本文主要是介绍HAWQ技术解析(十四) —— 高可用性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、HAWQ高可用简介
HAWQ作为一个传统数仓在Hadoop上的替代品,其高可用性至关重要。通常硬件容错、HAWQ HA、HDFS HA是保持系统高可用时需要考虑并实施的三个层次。另外实时监控和定期维护,也是保证集群所有组件健康的必不可少的工作。总的来说,HAWQ容错高可用的实现方式包括:
- 硬件冗余
- master镜像
- 双集群
1. 硬件级别的冗余(RAID和JBOD)
硬件组件的正常磨损或意外情况最终会导致损坏,因此有必要提供备用的冗余硬件,当一个组件发生损坏时,不中断服务。某些情况下,冗余的成本高于用户所能容忍的服务中断。此时,目标是保证所有服务能够在一个预期的时间范围内被还原。虽然Hadoop集群本身是硬件容错的,但HAWQ有其特殊性。HAWQ master的数据是存储在主机本地硬盘上的,是一个单点。作为最佳实践,HAWQ建议在部署时,master节点应该使用RAID,而segment节点应该使用JBOD。这些硬件级别的系统为单一磁盘损坏提供高性能冗余,而不必进入到数据库级别的容错。RAID和JBOD在磁盘级别提供了低层次的冗余。
2. master镜像
高可用集群中的master节点有两个,一个主一个从。和master节点与segment节点分开部署类似,master的主和从也应该部署到不同的主机,以容忍单一主机失效。客户端连接到主master节点并且查询只能在主master节点上执行。从master节点保持与主master节点的实时同步,这是通过将预写日志从主复制到从实现的。3. 双集群
可以通过部署两套HAWQ集群,存储相同的数据,从而增加另一级别的冗余。有两个主要方法用于保持双集群的数据同步,分别是双ETL和备份/还原。双ETL提供一个与主集群数据完全相同的备用集群。ETL(抽取、装换与装载)指的是一个数据清洗、转换、验证和装载进数据仓库的过程。通过双ETL,将此过程并行执行两次,每次在一个集群中执行。应该在两个集群上都进行验证,以确保双ETL执行成功。这种做法是最彻底的冗余,需要部署两套HAWQ集群与ETL程序。该方法带来的一个附加好处是应用利用双集群,能够同时在两个集群上查询数据,将查询吞吐量增加一倍。
用备份/还原方法维护一个双集群,需要创建一个主集群的备份,并在备用集群上还原。这种方法与双ETL策略相比,备用节点数据同步的时间要长的多,但优点是只需要开发更少的应用逻辑。如果数据修改和ETL执行的频率是每天或更低的频率,同时备份/还原时间又在可接受的范围内,那么用备份生成数据是比较理想的方式。注意,备份/还原方法不适用于要求数据实时同步的情况。
二、master节点镜像
在HAWQ中配置一主一从两个master节点,客户端连接点主master节点,并只能在主master节点上执行查询。从master是一个纯粹的容错节点,只作为主master出现问题时的备用。如果主master节点不可用,从master节点作为热备。可以在主master节点联机时,从它创建一个从master节点。当主master节点持续为用户提供服务时,HAWQ可以生成主master节点实例的事务快照。除了生成事务快照并部署到从master节点外,HAWQ还记录主master节点的变化。在HAWQ在从master节点部署了快照后,HAWQ会应用更新以将从master节点与主master节点数据同步。
主从master节点初始同步后,HAWQ分别在主、从节点上启动WAL Send和WAL Redo服务器进程,保持主从实时同步。它们是基于预写日志(Write-Ahead Logging,WAL)的复制进程。WAL Redo是一个从master节点进程,WAL Send是主master节点进程。这两个进程使用基于WAL的流复制保持主从同步。
因为master节点不保存用户数据,只有系统目录表在主从master节点间被同步。当这些系统表被更新时(如DDL所引起),改变自动拷贝到从master节点保持它与当前的主master节点数据一致。
HAWQ中的master节点镜像架构如图1所示。

图1
如果主master节点失效,复制进程停止。此时管理员需要使用命令行工具或者Ambari,手工执行master切换,指示从master节点成为新的主master节点。在激活从master节点后,复制的日志重构主master节点在最后成功提交事务时的状态。当从master节点初始化后,被激活的从作为HAWQ的主节点,在指定端口接收连接请求。
可以为主、从配置同一个虚IP地址,这样在主从切换时,客户端程序就不需要连接到两个不同的网络地址。如果主机失效,虚IP可以自动交换到实际活动的主节点。虚IP可能需要额外的软件支持,如Keepalived等。
1. 配置从master节点
hdp2为现有的主master节点,下面过程将hdp3配置为hdp2的从master节点。(1)前提配置
确保hdp3上已经安装了HAWQ并进行了以下配置:
- 创建了gpadmin系统用户。
- 已安装了HAWQ二进制包。
- 已设置了HAWQ相关的环境变量。
- 已配置主、从master的SSH免密码登录。
- 已创建了master数据目录。
登录hdp3,清空master数据目录。
[root@hdp3 ~]# rm -rf /data/hawq/master/*[gpadmin@hdp2 ~]$ . /usr/local/hawq/greenplum_path.sh
[gpadmin@hdp2 ~]$ hawq init standby -s hdp3(3)检查HAWQ集群状态
- 通过在hdp2上执行下面的命令检查HAWQ集群的状态,结果如图2所示。主master状态应该是Active,从master状态是Passive。
[gpadmin@hdp2 ~]$ hawq state
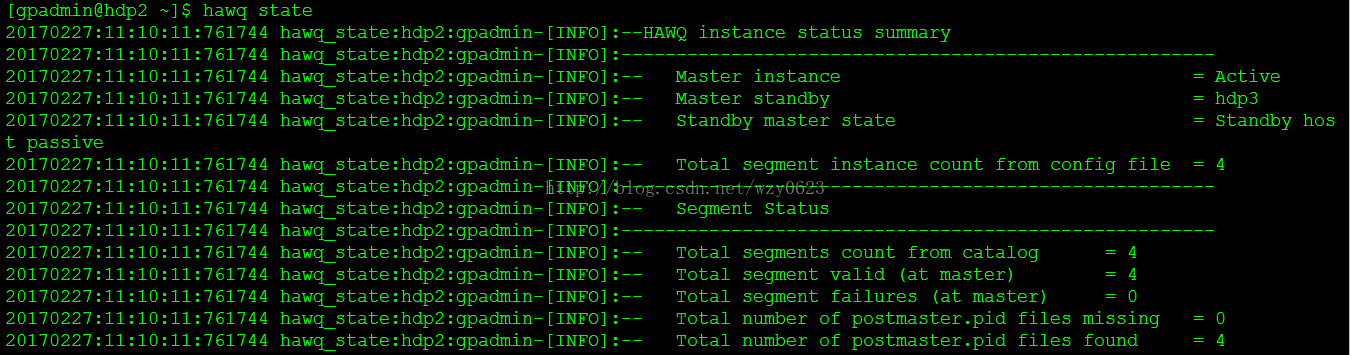
图2
- 查询gp_segment_configuration表验证segment已经注册到主master节点,查询结果如图3所示,可以看到hdp2与hdp3的角色分别是‘m’和‘s’。
[gpadmin@hdp2 ~]$ psql -c 'SELECT * FROM gp_segment_configuration;'
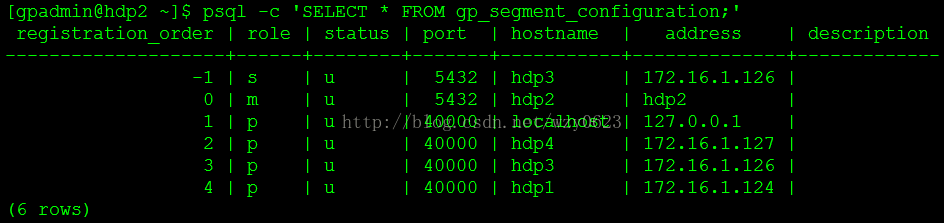
图3
- 查询gp_master_mirroring系统视图检查主节点镜像的状态。该视图提供了关于HAWQ master节点的WAL Send进程的使用信息。查询结果如图4所示,可以看到主、从master数据已经同步。
[gpadmin@hdp2 ~]$ psql -c 'SELECT * FROM gp_master_mirroring;'

图4
2. 手工执行失败切换
当主master不可用时,需要手工执行切换,将从master激活为主master。(1)保证系统中已经配置从master节点主机。
(2)激活从master节点。
登录到HAWQ从master节点并激活它,之后从master成为了HAWQ的主master。
[gpadmin@hdp3 ~]$ hawq activate standby3. 配置一个新的从master节点(可选但推荐)
手工切换master后,最好配置一个新的从master节点,继续保持master的高可用性,配置过程参考“1. 配置从master节点”。4. 重新同步主、从节点
如果主、从之间的日志同步进程停止或者落后,从master可能变成过时状态。如果遇到这种情况,查询gp_master_mirroring视图时,会看到summary_state字段输出中显示Not Synchronized。为了将从与主重新进行同步,在主master节点上执行下面的命令:[gpadmin@hdp3 ~]$ hawq init standby -n三、HAWQ文件空间与HDFS高可用
如果在初始化HAWQ时没有启用HDFS的高可用性,可以使用下面的过程启用它。- 配置HDFS集群高可用性。
- 收集目标文件空间的信息。
- 停止HAWQ集群,并且备份系统目录。
- 使用命令行工具迁移文件空间。
- 重新配置${GPHOME}/etc/hdfs-client.xml和${GPHOME}/etc/hawq-site.xml,然后同步更新所有HAWQ节点的配置文件。
- 启动HAWQ集群,并在迁移文件空间后重新同步从master节点。
1. 配置HDFS集群高可用性
(1)HDFS HA概述HDFS中的NameNode非常重要,其中保存了DataNode上数据块存储位置的相关关系。它主要维护两个映射,一个是文件到块的对应关系,一个是块到节点的对应关系。如果NameNode停止工作,就无法知道数据所在的位置,整个HDFS将陷入瘫痪,因此保证NameNode的高可用性是非常重要的。
在Hadoop 1时代,只有一个NameNode。如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。这是hadoop 1中的单点故障问题,也是hadoop 1不可靠的表现。图5是hadoop 1的架构图。
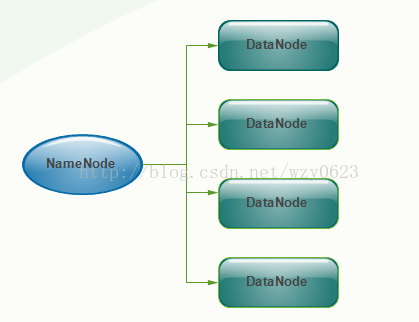
图5
为了解决hadoop 1中的单点问题,hadoop 2中支持两个NameNode,每一个都有相同的职能。一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode处于待命状态,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,将standby状态的NameNode转变为active状态,就可以继续工作了。
Hadoop 2中,两个NameNode的数据是实时共享的。新HDFS采用了一种共享机制,通过Quorum Journal Node(JournalNode)集群或者Network File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的(主流做法)。图6为JournalNode的架构图。

图6
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就可能产生分歧,或造成数据丢失,或产生错误的结果。为了保证这点,需要利用ZooKeeper。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,然后它就会自动把standby状态的NameNode切换为active状态。
(2)使用Ambari启用HDP的高可用性(参考 How To Configure NameNode High Availability)。
- 检查Hadoop集群,确保集群中至少有三台主机,并且至少运行三个ZooKeeper服务器。
- 检查Hadoop集群,确保HDFS和ZooKeeper服务不是在维护模式中。在启用NameNode HA时,这些服务需要重启,而维护模式阻止启动和停止。如果HDFS或者ZooKeeper服务处于维护模式,NameNode HA向导将不能完全成功。
- 在Ambari Web里,选择Services > HDFS > Summary。
- 在Service Actions中选择Enable NameNode HA,如图7所示。
图7
出现Enable HA向导。这个向导描述了配置NameNode高可用必须执行的自动和手工步骤。Get Started:此步骤给出一个处理预览,并允许用户选择一个Nameservice ID,本例的Nameservice ID为mycluster。HA一旦配置好,就需要使用Nameservice ID代替NameNode FQDN。点击Next继续处理,如图8所示。

图8
- Select Hosts:为standby NameNode和JournalNodes选择主机。可以使用下拉列表调整向导建议的选项。点击Next继续处理。
- Review:确认主机的选择,并点击Next,如图9所示。
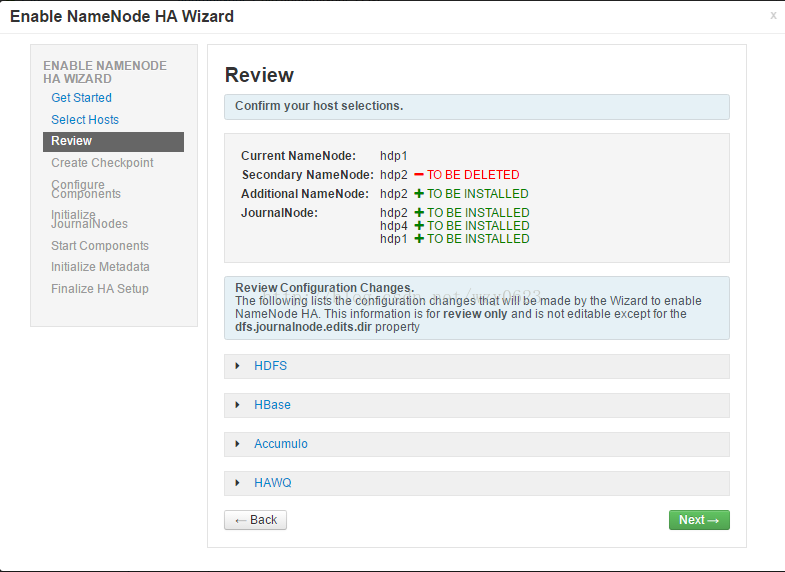
图9
创建检查点:此步骤中提示执行两条命令,第一条命令把NameNode置于安全模式,第二条命令创建一个检查点,如图10所示。需要登录当前的NameNode主机执行这两条命令,如图11所示。当Ambari检测到命令执行成功后,窗口下端的提示消息将改变。点击Next。
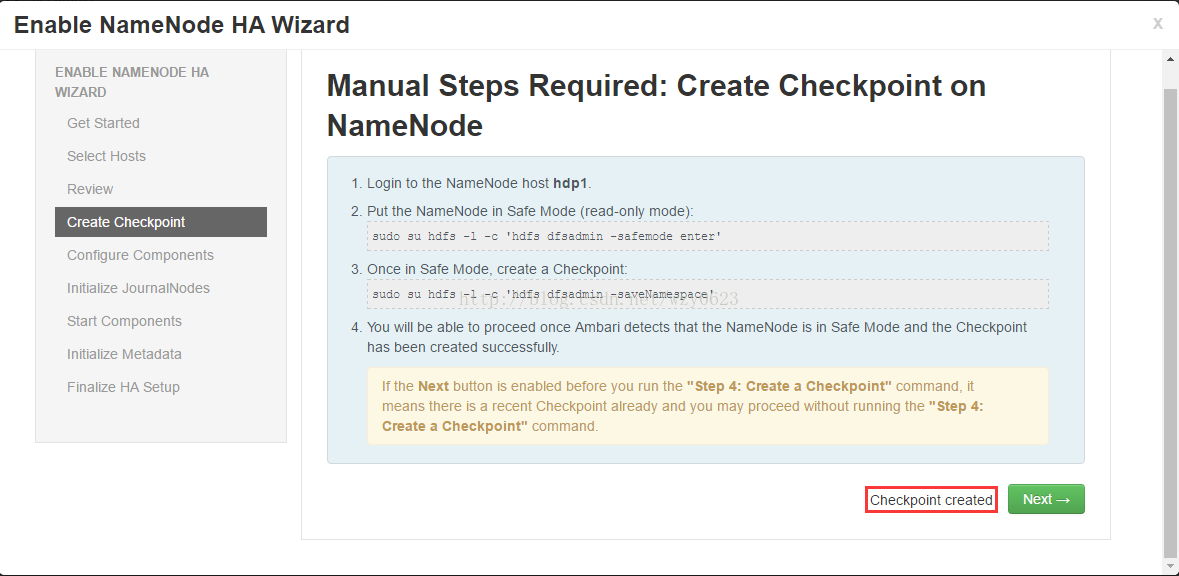
图10

图11
确认组件:向导开始配置相关组件,显示进度跟踪步骤。配置成功如图12所示。点击Next继续。
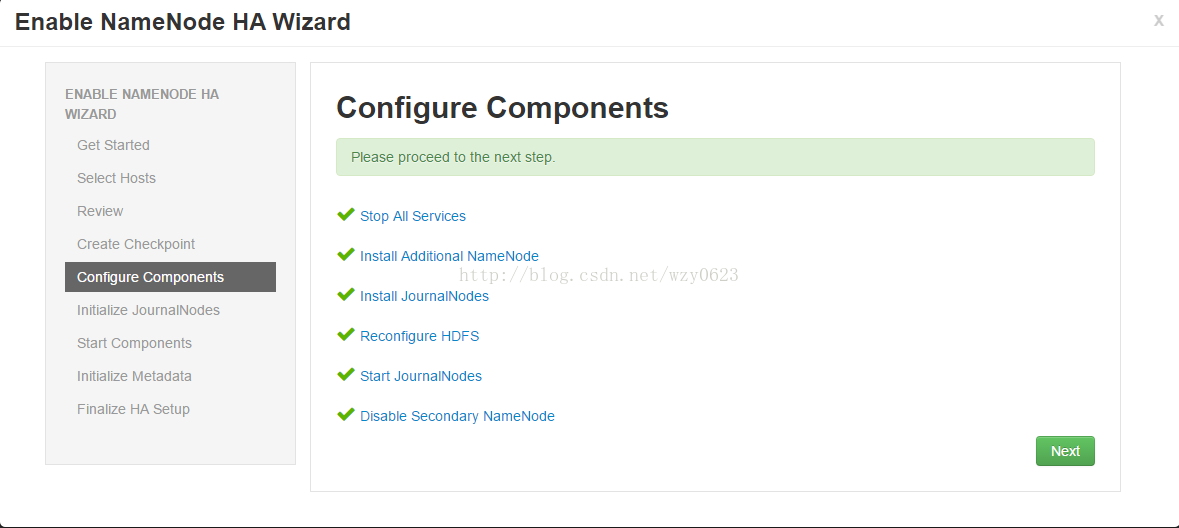
图12
- 初始化JournalNodes:此步骤中提示执行一条指令,如图13所示。需要登录到当前的NameNode主机运行命令初始化JournalNodes。当Ambari检测成功,窗口下端的提示消息将改变。点击Next。
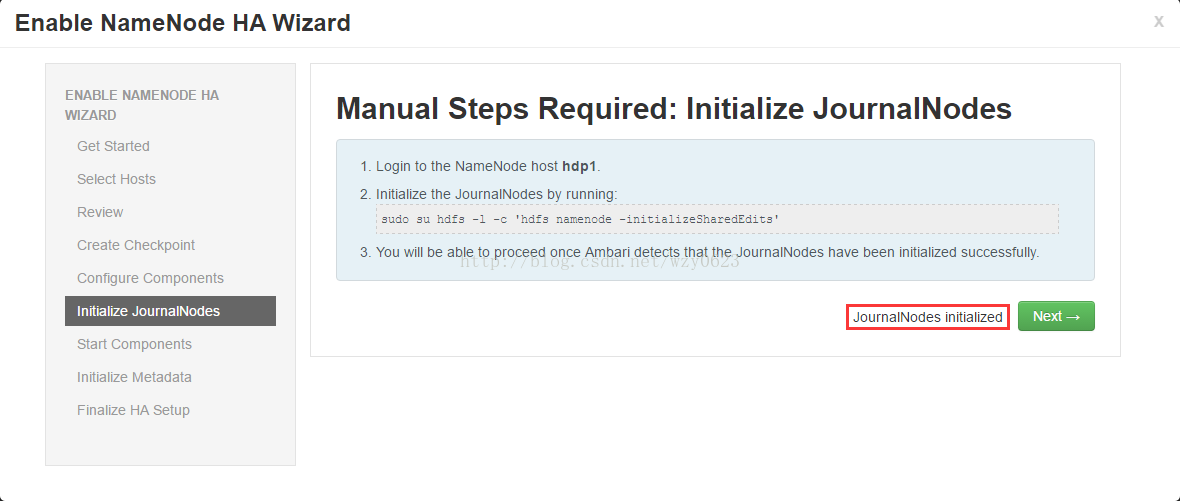
图13
启动组件:向导启动ZooKeeper服务器和NameNode,显示进度以跟踪步骤。执行成功后如图14所示。点击Next继续。

图14
- 初始化元数据:此步骤中根据提示执行命令。确保登录正确的主机(主、从NameNode)执行每个命令。当完成了两个命令,点击Next。显示一个弹出窗口,提醒用户确认已经执行了两个命令。点击OK确认。
- 最终设置:此步骤中,向导显示进度跟踪步骤。点击Done结束向导。在Ambari Web GUI重载后,可以看到一些警告提示。等待几分钟直到服务恢复。如果需要,使用Ambari Web重启相关组件。
- 调整ZooKeeper失败切换控制器的重试次数设置。浏览Services > HDFS > Configs > Advanced core-site,设置ha.failover-controller.active-standby-elector.zk.op.retries=120

图15
图16
此时在hdp1上执行如下命令关闭hdp1上的NameNode:[hdfs@hdp1 ~]$ /usr/hdp/2.5.0.0-1245/hadoop/sbin/hadoop-daemon.sh stop namenode
stopping namenode
[hdfs@hdp1 ~]$
图17
此时在hdp1上执行如下命令启动hdp1上的NameNode:[hdfs@hdp1 ~]$ /usr/hdp/2.5.0.0-1245/hadoop/sbin/hadoop-daemon.sh start namenode
stopping namenode
[hdfs@hdp1 ~]$
图18
2. 收集目标文件空间的信息
缺省的文件空间名为dfs_system,存在于pg_filespace目录,其参数pg_filespace_entry包含每个文件空间的细节信息。为了将文件空间位置迁移到HDFS HA的位置,必须将数据迁移到集群中新的HDFS HA路径。使用下面的SQL查询收集关于HDFS上的文件空间位置信息。
SELECTfsname, fsedbid, fselocation
FROMpg_filespace AS sp, pg_filespace_entry AS entry, pg_filesystem AS fs
WHEREsp.fsfsys = fs.oid AND fs.fsysname = 'hdfs' AND sp.oid = entry.fsefsoid
ORDER BYentry.fsedbid;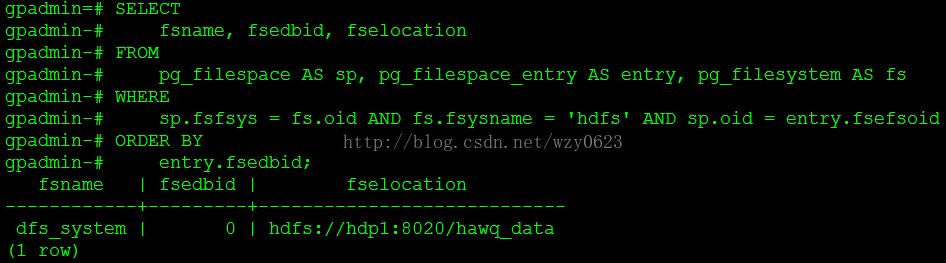
图19
为了在HAWQ中使用HDFS HA,需要文件空间名和HDFS路径的通用前缀信息。文件空间位置的格式类似一个URL。如果无HA的文件空间位置是‘hdfs://test5:9000/hawq/hawq-1459499690’,并且HDFS HA的通用前缀是‘hdfs://hdfs-cluster’,那么新的文件空间位置应该是‘hdfs://hdfs-cluster/hawq/hawq-1459499690’。3. 停止HAWQ集群并备份系统目录
注意:Ambari用户必须手工执行这个步骤。在HAWQ中启用 HDFS HA时会修改HAWQ的目录和永久表。因此迁移文件空间位置前,先要备份目录,以确保不会因为硬件失效或在一个操作期间(如杀掉HAWQ进程)丢失数据。
(1)如果HAWQ主节点使用了一个定制端口,输出PGPORT环境变量。例如:
export PGPORT=8020export MDATA_DIR=/data/hawq/master[gpadmin@hdp3 ~]$ psql -c "SELECT * FROM pg_catalog.pg_stat_activity"[gpadmin@hdp3 ~]$ psql -c "CHECKPOINT"[gpadmin@hdp3 ~]$ hawq stop cluster -a -M fast$ cp -r ${MDATA_DIR} /catalog/backup/location4. 迁移文件空间位置
注意:Ambari用户必须手工执行这个步骤。HAWQ提供了命令行工具hawq filespace,迁移文件空间的位置。(1)如果HAWQ主节点使用了一个定制端口,输出PGPORT环境变量。例如:
export PGPORT=9000[gpadmin@hdp3 master]$ hawq filespace --movefilespace default --location=hdfs://mycluster/hawq_data- 如果提供了无效的输入,或者在修改文件空间位置时没有停止HAWQ,可能发生非崩溃错误。检查是否已经从头正确执行了所有步骤,或者在再次执行hawq filespace前修正输入错误。
- 崩溃错误可能发生在硬件失效或者修改文件空间位置时杀死HAWQ进程失败的情况下。当发生崩溃错误时,在输出中可以看到“PLEASE RESTORE MASTER DATA DIRECTORY”消息。此时应该停止数据库,并且还原在步骤4中备份的${MDATA_DIR}目录。
5. 通过重新配置hdfs-client.xml和hawq-site.xml,更新HAWQ使用NameNode HA
如果使用命令行应用安装和管理HAWQ集群,参考 http://hawq.incubator.apache.org/docs/userguide/2.1.0.0-incubating/admin/HAWQFilespacesandHighAvailabilityEnabledHDFS.html#configuregphomeetchdfsclientxml,修改HAWQ配置以使用NameNode HA服务。如果使用Ambari管理HDFS和HAWQ,不需要执行这些步骤,因为Ambari在启用了NameNode HA后会自动做这些修改。
6. 重启HAWQ集群并重新同步从主节点
(1)重启HAWQ集群[gpadmin@hdp3 master]$ hawq start cluster -a[gpadmin@hdp3 master]$ hawq init standby -n -M fast
图20
四、理解HAWQ容错服务
HAWQ的容错服务(fault tolerance service,FTS)使得HAWQ可以在segment节点失效时持续操作。容错服务自动运行,并且不需要额外的配置。每个segment运行一个资源管理进程,定期(缺省每30秒)向主节点的资源管理进程发送segment状态。这个时间间隔由hawq_rm_segment_heartbeat_interval服务器配置参数所控制。当一个segment碰到严重错误,例如,由于硬件问题,segment上的一个临时目录损坏,segment通过心跳报告向master节点报告有一个临时目录损坏。master节点接收到报告后,在gp_segment_configuration表中将该segment标记为DOWN。所有segment状态的变化都被记录到gp_configuration_history目录表,包括segment被标记为DOWN的原因。当这个segment被置为DOWN,master节点不会在该segment上运行查询执行器。失效的segment与集群剩下的节点相隔离。
包括磁盘故障的其它原因会导致一个segment被标记为DOWN。举例来说,HAWQ运行在YARN模式中,每个segment应该有一个运行的NodeManager(Hadoop的YARN服务),因此segment可以被看做HAWQ的一个资源。但如果segment上的NodeManager不能正常操作,那么该segment会在gp_segment_configuration表中被标记为DOWN。失效对应的原因被记录进gp_configuration_history。
注意:如果一个特定段上的磁盘故障,可能造成HDFS错误或HAWQ中的临时目录错误。HDFS的错误由Hadoop HDFS服务所处理。
查看segment的当前状态
为了查看当前segment的状态,查询gp_segment_configuration表。如果segment的状态是DOWN,“description”列显示原因。原因可能包括下面的任何原因,可能是单一原因,也可能是以分号(“;”)分割的几个原因。原因:heartbeat timeout
主节点没有接收到来自段的心跳。如果看到这个原因,确认该segment上的HAWQ是否运行。如果segment在以后的时间报告心跳,segment被自动标记为UP。
原因:failed probing segment
master节点探测segment以验证它是否能被正常操作,段的响应为NO。在一个HAWQ实例运行时,查询分发器发现某些segment上的查询执行器不能正常工作。master节点上的资源管理器进程向这个segment发送一个消息。当segment的资源管理器接收到来自master节点的消息,它检查其PostgreSQL的postmaster进程是否工作正常,并且向master节点发送一个响应消息。当master节点收到的响应消息表示该segment的postmaster进程没有正常工作,那么master节点标记段为DOWN,原因记为“failed probing segment.”。检查失败segment的日志并且尝试重启HAWQ实例。
原因:communication error
master节点不能连接到segment。检查master节点和segment之间的网络连接。
原因: resource manager process was reset
如果segment资源管理器进程的时间戳与先前的时间戳不匹配,意味着segment上的资源管理器进程被重启过。在这种情况下,HAWQ master节点需要回收该segment上的资源并将其标记为DOWN。如果master节点从该segment接收到一个新的心跳,它会自动标记为UP。
原因:no global node report
HAWQ使用YARN管理资源,但没有为该segment接收到集群报告。检查该segment上的NodeManager是否可以正常操作。如果不能,尝试启动该segment上的NodeManager。在NodeManager启动后,运行yarn node --list查看该节点是否在列表中。如过存在,该段被自动置为UP。
这篇关于HAWQ技术解析(十四) —— 高可用性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





