本文主要是介绍tigramite教程(二)生物地球科学案例研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 数据生成与绘图
- 因果发现分析
- 平稳性假设、确定性、潜在混杂因素
- 结构假设
- 参数假设
- 使用PCMCIplus的滑动窗口分析
- 聚合因果图
- 非参数因果效应估计
- 假设的图形和调整集
- 干预的真实情况
- 假设的参数模型和因果效应的估计
- 使用关于图的不同假设进行估计
- 非因果估计
项目地址
这个文件夹中的两个案例研究来自气候科学和生物地球科学,遵循以下审查论文中的 QAD-问卷和方法选择流程图(包含在 tigramite github 教程文件夹中):
Runge, J., Gerhardus, A., Varando, G., Eyring, V. & Camps-Valls, G. Causal inference for time series. Nat. Rev. Earth Environ. 10, 2553 (2023).
该审查论文的末尾列出了一些用于解决选定 QAD 问题的软件和方法。
这个例子将演示使用基于因果推断的技术来调查空气温度(Tair)对生态系统呼吸(Reco)的因果效应,数据还包括总初级生产力(GPP)和短波辐射(Rg)。为了更好地说明非参数因果效应估计,这个案例研究考虑了一个具有已知定量基准真实性的合成系统:

在这些方程中,被解释为一个结构因果模型(SCM),其中 η t ˙ \eta _{\dot{t }} ηt˙
是相互独立的标准正态噪声项,除了Tair,其中 η t ˙ T a i r = η t + 1 4 ∗ ϵ t 3 \eta _{\dot{t }}^{Tair}=\eta_t+\frac{1}{4}*{\epsilon}_t^3 ηt˙Tair=ηt+41∗ϵt3
(标准正态噪声项和)具有立方指数,以表示更极端的温度。SCM展示了Reco和Tair之间的单峰关系(请参见下图中的干预基准真相),这在真实数据中也被发现(请参见论文)。
分析将首先说明因果发现,然后进行因果效应估计。让我们从导入一些标准Python包以及tigramite因果推断包开始。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.transforms as mtransformsimport sys
from copy import deepcopyimport sklearn
from sklearn.linear_model import LinearRegression
from sklearn.neural_network import MLPRegressor
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from scipy.stats import gaussian_kde
import warnings
from sklearn.exceptions import DataConversionWarning
warnings.filterwarnings(action='ignore')import tigramite
import tigramite.data_processing as pp
import tigramite.plotting as tpfrom tigramite.models import LinearMediation, Models
from tigramite.causal_effects import CausalEffectsfrom tigramite.pcmci import PCMCI
from tigramite.independence_tests.robust_parcorr import RobustParCorr
数据生成与绘图
步骤紧密遵循QAD模板(综述论文中的表1和图2流程图)。与气候示例不同,这里所有变量(节点)都已定义为每日连续值的时间序列。下一个问题是关于创建一个平稳数据集(图2流程图)。与气候示例不同,这里考虑了多个数据集(多个站点)的设置。在考虑的合成示例中,由于站点只是同一SCM的不同实现,因此平稳性是通过构造满足的(除了所有站点共享的季节性),因此,不同站点的时间序列可以简单地汇总(合并)。为了减轻季节性非平稳性,只考虑4月至9月(模型月份)的时期(见下图)。
# Time series length is 6 years
T = 365*6 + 1# 4 Variables
N = 4# We model 5 measurement sites
M = 5data_dict = {}
mask_dict = {}
for site in range(M):modeldata_mask = np.ones((T, N), dtype='int')for t in range(T):# April to Septemberif 90 <= t % 365 <= 273:modeldata_mask[t,:] = 0mask_dict[site] = modeldata_maskmodeldata = np.zeros((T,N))random_state = np.random.RandomState(site)noise = random_state.randn(T, N)noise[:, 1] += 0.25*random_state.randn(T)**3for t in range(1, T):modeldata[t,0] = np.abs(280.*np.abs(np.sin((t)*np.pi/365.))**2 + 50.*np.abs(np.sin(t*np.pi/365.))*noise[t,0])modeldata[t,1] = 0.8*modeldata[t-1,1] + 0.02*modeldata[t,0] + 5*noise[t,1] modeldata[t,2] = np.abs(0.2* modeldata[t-1, 2] + 0.002*modeldata[t,0] * modeldata[t,1] + 3*noise[t,2]) modeldata[t,3] = np.abs(0.3*modeldata[t-1,3] + 0.9*modeldata[t,2] * 0.8**(0.12*(modeldata[t,1]-15)) + 2*noise[t,3])data_dict[site] = modeldata# Variable names
var_names = ['Rg', 'Tair', 'GPP', 'Reco']# Init Tigramite dataframe object
dataframe = pp.DataFrame(data=data_dict, mask = mask_dict,analysis_mode = 'multiple',var_names=var_names)
fig_axes = tp.plot_timeseries(dataframe,grey_masked_samples='data',adjust_plot=False,color = 'red',alpha=0.6, data_linewidth=0.3,selected_dataset=0)for index in range(1, len(data_dict)):adjust_plot = Falseif index == M - 1: adjust_plot = Truecolor = ['red', 'green', 'blue', 'yellow', 'lightblue'][index]tp.plot_timeseries(dataframe,fig_axes =fig_axes,grey_masked_samples='data',adjust_plot=adjust_plot,color=color,time_label='day',alpha=0.6, data_linewidth=0.3,selected_dataset=index)
plt.show()
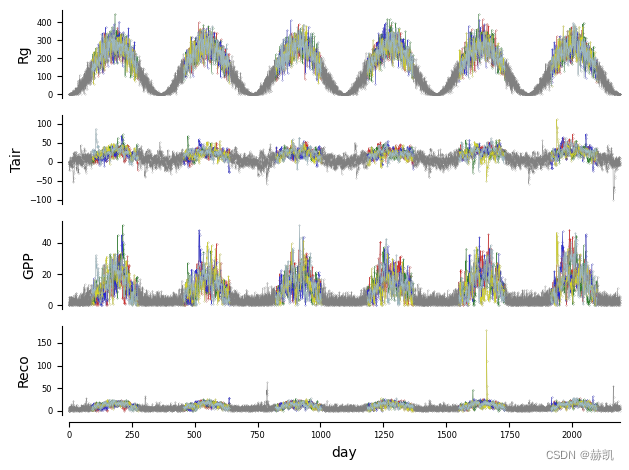
因果发现分析
在得到这个平稳的数据集后,第一个因果问题涉及因果发现。为了选择合适的因果发现方法,必须确定可以合理做出的假设。
平稳性假设、确定性、潜在混杂因素
这里的数据来自多个数据集(因果发现框架中的蓝色框,论文中的图2),然而,这些数据集共享相同的基础分布,下一个问题是这个系统是否是确定性的。考虑到在这个规模下的动态复杂性,可以假设它是一个非确定性系统。下一个假设是是否有潜在的混杂因素,即因果影响两个或更多观察变量的未观察变量。在这里,由于限制分析仅限于季节,在此期间可以预期平稳性,因此合理地假设不存在隐藏的混杂因素,这在基础SCM中是正确的。
结构假设
接下来需要做出图类型的结构假设。由于这里的进程很快,同时因果效应(即,在数据的时间分辨率1天以下的因果影响)可能会发生。此外,在这里,可以通过在图中不允许Rg有任何父母节点来强制实施Rg是外生变量的领域知识。这些假设建议使用基于约束的因果发现算法PCMCI+(或其他类似选项,见图2)。
为了对PCMCI+估计的因果时间序列图中最大时间滞后做出假设(即 X t − τ j → X t j X_{t-\tau}^j \to X^j_t Xt−τj→Xtj,所有 τ \tau τ such that 在图中的最大),可以使用数据来调查滞后依赖函数,或者,像在这里一样,可以使用领域知识来证明 τ m a x = 1 \tau_{max}=1 τmax=1(以天为单位)。
参数假设
接下来,为PCMCI+选择下一个超参数是关于条件独立性的测试,这需要一个参数假设。下面我们使用Tigramite的plot_densities函数来通过联合和边际密度估计调查依赖关系的类型。在这里,我们描绘了原始数据以及实现正态分布边际的转换数据。
dataframe_here = deepcopy(dataframe)
matrix_lags = None
matrix = tp.setup_density_matrix(N=N, var_names=dataframe.var_names, **{这篇关于tigramite教程(二)生物地球科学案例研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





