本文主要是介绍一个简易的OPC DA组件,其他语言可以通过MQTT来读写OPC服务器上的数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
gitee地址:opc-da-component: 用C#实现的OPC DA 订阅模式,组件使用了MQTT来收发数据,从而使的开发者可以用任意语言通过MQTT来读写OPC SERVER上的数据。 (gitee.com)
欢迎指正,喜欢的可以star。
组件结构
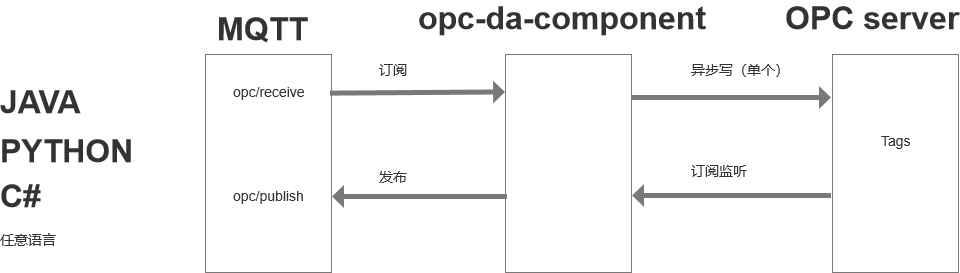 )
)
1、本opc驱动采用订阅模式来读写OPC
2、通过订阅MQTT来接收外部命令以及将读到的数据写出
使用说明:
第一步:安装好MQTT,任意OPC服务器,配置好相应的Tags
本例子假设你已经配置了如下TAG

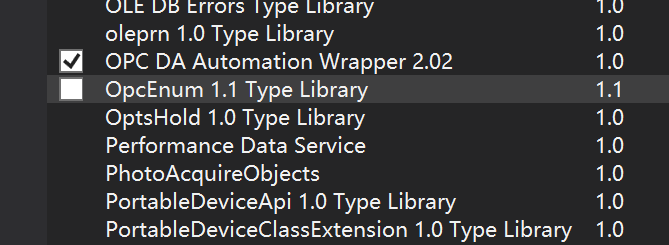
第二步:引用的关键的类库
首先需要把OpcDriver目录下OPCDAAuto.dll放到System32下,然后用管理员运行cmd,
执行 regsvr32 OPCDAAuto.dll 注册,之后通过引用OCM中的OPC DA Automaition Wrapper 来使用。
第三步:项目在运行前,须配置好app.config
<!--mqtt配置-->
<add key="mqtt.url" value="192.168.31.41"/>
<add key="mqtt.clientId" value="opc-1"/>
<add key="mqtt.port" value="1883"/>
<add key="mqtt.topic.opc.receive" value="opc/receive"/> //用来接收外部命令
<add key="mqtt.topic.opc.publish" value="opc/publish"/> //用来写出读到的数据
<!--opc点表配置-->
<add key="opc.serverName" value="Kepware.KEPServerEX.V6"/> //OPC 服务器名,本文用的是kepwareEXV6
<add key="opc.group" value="通道"/> //随便写
<add key="opc.tags" value="通道1.Device2.A1,通道1.Device2.A2"/> //配置标记,每个标记用逗号隔开,必须在opc服务器中找到对应的tag,否则运行时会报异常。
外部语言调用:
1、 **写数据** :向opc/receive 发送以下内容
{"通道1.Device2.A1":1,"通道2.Device2.A2":0}
上面的格式是Map<string,string>, key是点表,value是要写入的值
2、 **读数据** :从opc/publish获取内容
{"通道1.Device2.A1":1,"通道2.Device2.A2":0}
key是点表,value是读到的值
注意、 当程序启动时,会自动读取点表所有的当前值,之后只会在值发生变化时才会读到并自动发送给MQTT
这篇关于一个简易的OPC DA组件,其他语言可以通过MQTT来读写OPC服务器上的数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




