本文主要是介绍k8s pv与pvc理解与实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考文章: https://blog.csdn.net/qq_41337034/article/details/117220475
一、 pv/pvc简述
Pv是指PersistentVolume,中文含义是持久化存储卷是对底层的共享存储的一种抽象,Pv由管理员进行配置和创建,只要包含存储能力,访问模式,存储类型,回收策略,后端存储类型等主要信息。它和具体的底层存储技术实现有关,比如NFS,Hostpath等,Pvc是一种用户对存储的需求声明,声明中包括了存储大小,存储类型,以及k8s中选择器的属性等,另一个角度来看Pvc和Pod类型,Pod是消耗节点node资源,Pvc消耗的是Pv资源,Pod可以请求CPU和内存,而PVC可以请求特定的存储空间和访问模式。
二、 pv/pvc使用场景

存储工程师把存储系统上的总空间划分成一个个小的存储块 k8s集群的管理员将存储块和pv进行一一对应,用户通过pvc对存储进行申请。比如可以指定具体大小容量的存储,访问模式和存储类型,用户这样不用关系底层存储实现的细节,只需要直接申请使用pvc。
三、 创建并使用pv
PV支持多种不同类型的存储,如:NFS、hostpath、RBD、ISCSI,文中将使用NFS为例介绍如何创建pv。
-
第一步,搭建一个NFS共享服务器,共享目录为/data/share
搭建nfs服务器参考:https://blog.csdn.net/qq_50247813/article/details/127399198
把共享目录换成/data/share(前提是目录已存在),允许你所在的网段可以访问。 -
创建pv,并添加NFS共享服务器地址和目录
# kubectl create -f pv.yaml # cat pv.yamlapiVersion: v1 kind: PersistentVolume # 指定为PV类型 metadata: name: pv-share # 指定PV的名称labels: release: pv-share # 指定PV的标签 spec: capacity: storage: 1Gi # 指定PV的容量accessModes:- ReadWriteOnce # 指定PV的访问模式,简写为RWO,只支持挂载1一个Pod的读和写persistentVolumeReclaimPolicy: Delete # 指定PV回收的策略nfs: # 指定PV的存储类型,本文是以nfs为例path: /data/share # 共享的地址server: 192.168.44.162 # 服务器地址note:
accessModes支持多种访问模式
1) ReadWriteOnce(RWO):读写权限,但是只支持挂载在1个Node
2) ReadWriteMany(ROX):只读权限,支持挂载在多个Node
3) ReadWriteMany(RW):读写权限,支持挂载在多个Node
persistentVolumeReclaimPolicy的策略,指的是如果PVC被注释放掉后,PV的处理,这里说的释放,指的是用户删除PVC后,与PVC对应的PV会被释放掉,PVC和PV是一一对应关系。
1) Retain(默认),PV的数据不会清理,会保留volume,如果需要清理,需要手动进行
2) Recycle,会将数据进行清理,即rm -rf /thevolume/*(只有NFS和HostPath支持),清理完后,PV会呈现available状态,支持再次的绑定PVC
3) Delete,删除存储资源,会删除PV及PV后端的存储资源,比如删除AWS EBS卷(只有AWS EBS, GCE PD, Azure Disk 和 Cinder 支持)
-
查看pv
# kubectl get pvNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv-share 1Gi RWO Delete Available 6s观察可发现,pv创建好了后状态为Available,此时如果此pv刚好条件符合刚刚创建的pvc,则会自动绑定。
四、 创建pvc
#kubectl create -f pvc.yaml
#cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pv-share
spec:resources:requests:storage: 1GivolumeMode: FilesystemaccessModes:- ReadWriteOnce
1) PVC声明了accessModes访问类型为ReadWriteOnce,创建后,系统会自动去找能够支持ReadWriteOnce访问类型的PV,若无符合条件的PV,则不会进行绑定
2) PVC声明了storage的大小为1Gi,创建后,系统会自动取找能够支持此容量的PV,若无符合条件的PV,则不会进行绑定。
从这里来看,对于用户来说,即只需要声明访问类型、容量、另外还可以通过StorageClass声明具体的PV类型即可完成对持久化存储的申请,而不需要去维护和关注后端存储。
# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pv-share Bound pv-share 1Gi RWO 15s
我发现pvc创建好了的状态的就是Bound,这是因为在创建并声明自己要什么样子的存储时。我们刚刚创建的pv刚好符合条件,则自动绑定。状态更新,此时pv的状态也应该发生了变更。
# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-share 1Gi RWO Delete Bound default/pv-share 92m
五、 pod使用pvc
# kubectl create -f nginx-pod.yaml
# cat nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: nginx
spec:containers:- name: nginximage: nginxports:- containerPort: 80name: "http-server"volumeMounts:- mountPath: "/usr/share/nginx/html"name: pv-storagevolumes:- name: pv-storagepersistentVolumeClaim:claimName: pv-share # 挂在的是 pvc
查看pod详情(省略部分输出)
kubectl describe pod nginx
Volumes:pv-storage:Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)ClaimName: pv-shareReadOnly: falsedefault-token-2jswl:Type: Secret (a volume populated by a Secret)SecretName: default-token-2jswlOptional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300snode.kubernetes.io/unreachable:NoExecute op=Exists for 300s
可以看出nginx pod已经绑定了pvc名称pv-share 的存储。
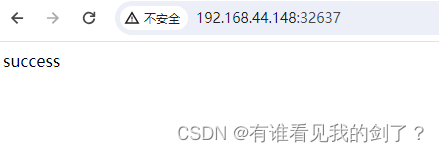
六、修改共享目录文件,访问测试
nfs服务器的共享地址是 /data/share
echo "success" >> index.html; chmod 777 index.html
现在就可以进入到pod容器内部查看文件了
kubectl exec -it nginx -- cat /usr/share/nginx/html/index.html
[root@k8s-master ~]# kubectl exec -it nginx -- cat /usr/share/nginx/html/index.html
success
七、 创建一个service,让集群外部可访问nginx
# kubectl expose pod nginx --port=80 --target-port=80 --type=NodePort
# kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx NodePort 10.107.90.132 <none> 80:32637/TCP 4m29s
这篇关于k8s pv与pvc理解与实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



