range(len(x)-1) 会创建一个从 0 到 len(x)-1 的范围。
问题:
当列表 x 中的所有元素都被删除后,len(x) 会变为 0。
因此,range(len(x)-1) 会创建一个空范围,即 range(0-1)。
结果:
在循环的最后一次迭代中,i 会等于 len(x)-1,即 -1。
因此,x[i] 会访问列表的索引 -1,这会导致 IndexError: list index out of range 错误。
以下是代码的执行过程:
# 创建列表
x = [1, 2, 1, 1, 1, 2]# 遍历列表
for i in range(len(x)-1):# 检查当前元素是否等于 1if x[i] == 1:# 删除当前元素del(x[i])# 打印列表
print(x)
输出:
IndexError: list index out of range
解释:
- 循环的第一个迭代:
- 当前元素
x[0]等于1,因此被删除。 - 列表变为
[2, 1, 1, 1, 2].
- 当前元素
- 循环的第二个迭代:
- 当前元素
x[0]等于2,因此不被删除。 - 循环继续执行。
- 当前元素
- 循环的第三个迭代:
- 当前元素
x[1]等于1,因此被删除。 - 列表变为
[2, 2].
- 当前元素
- 循环继续执行,直到所有元素都被删除。
- 最后,
len(x)变为0。 - 在循环的最后一次迭代中,
i等于len(x)-1,即-1。 - 访问
x[-1]会导致 IndexError: list index out of range 错误。
结论:
由于循环会删除所有元素,最终导致索引越界错误,因此答案是 IndexError: list index out of range。
def sort_and_modify(array):"""对列表进行排序、删除和移动操作,并返回新列表。Args:array: 输入列表。Returns:new_array: 排序、删除和移动后的新列表。"""# 1. 将列表中的元素升序排序array.sort()# 2. 删除列表中的最后一个元素array.pop()# 3. 将列表中第一个元素移动到列表尾部first_element = array.pop(0)array.append(first_element)# 4. 返回新列表new_array = arrayreturn new_array# 测试代码
array = [85,96,2,5,3,566,0,91,5234,5555,89,62,34]
new_array = sort_and_modify(array)
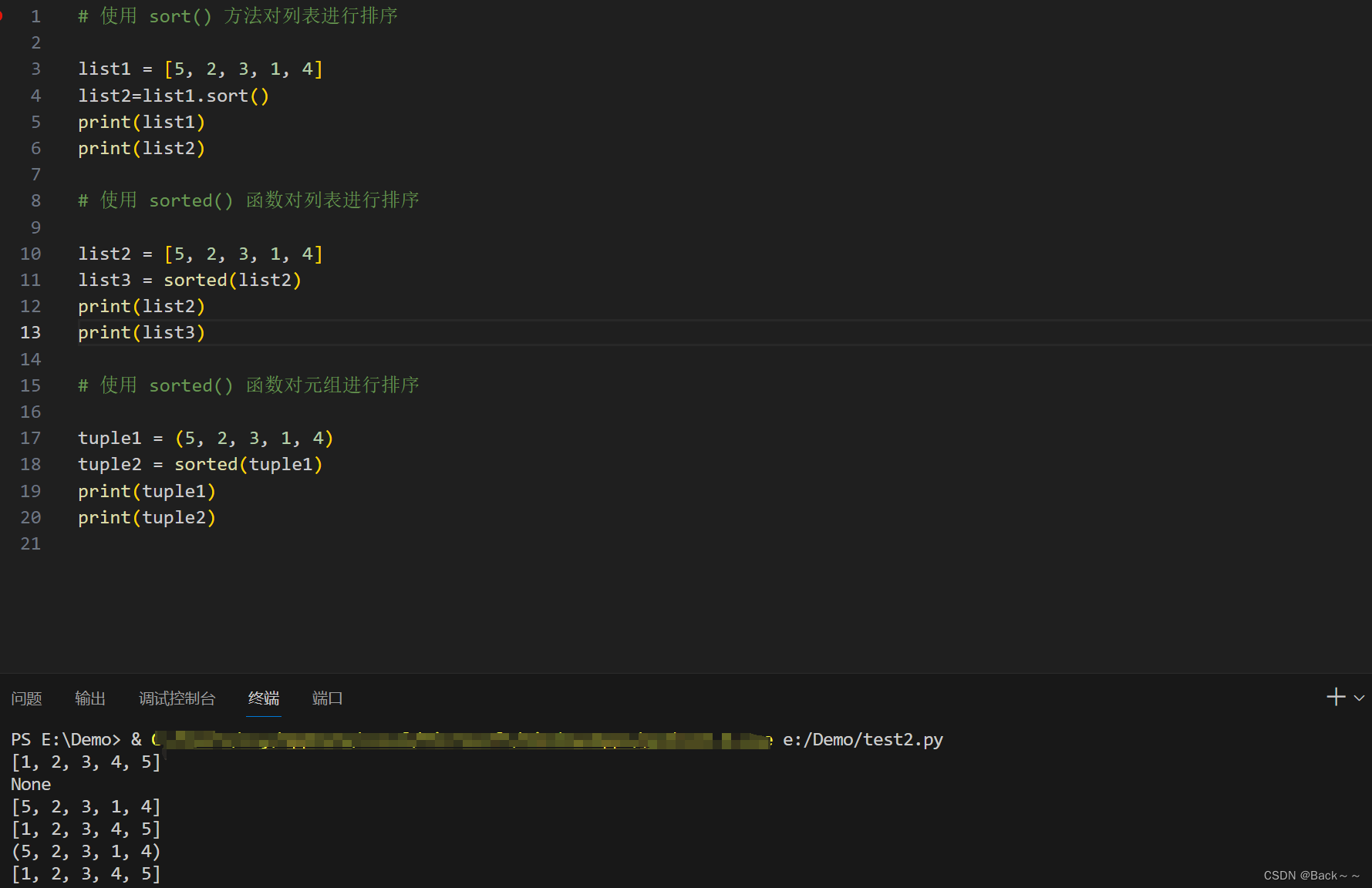
print(new_array)sort()和sorted()在python中,这两的区别
这篇关于python(ch3)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




