本文主要是介绍tongweb生成hprof文件并结合Memory Analyzer Mat分析内存溢出(by lqw),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是堆
JVM中的堆(Heap)是Java虚拟机管理的内存中的一部分,它用于存储所有的Java对象实例。堆内存被所有线程共享,其目的是为了存放对象实例和数组。
堆的大小在JVM启动时就已经设定好了,大家可以通过选项 “-Xmx” 和 "-Xms"来进行设置。
- “-Xms” 用于表示堆区的起始内存,等价于 -xx:InitialHeapSize。
- “-Xmx” 用于表示堆区的最大内存,等价于 -xx:MaxHeapSize。
一旦堆区中的内存大小超过"-xmx"所制定的最大内存时,将会抛出outofMemoryError异常。
通常会将-Xms 和 -Xmx两个参数配置相同的值,其目的是为了能够在Java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小,从而提高性能。
默认情况下:
- 初始内存大小:物理电脑内存大小/64
- 最大内存大小:物理电脑内存大小/4
什么是年轻代和老年代
堆内存按照对象的生命周期进行划分为几个区域:
-
年轻代(Young Generation):新创建的对象首先被分配在年轻代。年轻代包含Eden区以及两个幸存区(Survivor spaces,通常简称S0和S1)。
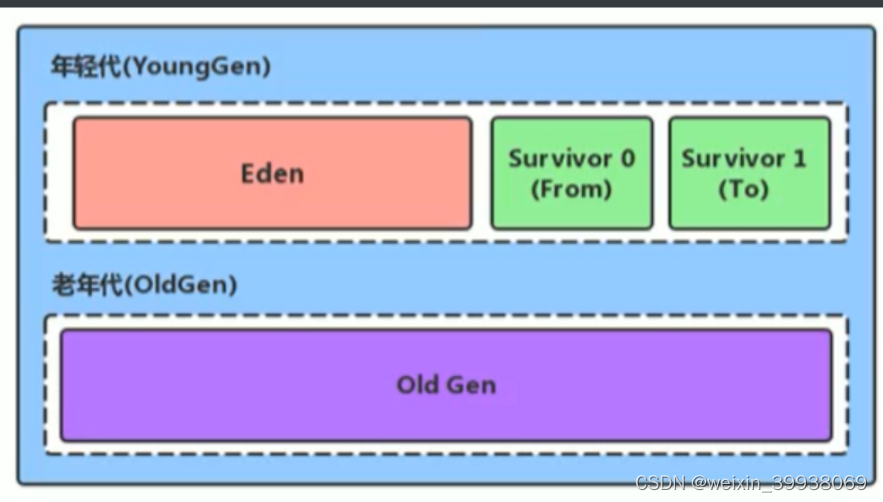
-
老年代(Old Generation):对象在年轻代中存活了一定的垃圾收集循环后,如果还没有被回收,那么会被移动到老年代。老年代的大小通常远大于年轻代,并且垃圾回收在老年代中发生的频率较低。
-
永久代/元数据空间(Metaspace):JDK 8开始使用元数据空间代替了永久代,这部分用于存储类的元数据信息。它位于堆外内存(native memory)。
堆的大小和垃圾收集的方式直接影响了Java程序的性能。垃圾收集器会自动管理堆内存,回收不再使用的对象所占用的空间,从而避免内存泄露。通过使用jstat命令,开发者可以监控并调整堆的大小和监控垃圾收集的性能,以优化Java应用的效率。
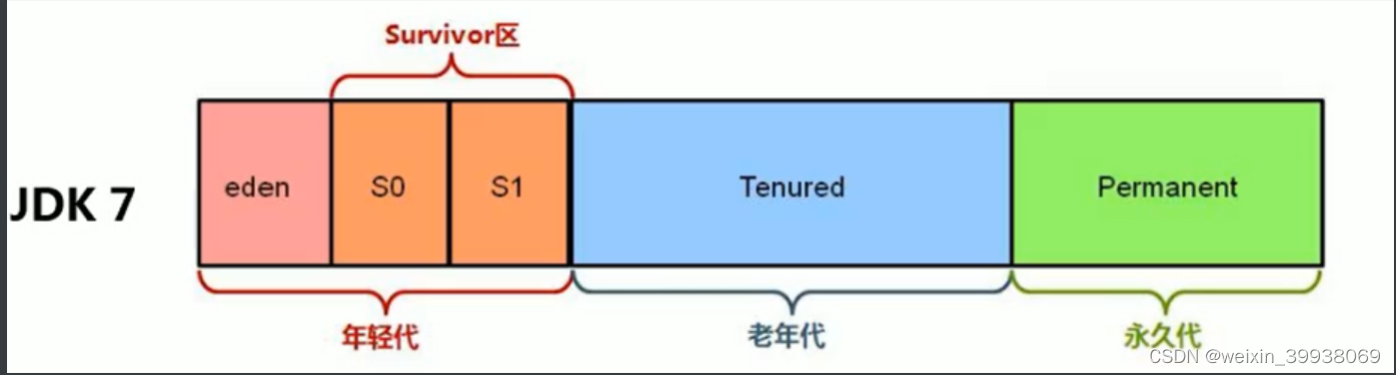
Java7及之前堆内存在逻辑上分为三部分:新生区 + 养老区 + 永久区
- Young Generation Space 新生区 Young/New 又被划分为Eden区和Survivor区
- Tenure generation space 养老区 Old/Tenure
- Permanent Space 永久区 Perm
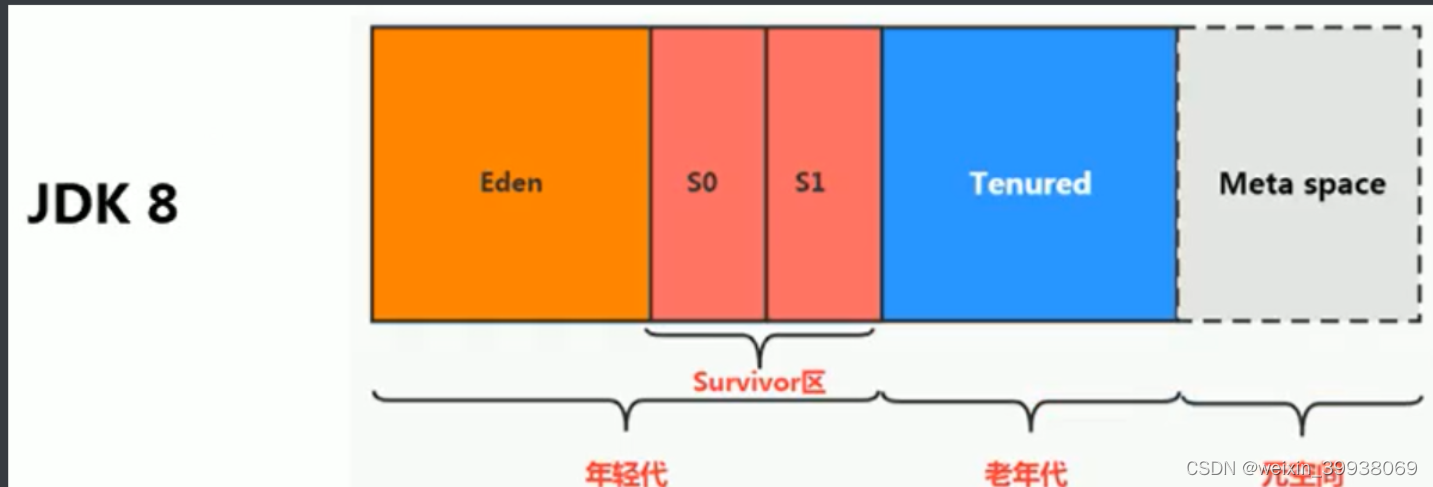
Java 8及之后堆内存逻辑上分为三部分:新生区 + 养老区 + 元空间
- Young Generation Space 新生区 Young/New 又被划分为Eden区和Survivor区
- Tenure generation space 养老区 Old/Tenure
- Meta Space 元空间 Meta
约定:新生区 -> 新生代 -> 年轻代 、 养老区 -> 老年区 -> 老年代、 永久区 -> 永久代
堆内存区域
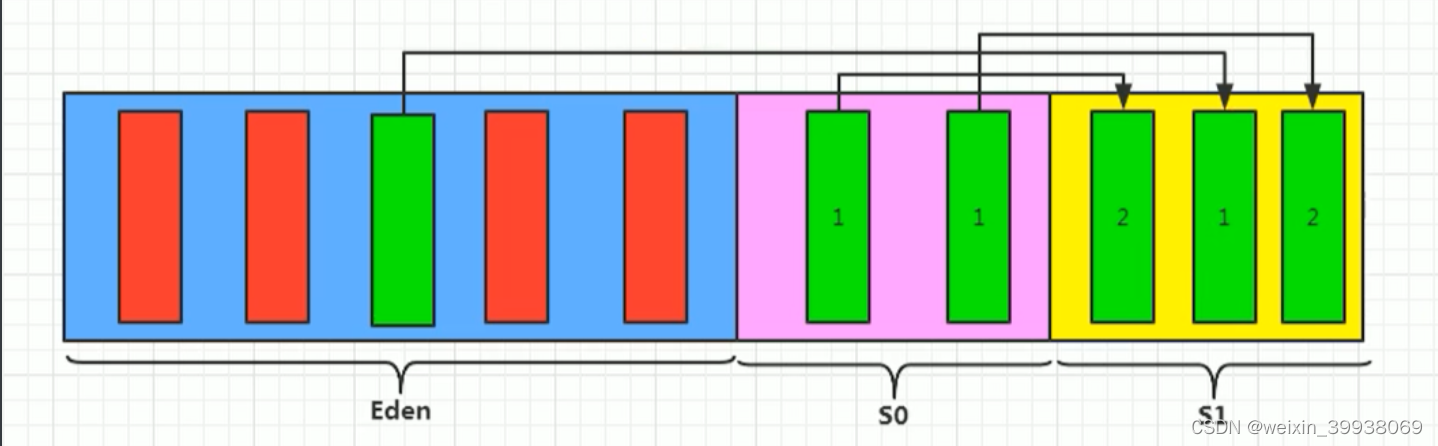
我们创建的对象,一般都是存放在Eden区的,当我们Eden区满了后,就会触发GC操作,一般被称为YGC/Minor GC 操作.
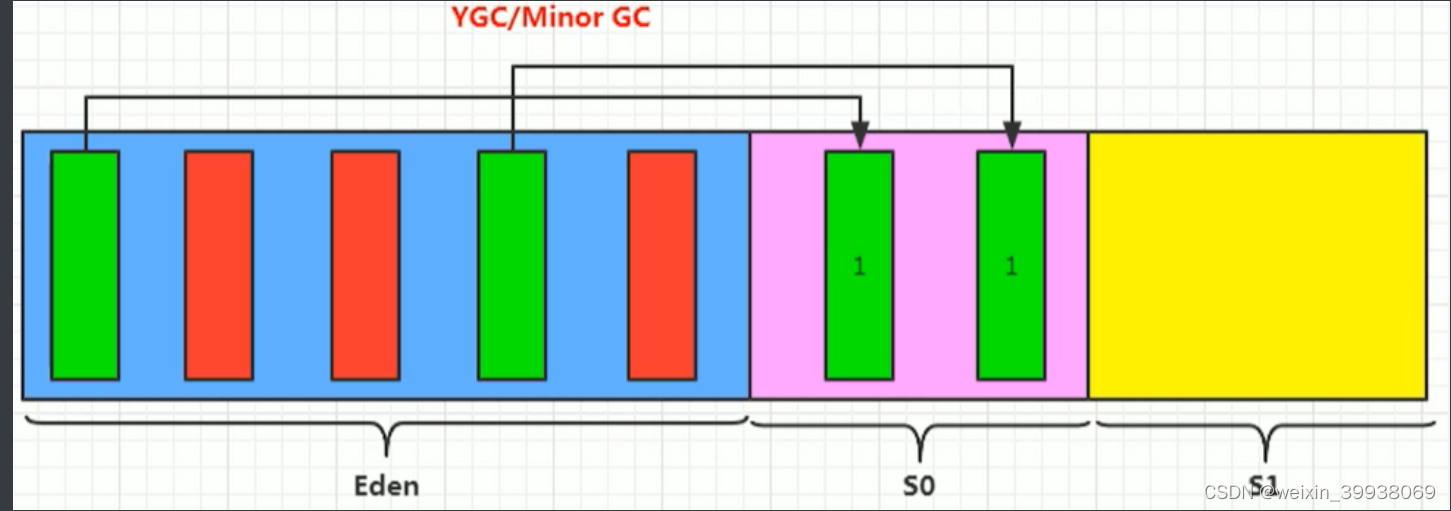
当我们进行一次垃圾收集后,红色的将会被回收,而绿色的还会被占用着,存放在S0(Survivor From)区。同时我们给每个对象设置了一个年龄计数器,一次回收后就是1。
同时Eden区继续存放对象,当Eden区再次存满的时候,又会触发一个MinorGC操作,此时GC将会把 Eden和Survivor From中的对象 进行一次收集,把存活的对象放到 Survivor To区,同时让年龄 + 1。
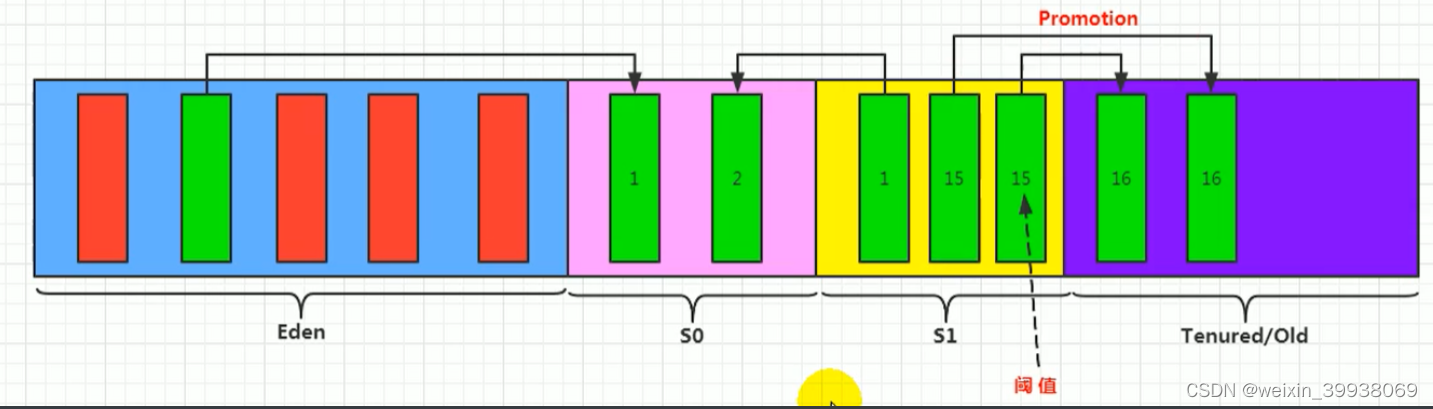
我们继续不断的进行对象生成 和 垃圾回收,当Survivor中的对象的年龄达到15的时候,将会触发一次 Promotion晋升的操作,也就是将年轻代中的对象 晋升到 老年代中。
为什么会发生oom
我们都知道,JVM的调优的一个环节,也就是垃圾收集,我们需要尽量的避免垃圾回收,因为在垃圾回收的过程中, 容易出现STW的问题。
而Major GC和Full GC出现STW的时间,是Minor GC的10倍以上
JVM在进行GC时,并非每次都对上面是哪个内存区域一起回收的,大部分时候回收的都是新生代。针对Hotspot VM的实现,它里面的GC按照回收区域又分为两大种类型:一种是部分收集(Partial GC),一种是整堆收集(FullGC)
部分收集: 不是完整收集整个Java堆的垃圾收集。其中又分为:
-
新生代收集(MinorGC/YoungGC): 只是新生代的垃圾收集。
-
老年代收集(MajorGC/OldGC): 只是老年代的垃圾收集。
目前,CMsGC会有单独收集老年代的行为。
注意,很多时候Major GC会和Full GC混淆使用,需要具体分辨是老年代回收还是整堆回收。
-
混合收集(MixedGC):收集整个新生代以及部分老年代的垃圾收集。
目前,只有G1 GC 会有这种行为。
整堆收集(FullGC): 收集整个java堆和方法区的垃圾收集。
触发Full GC执行的情况有如下五种:
- 调用System.gc()时,系统建议执行FullGC,但是不必然执行。
- 老年代空间不足
- 通过Minor GC后进入老年代的平均大小大于老年代的可用内存。
- 由Eden区,survivor space0(Form Space)区向survivor space1(To Space)区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存大于该对象大小。
说明:Full GC是开发或调优中尽量要避免的。这样暂时时间会短一些。
触发OOM的时候,一定是进行了一次Full GC,因为只有在老年代空间不足时候,才会爆出OOM异常。
以下是测试代码案例:
/*** GC测试**/
public class GCTest {public static void main(String[] args) {int i = 0;try {List<String> list = new ArrayList<>();String a = "mogu blog";while(true) {list.add(a);a = a + a;i++;}}catch (Exception e) {e.getStackTrace();}}
}
设置JVM启动参数
-Xms10m -Xmx10m -XX:+PrintGCDetails
打印出日志
[GC (Allocation Failure) [PSYoungGen: 2038K->500K(2560K)] 2038K->797K(9728K), 0.3532002 secs] [Times: user=0.01 sys=0.00, real=0.36 secs] - 第一行里的
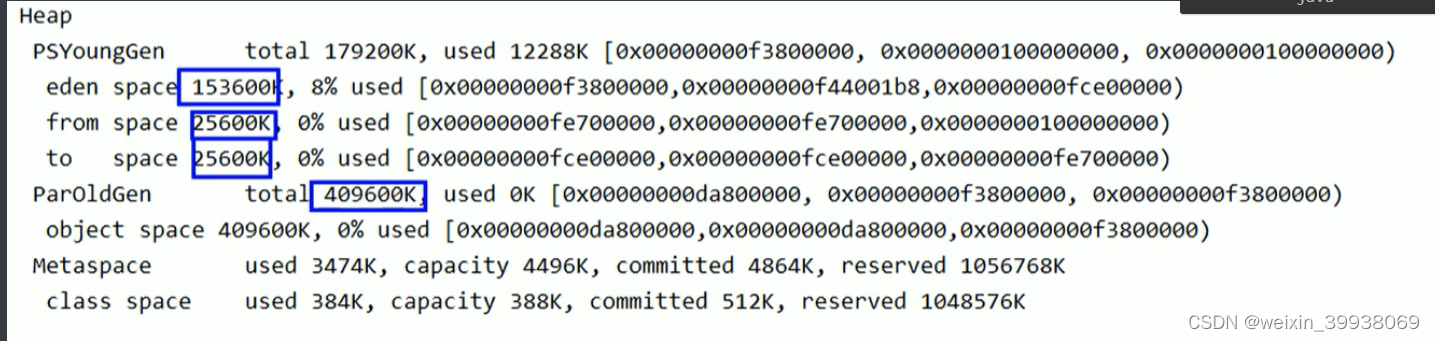
[GC (Allocation Failure) [PSYoungGen: 2038K->500K(2560K)]指出发生了一次年轻代(Young Generation)的垃圾收集(GC),收集前年轻代占用了2038K,收集后500K,年轻代总共可用空间为2560K。这次垃圾收集是因为分配失败(Allocation Failure)触发的,即JVM尝试分配对象时,没有足够的空间。 2038K->797K(9728K), 0.3532002 secs]表示在这次GC事件中,整个堆从占用2038K减少到了797K,堆的总大小是9728K。垃圾收集过程耗时大约0.353秒。[Times: user=0.01 sys=0.00, real=0.36 secs]这表示用户时间为0.01秒,系统时间为0秒,而实际经过的墙钟时间为0.36秒。 后续行提供相似的信息,只是具体的数字有所不同,如年轻代和老年代(ParOldGen)的大小、使用情况和GC耗时等。 出现Full GC (Ergonomics) [PSYoungGen: ...] [ParOldGen: ...]指的是进行了一次完整的垃圾收集,涉及到年轻代和老年代,同时优化器(Ergonomics)也在尝试自动调整性能参数。 最末尾的部分Heap是堆的总结信息,给出了年轻代(PSYoungGen)、老年代(ParOldGen)和元空间(Metaspace)的总大小、使用情况、提交的内存和保留的内存。 最后异常信息java.lang.OutOfMemoryError: Java heap space表示Java堆空间不足,无法再分配对象,通常是因为长时间运行后所有的可用堆内存都被用完了,这可能是内存泄露或者是堆容量设置过小导致的。相关的堆栈跟踪显示出错发生在com.atguigu.java.chapter08.GCTest.main函数的第20行。
常用jvm相关指令
jps:查看正在运行的Java进程
jps(Java Process Status):显示指定系统内所有的HotSpot虚拟机进程(查看虚拟机进程信息),可用于查询正咋运行的虚拟机进程。
说明:对于本地虚拟机进程来说,进程的本地虚拟机ID与操作系统进程ID是一致的,是唯一的。
基本使用语法为:jps [options] [hostid]
我们还可以通过追加参数,来打印额外的信息。
options 参数
- -q:仅仅显示LVMID(local virtual machine id),即本地虚拟机唯一id。不显示主类的名称等。
- -l:输出应用程序主类的全类名 或 如果进程执行的是jar 包,则输出jar完整路径。
- -m:输出虚拟机进程启动时传递给主类 main()的参数。
- -v:列出虚拟机进程启动时的JVM参数。比如: -Xms20m -Xmx50m是启动程序指定的jvm参数。
.jstat:查看 JVM 统计信息
jstat(JVM Statistics Monitoring Tool):用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、JIT 编译等运行数据。在没有 GUI 图形界面,只提供了纯文本控制台环境的服务器上,它将是运行期定位虚拟机性能问题的首选工具。常用于检测垃圾回收问题以及内存泄漏问题。
官方文档:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html
基本使用语法为:jstat - [-t] [-h] [ []]
查看命令相关参数:jstat-h 或 jstat-help
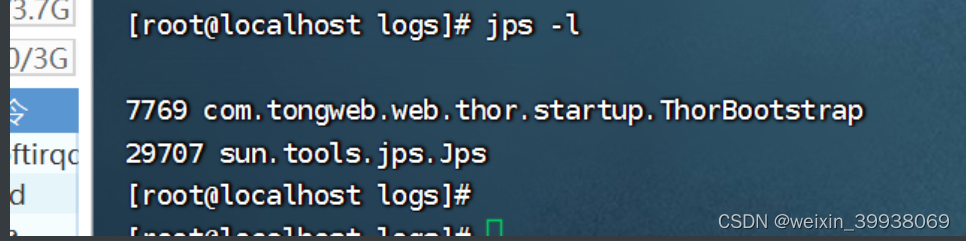
其中 vmid 是进程 id 号,也就是 jps 之后看到的前面的号码,如下:
一般建议用jps -l,能区分判断到tongweb的相关进程
option 参数
选项 option 可以由以下值构成。
类装载相关的:
-
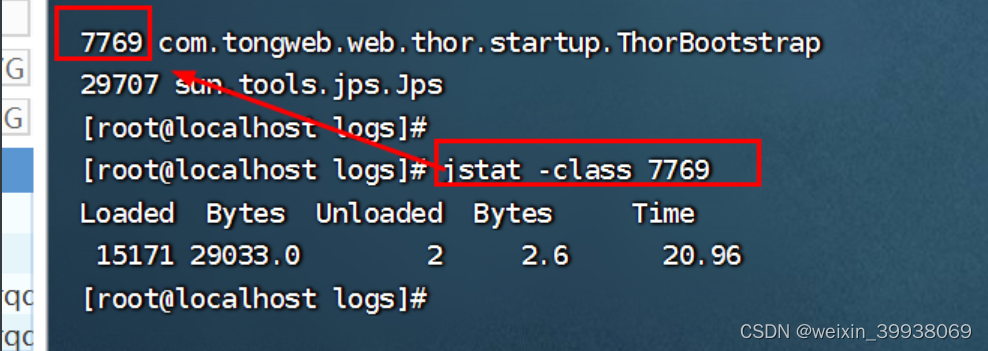
-class:显示 ClassLoader 的相关信息:类的装载、卸载数量、总空间、类装载所消耗的时间等(需要结合pid使用,pid可以使用jps查看,或者查看占用端口9060的进程pid)
-gc:显示与 GC 相关的堆信息。包括 Eden 区、两个 Survivor 区、老年代、永久代等的容量、已用空间、GC 时间合计等信息。

-
S0C: 第一个幸存区的大小(Survivor Space 0 Capacity)
-
S1C: 第二个幸存区的大小(Survivor Space 1 Capacity)
-
S0U: 第一个幸存区的使用大小(Survivor Space 0 Utilization)
-
S1U: 第二个幸存区的使用大小(Survivor Space 1 Utilization)
-
EC: Eden空间的大小(Eden Space Capacity)
-
EU: Eden空间的使用量(Eden Space Utilization)
-
OC: 老年代的大小(Old Generation Capacity)
-
OU: 老年代的使用量(Old Generation Utilization)
-
MC: 元数据空间的大小(Metaspace Capacity)
-
MU: 元数据空间的使用量(Metaspace Utilization)
-
CCSC: 压缩类空间的大小(Compressed Class Space Capacity)
-
CCSU: 压缩类空间的使用量(Compressed Class Space Utilization)
-
YGC: 年轻代垃圾回收次数(Young Generation Garbage Collection count)
-
YGCT: 年轻代垃圾回收花费时间(Young Generation Garbage Collection Time)
-
FGC: 老年代垃圾回收次数(Full Garbage Collection count)
-
FGCT: 老年代垃圾回收花费时间(Full Garbage Collection Time)
-
-gccapacity:显示内容与-gc 基本相同,但输出主要关注 Java 堆各个区域使用到的最大、最小空间。

实战:
如何查看堆内存的内存分配情况
jps -> jstat -gc 进程id

-XX:+PrintGCDetails
.jmap:导出内存映像文件&内存使用情况(多数在内存溢出或者不足的时候使用)
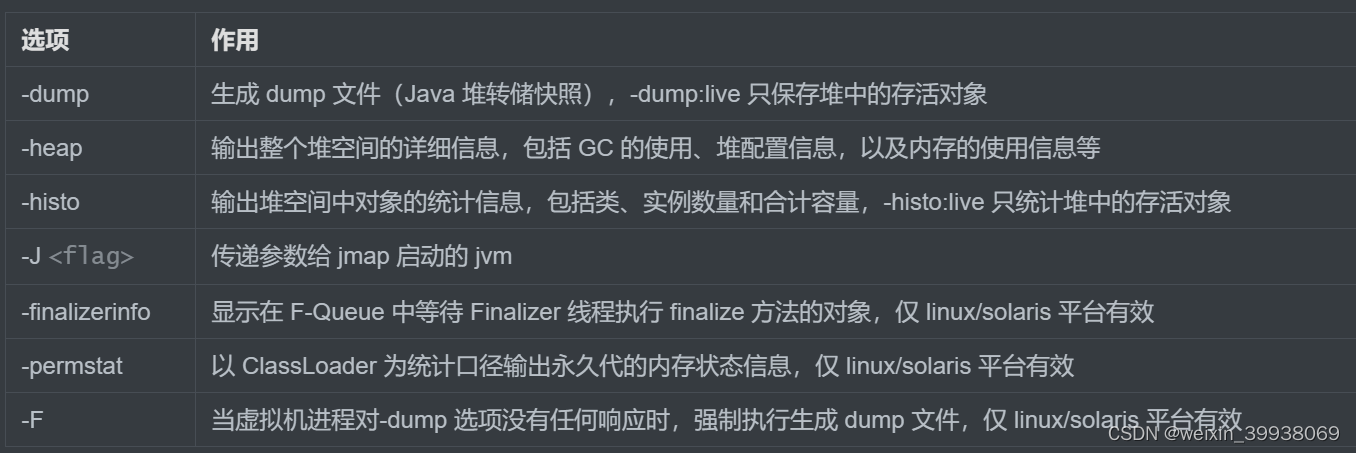
jmap(JVM Memory Map):作用一方面是获取 dump 文件(堆转储快照文件,二进制文件),它还可以获取目标 Java 进程的内存相关信息,包括 Java 堆各区域的使用情况、堆中对象的统计信息、类加载信息等。开发人员可以在控制台中输入命令“jmap -help”查阅 jmap 工具的具体使用方式和一些标准选项配置。
官方帮助文档:https://docs.oracle.com/en/java/javase/11/tools/jmap.html
基本使用语法为:
- jmap [option]
- jmap [option] <executable
- jmap [option] [server_id@]
说明:这些参数和 linux 下输入显示的命令多少会有不同,包括也受 jdk 版本的影响。
参考:
jmap -dump:format=b,file=/opt/heap.hprof pid
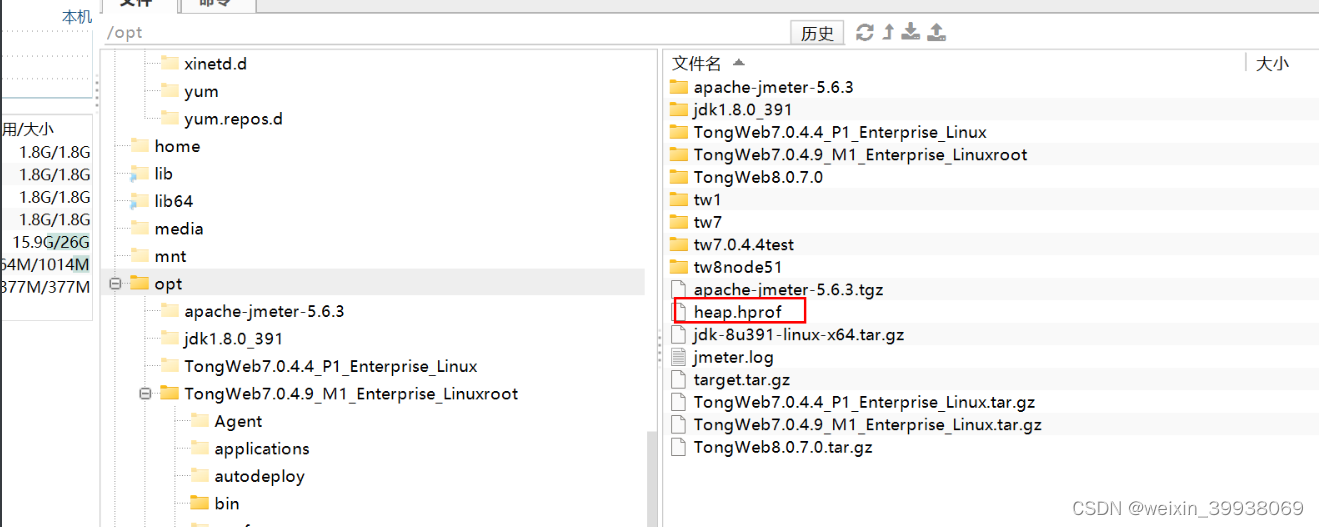
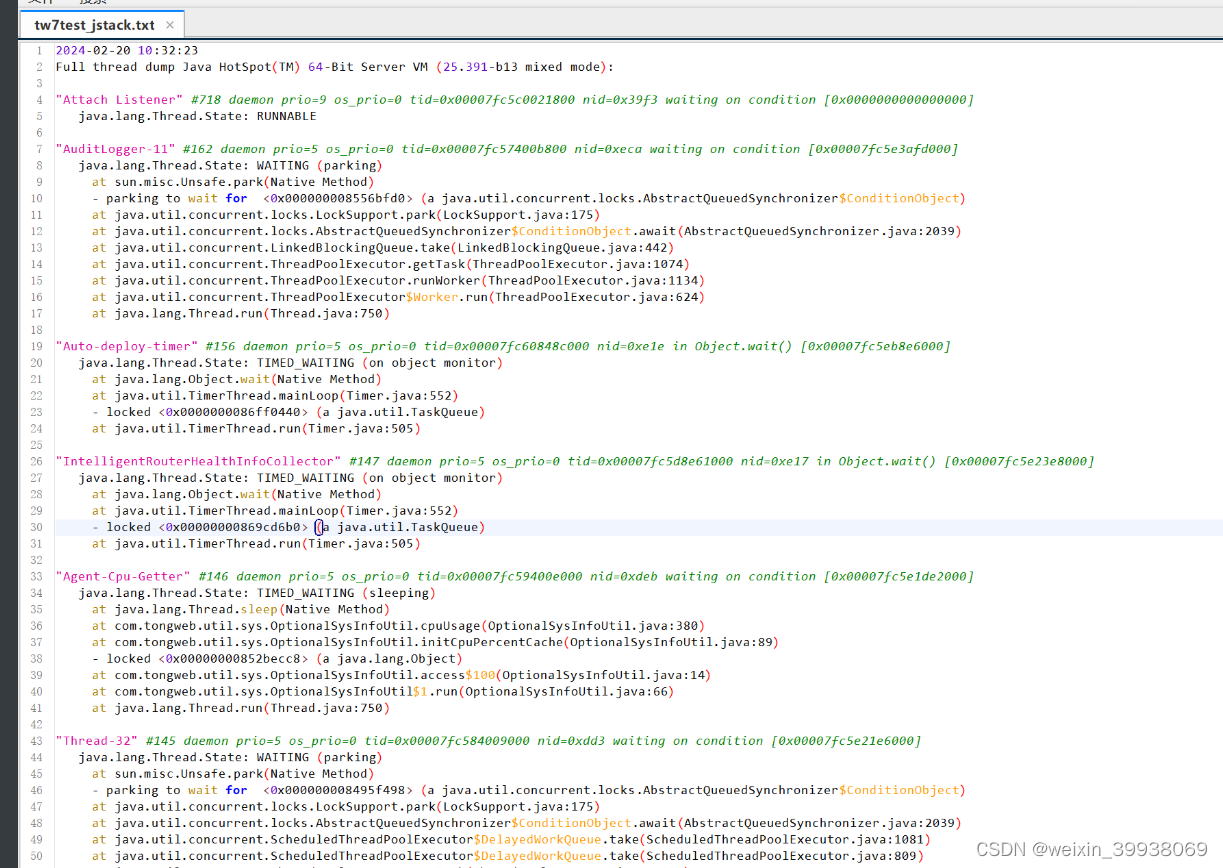
jstack:打印 JVM 中线程快照(多数定位卡顿问题)
jstack(JVM Stack Trace):用于生成虚拟机指定进程当前时刻的线程快照(虚拟机堆栈跟踪)。线程快照就是当前虚拟机内指定进程的每一条线程正在执行的方法堆栈的集合。
生成线程快照的作用:可用于定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等问题。这些都是导致线程长时间停顿的常见原因。当线程出现停顿时,就可以用 jstack 显示各个线程调用的堆栈情况。
官方帮助文档:https://docs.oracle.com/en/java/javase/11/tools/jstack.html
在 thread dump 中,要留意下面几种状态
**- 死锁,Deadlock(重点关注)
- 等待资源,Waiting on condition(重点关注)
- 等待获取监视器,Waiting on monitor entry(重点关注)
- 阻塞,Blocked(重点关注)
- 执行中,Runnable
- 暂停,Suspended
- 对象等待中,Object.wait() 或 TIMED_WAITING
- 停止,Parked**
可以参考以下指令,导出txt或者dump文件(3260是通过jps查看到的pid)
jstack 3260 > /opt/jstack.txt
tongweb如何开启gc日志和相关jvm参数配置
参考这个帖子,把相关配置配置上去:tw7配置gc日志和阈值
检查一下有没有这两个配置

本次测试使用了以下代码
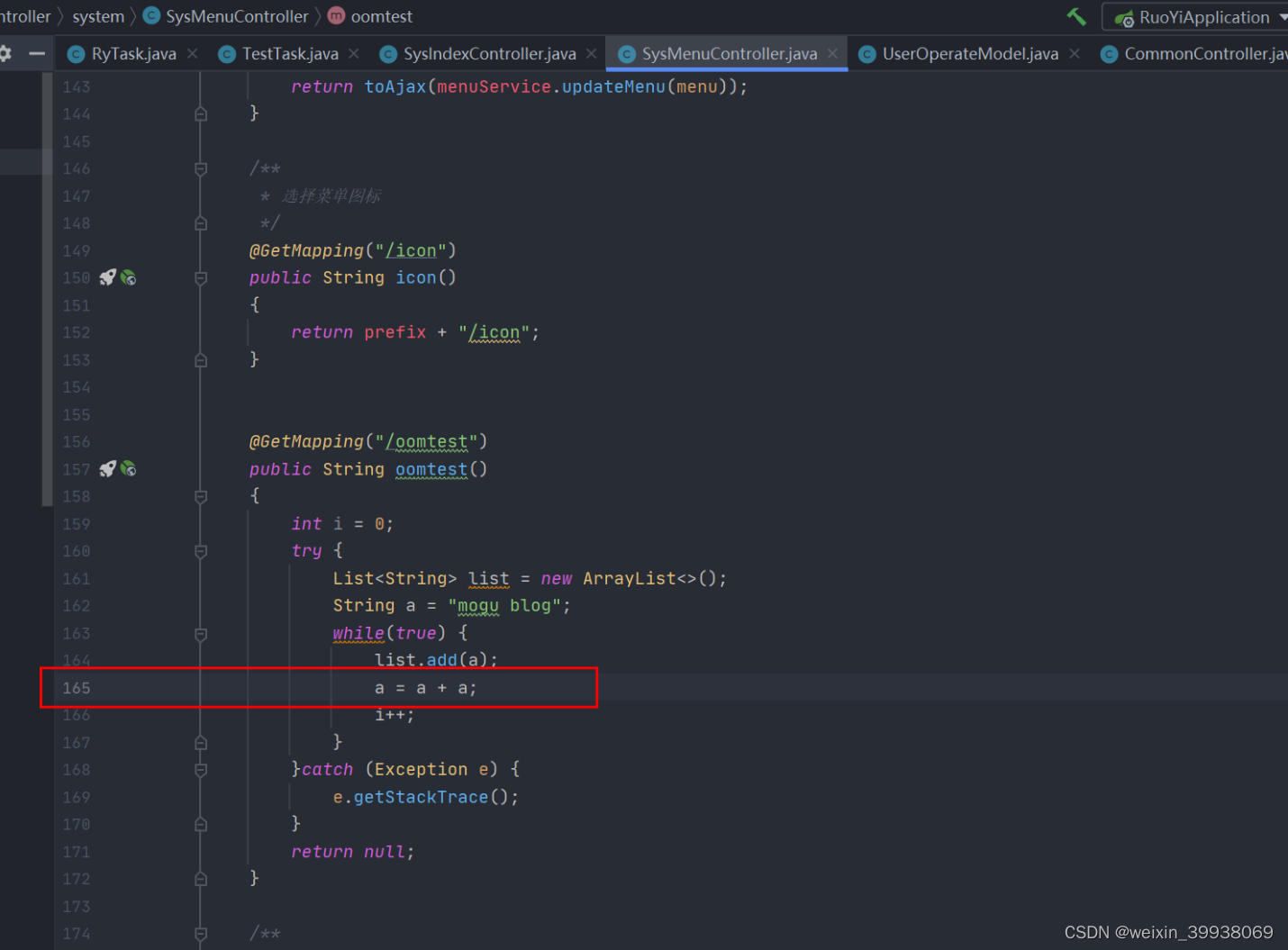
@GetMapping("/oomtest")public String oomtest(){int i = 0;try {List<String> list = new ArrayList<>();String a = "mogu blog";while(true) {list.add(a);a = a + a;i++;}}catch (Exception e) {e.getStackTrace();}return null;}原理:
这个oomtest()方法旨在通过以下方式触发一个OutOfMemoryError(内存溢出错误):
创建一个名为list的ArrayList对象,用于存储字符串。
创建一个初始值为"mogu blog"的字符串a。
进入一个无限循环,循环中进行两个操作:
将字符串a添加到list中。
将a与自己连接(a = a + a),这样每次循环迭代字符串长度都会翻倍。
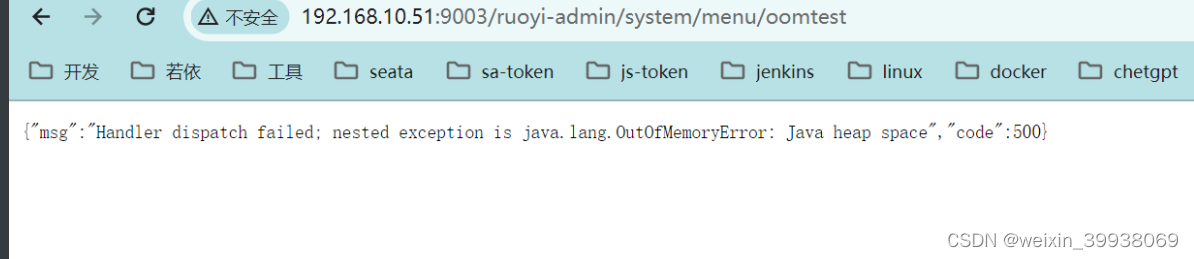
由于每次循环字符串长度都以指数方式增长,并且每个迭代中新产生的字符串都被添加到list中,这将极其迅速地消耗JVM堆内存。最终,这将导致一个OutOfMemoryError异常,因为堆内存空间被耗尽,无法再分配更多对象。
登录后直接访问以下url,触发oom
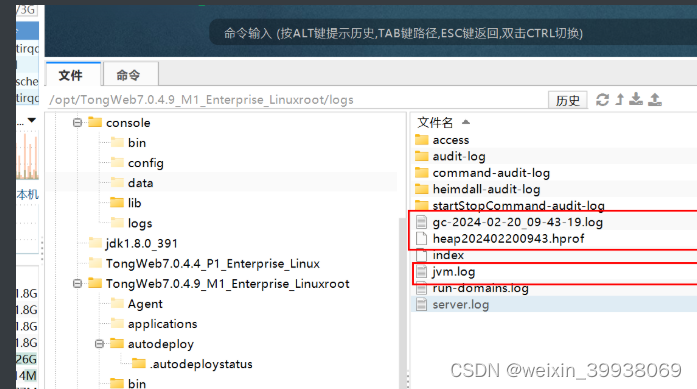
检查tongweb安装目录下的logs目录是否存在以下文件
查看server.log:
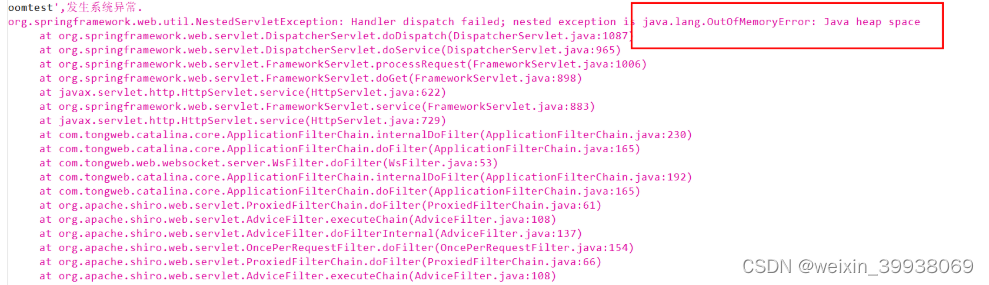
将hprof文件装入到memory 里
memory的操作可以参考这两个帖子:
日志分析工具一Memory Analyzer Mat介绍和使用
MAT工具定位分析Java堆内存泄漏问题方法
装入后如下图所示:
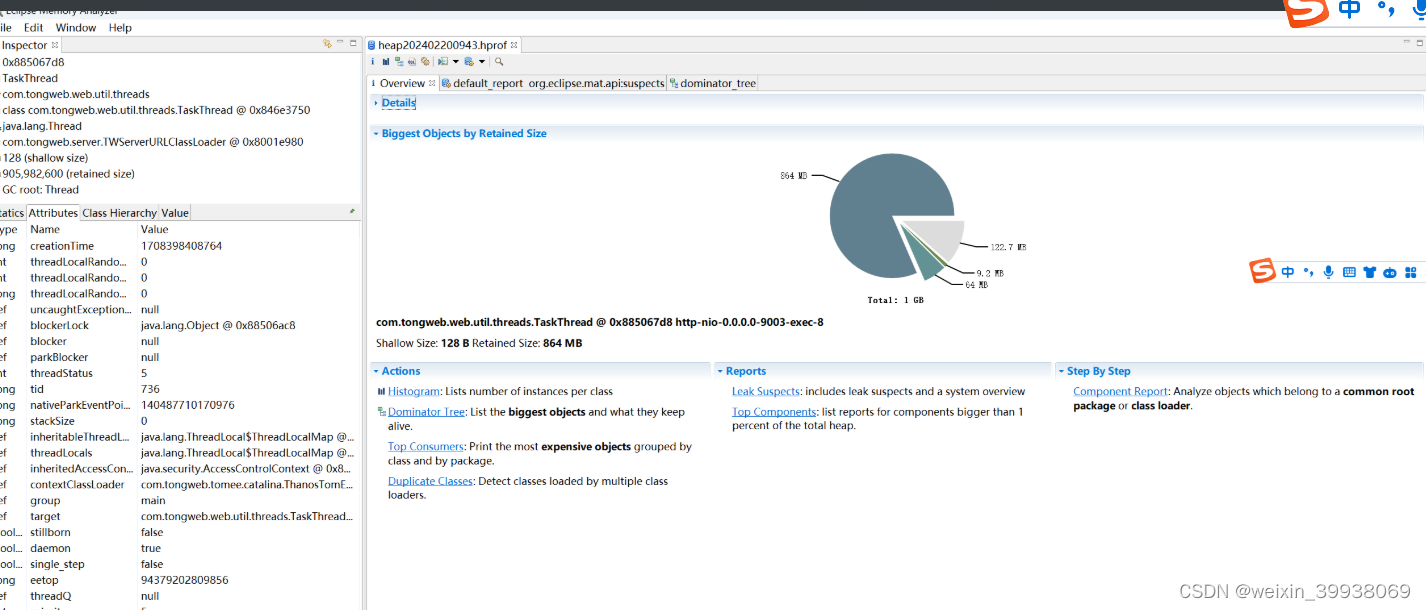
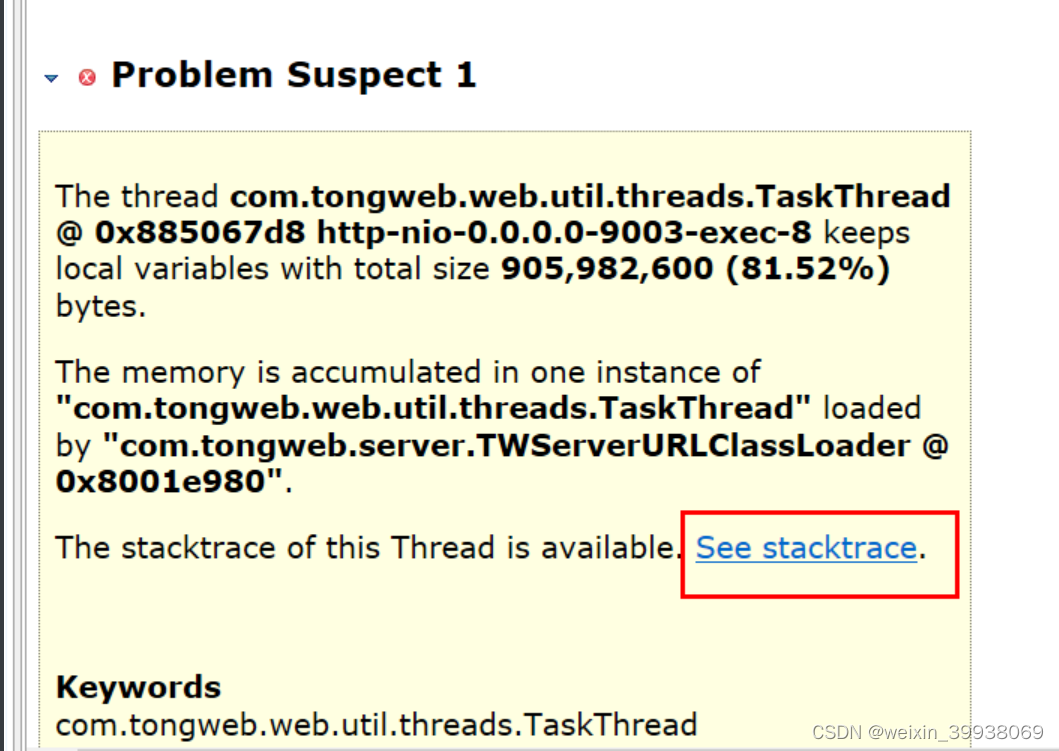
点击这里:
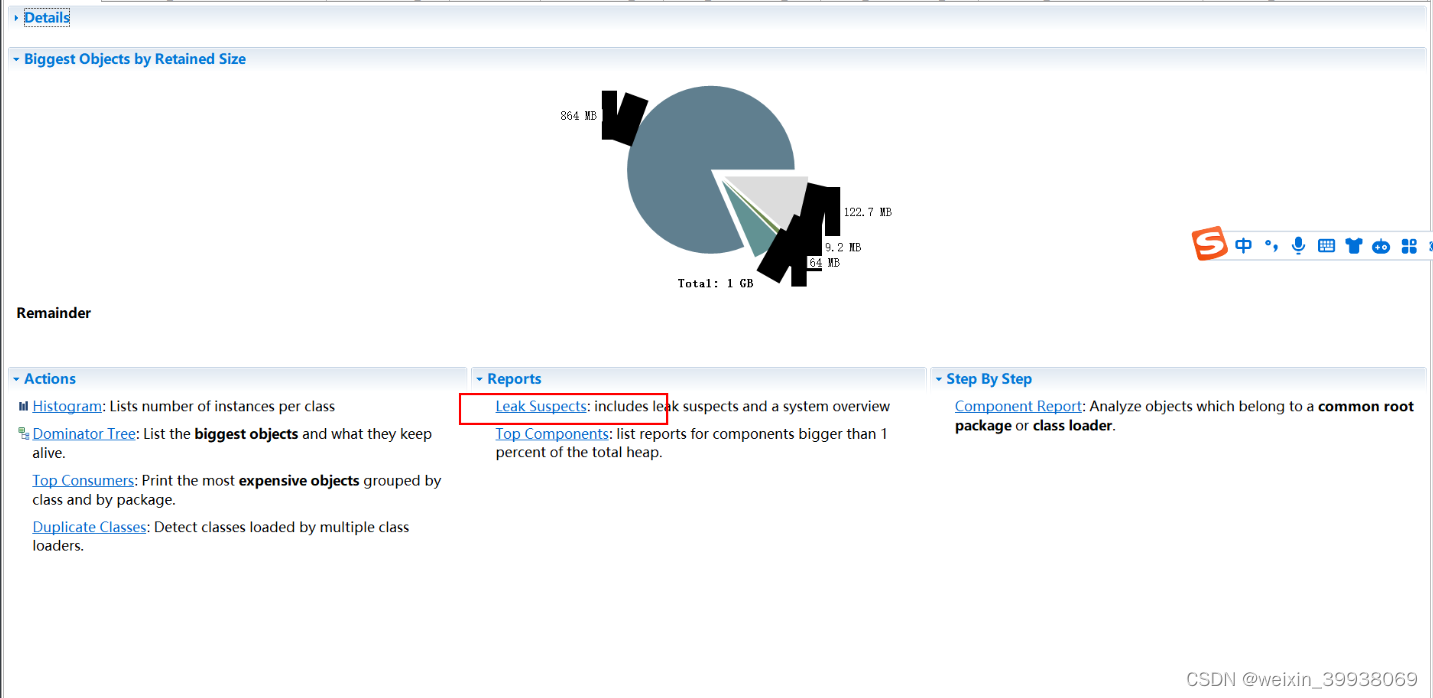
点击后会跳转到这个页面
点击这里:
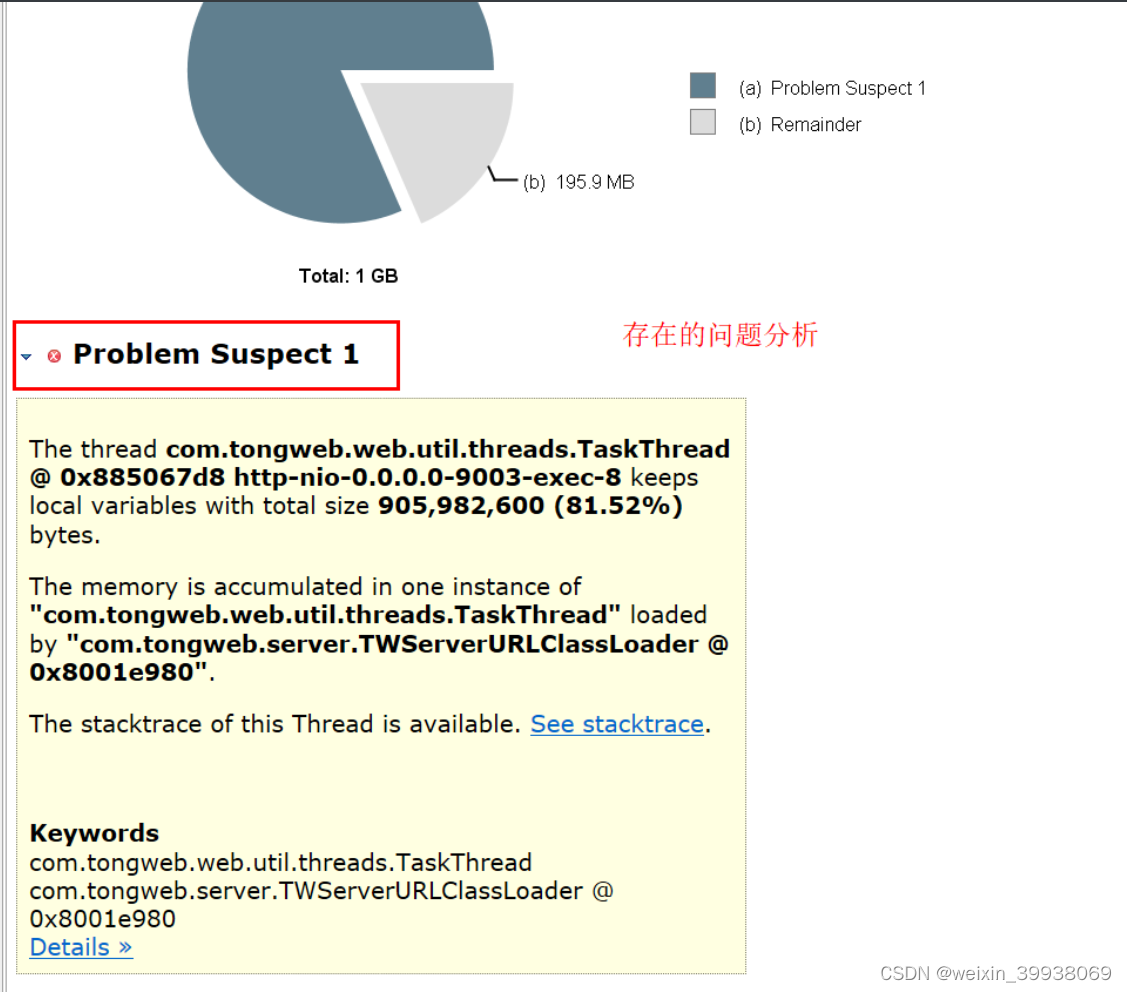
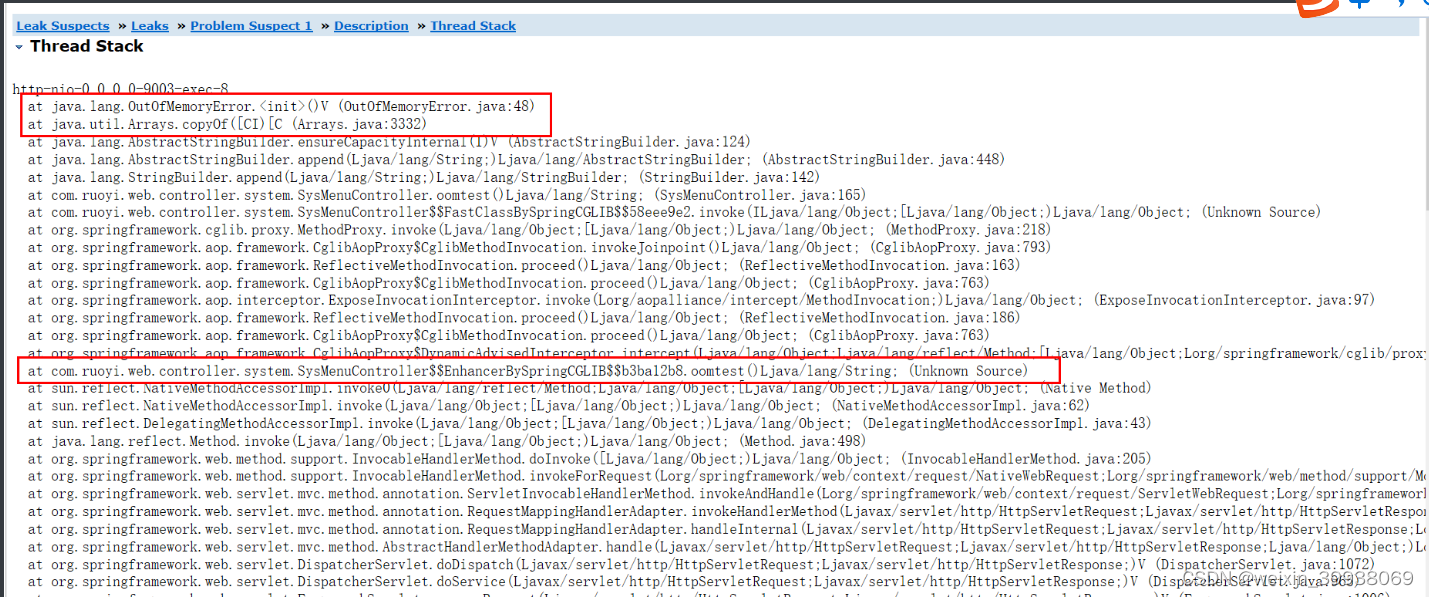
圈起来的就是定位到的问题代码:sysmenuxxx(实际请根据自身应用来进行分析)
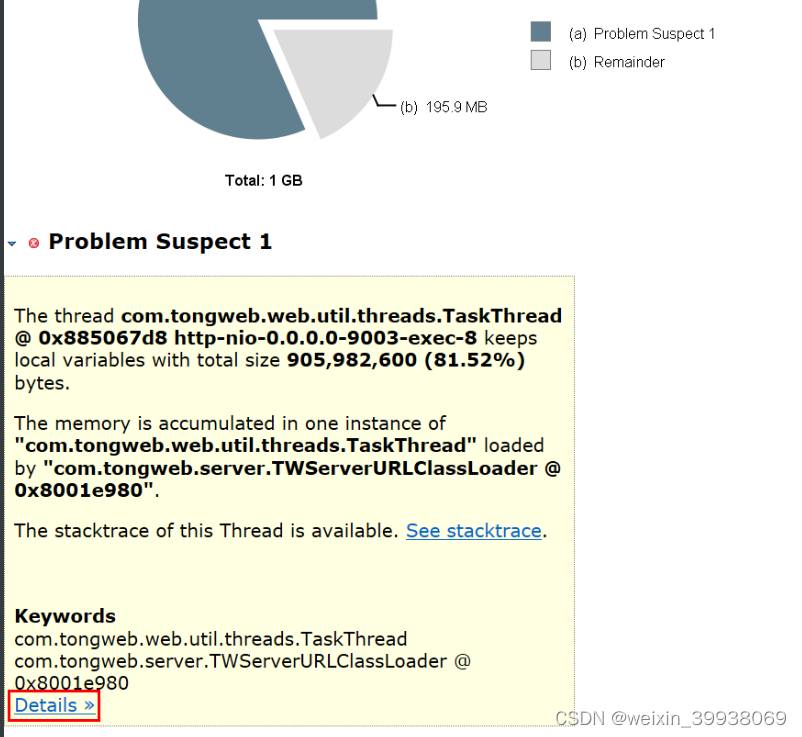
也可以回到problem suspect 1这里,点击details:
往下拉
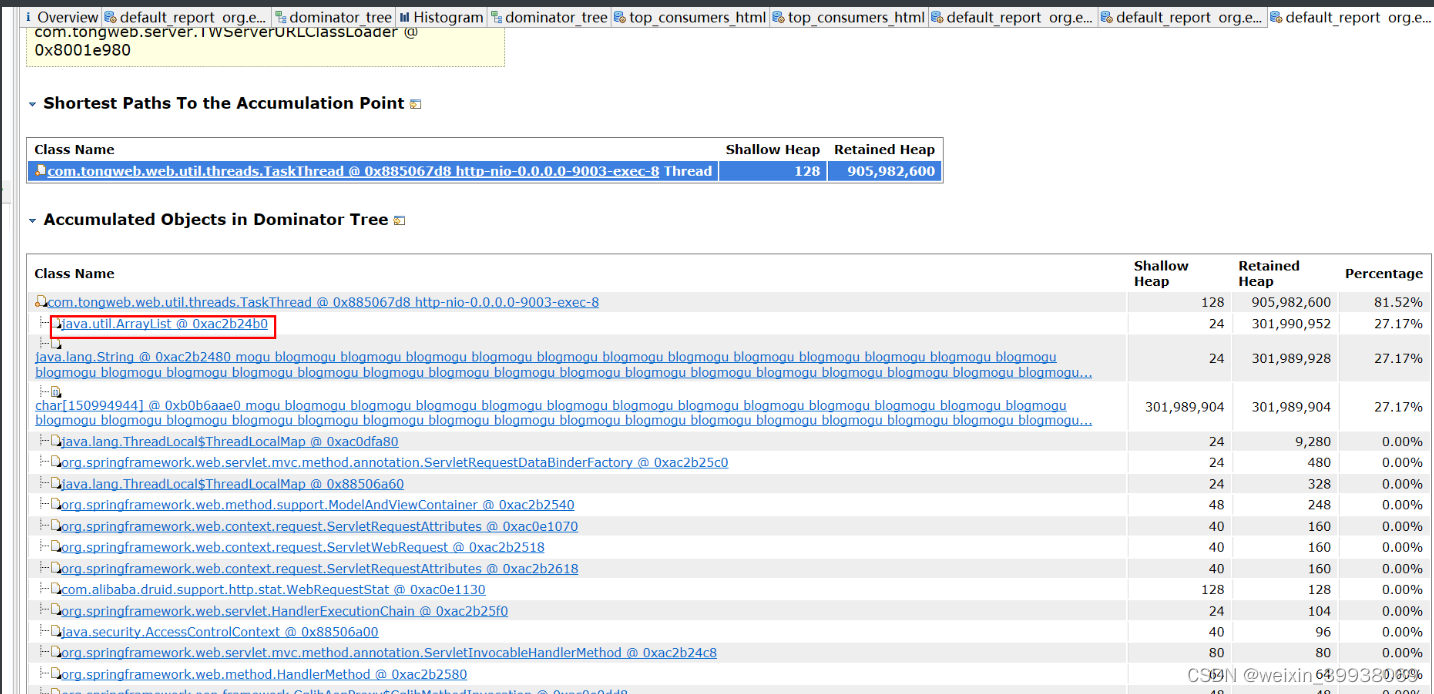
往下拉
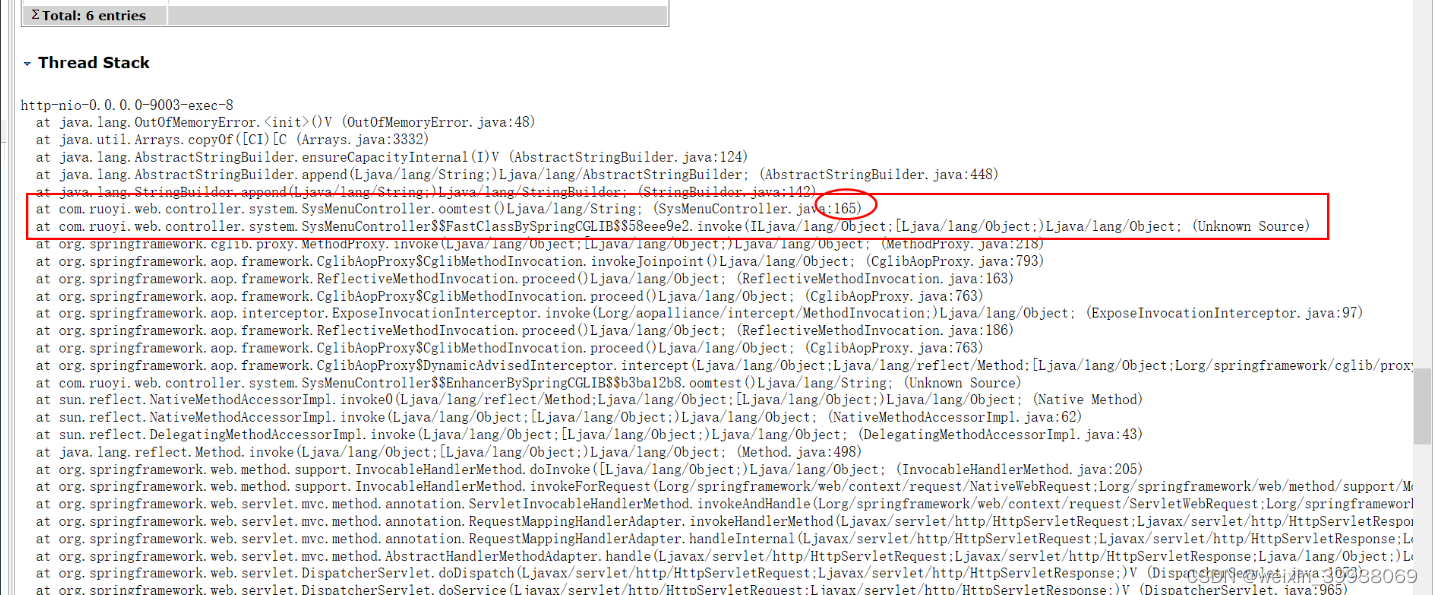
定位成功
这篇关于tongweb生成hprof文件并结合Memory Analyzer Mat分析内存溢出(by lqw)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






