本文主要是介绍Kafka 流式计算工具 ksqlDB 笔记:Pull Query 的用途及特性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ksqlDB 是学习和开发 kafka 流式计算的很方便的工具。它支持 Push Query 和 Pull Query。下面是一些 Pull Query 的测试。
测试对象
我建立了下面的 stream 作为测试对象:
CREATE OR REPLACE STREAM tagvalue (tagId INT, value DOUBLE)WITH (kafka_topic='tagvalue', value_format='json', partitions=1);
插入数据
INSERT INTO tagvalue (tagId, value) VALUES (1, 11000);
INSERT INTO tagvalue (tagId, value) VALUES (2, 10000);
执行 Pull Query
直接对 stream 执行 pull query
SELECT *
FROM tagvalue;
系统如下。系统要求必须有 where 语句。

增加 where 语句:
SELECT *
FROM tagvalue
WHERE tagId = 1;
系统提示如下。系统说我们的 stream 没有主键。

由于不可能修改 stream 的 schema,我们使用系统推荐的方法,改变如下配置为 true,再次执行查询得到如下提示:
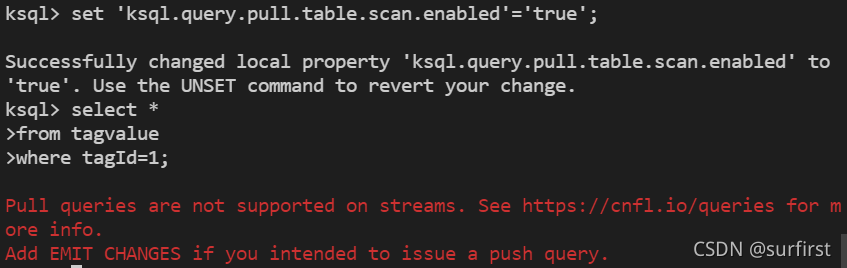
系统的提示是 不能对 stream 执行 pull query.
对 table 执行 pull query
创建基于 tagvalue topic 的 table:
CREATE OR REPLACE TABLE tagvalueview (tagId INT PRIMARY KEY, value DOUBLE)WITH (kafka_topic='tagvalue', value_format='json', partitions=1);
执行 pull query:
select *
from tagvalueview;
得到如下结果。系统不能直接查询基于 topic 创建的 table

按照系统提示创建能查询的 table:
CREATE TABLE QUERYABLE_TAGVALUEVIEW AS SELECT * FROM TAGVALUEVIEW
这时候系统增加了一个新的topic:
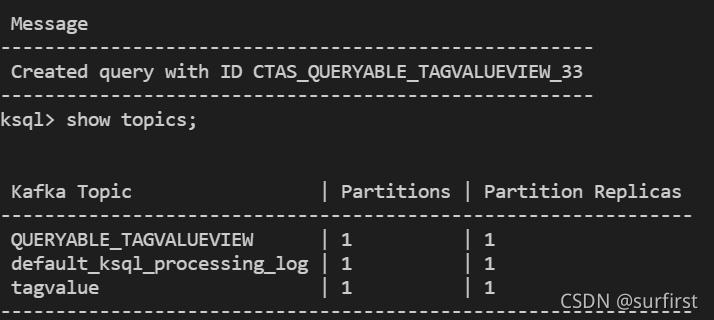
select *
from QUERYABLE_TAGVALUEVIEW ;
以下是执行结果。我们可以看到,系统什么都没返回:
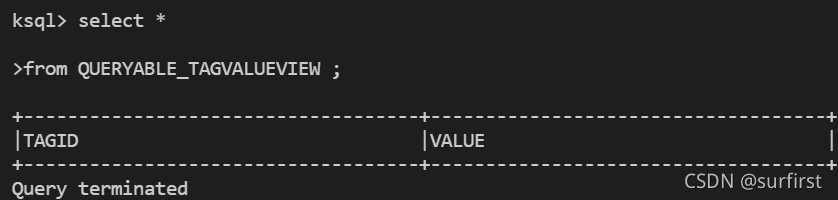
我们再创建一个实时统计 tag 数值数量的 table:
CREATE OR REPLACE TABLE tagvalueview ASSELECT tagId, count(*)FROM tagvalueGROUP BY tagIdEMIT CHANGES;
执行以下查询:
select *
from tagvalueview;
得到查询结果:
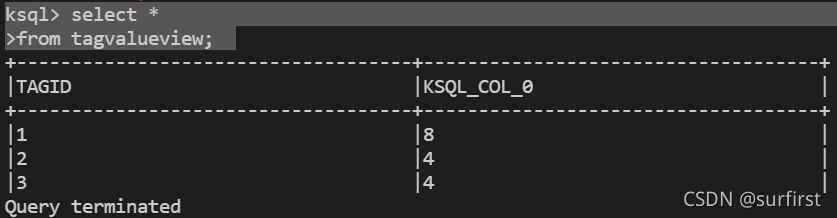
结论
Pull Query 只能在 table 上执行,而且是 queryable table. Pull Query 结合 table 可以帮助开发者统计已有数据的结果。
这篇关于Kafka 流式计算工具 ksqlDB 笔记:Pull Query 的用途及特性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





