本文主要是介绍如何优化一个看似正常的数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通常DBA是不会太了解业务逻辑的,遇到系统中劣质的sql 一般也是以通过添加索引的方式来优化,但是并不是所有的sql都能通过添加索引来优化
这就需要重sql的本身来做分析,另外还要了解什么样的语句会不走索引!本文通过几个简单的例子来介绍 一个看似正常的系统如何做优化!
1.wait event alert
近期一套MES系统 时不时的会报一个异常等待的报警

异常的等待事件是log file sync 这个等待事件虽然归类为commit 但是其实IO相关的

2.通过OEM看数据库整体负载状态
从OEM上看系统的整体负载还是可以的,并无明显的负载波动

3.通过AWR具体细致的分析异常
这个时候就需要拉一下系统的awr报表来看看了
AWR 需要怎么来看?
首先看load profile 这里显示了系统的基本的负载信息
从负载看数据库的负载不高

最重要就是foreground wait event,如果一个数据库有问题,基本都可以在这里找到端倪
这里可看到top wait 中有明显的几个异常等待
1.log file sync
2.direct path read temp
当Oracle从TEMPORARY数据库文件读取到PGA内存(而不是缓冲区缓存)时,直接从“temp”读取路径。如果支持异步IO(并且正在使用),那么Oracle可以提交IO请求并继续处理。然后,它可以稍后拾取IO请求的结果,并将等待“直接路径读取temp”,直到所需的IO完成。
如果异步IO没有被使用,那么IO请求会阻塞,直到完成,但这些在IO发出时不会显示为等待。会话稍后返回以获取已完成的IO数据,但随后会在“direct path read temp”上显示等待,尽管此等待将立即返回。
因此,这个等待事件非常具有误导性,因为:
等待的总数可能不能反映IO请求的数量
在“直接路径读取温度”中花费的总时间可能并不总是反映真实的等待时间。
3.direct path read
当直接读到PGA内存(而不是读到缓冲缓存)时,Oracle通常使用直接路径读取。如果支持异步IO(并且正在使用),那么Oracle可以提交IO请求并继续处理。然后,它可以稍后获取IO请求的结果,并等待“直接路径读取”,直到所需的IO完成。
如果异步IO没有被使用,那么IO请求会阻塞,直到完成,但这些在IO发出时不会显示为等待。会话稍后返回以获取已完成的IO数据,但随后会显示“直接路径读取”的等待,尽管此等待将立即返回。
因此,这个等待事件非常具有误导性,因为:
等待的总数并不反映IO请求的数量
在“直接路径读取”中花费的总时间并不总是反映真实的等待时间。
这种类型的读请求通常用于:
排序IO(当排序不适合内存时)
并行查询从机
全表扫描
预读(一个进程可能会对它预计在不久的将来需要的块发出IO请求)
这三个都和IO 相关,在OLTP系统中出现2/3等待基本可以判定是因为sql中有大量的全表扫描引起的

从 top 10的 wait event来看,如果一个OLTP系统的db cpu 不是排在第一位,而且占比不能达到80% 就可以认为这个系统是不健康的,需要做系统的调优!
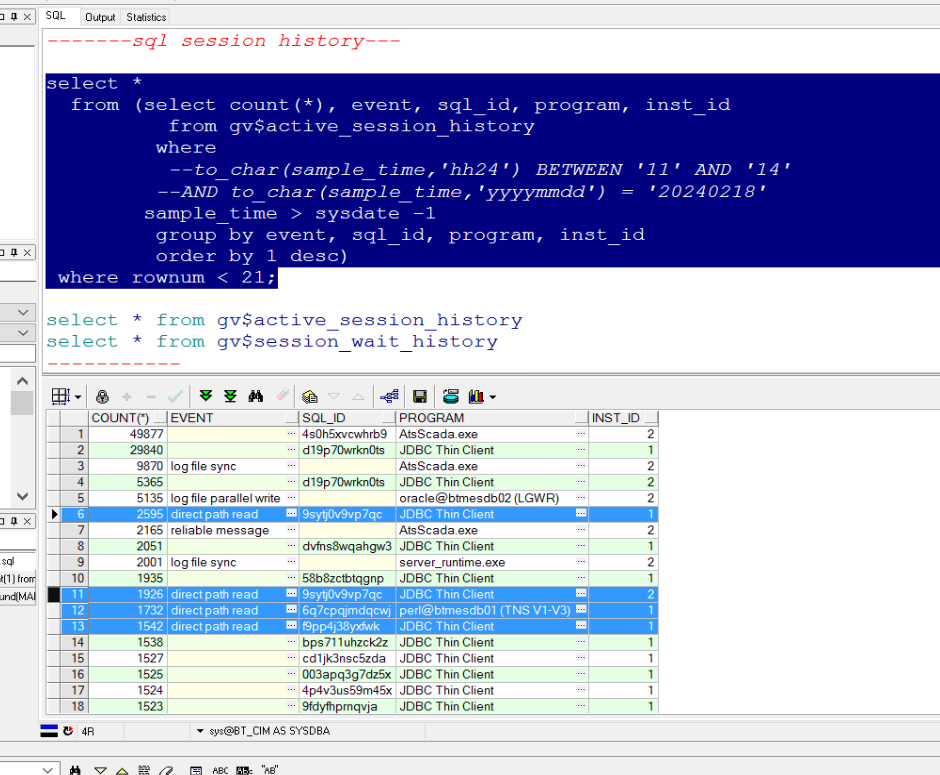
查询最近一天的top event和对应的sqlid
select *
from (select count(*), event, sql_id, program, inst_id
from gv$active_session_history
where
–to_char(sample_time,‘hh24’) BETWEEN ‘11’ AND ‘14’
–AND to_char(sample_time,‘yyyymmdd’) = ‘20240218’
sample_time > sysdate -1
group by event, sql_id, program, inst_id
order by 1 desc)
where rownum < 21;
也能发现有不少 direct path read的等待事件
具体的优化过程
SQL1
根据sql id f9pp4j38yxfwk查一下sqlmonitor
Sql_monitor是oracle11g后引入了一个调优工具包,至少满足一个条件才会被监控到
- 如果sql执行消耗超过5秒 cpu or IO time则会被记录到v$sql_monitor
- 加了/*+ monitor*/ hint
SELECT DBMS_SQLTUNE.report_sql_monitor(sql_id => ‘&sql_id’, type => ‘TEXT’) AS report FROM dual;
可以看到执行时间在8-9秒左右,执行计划位全表扫描,sql没有绑定变量
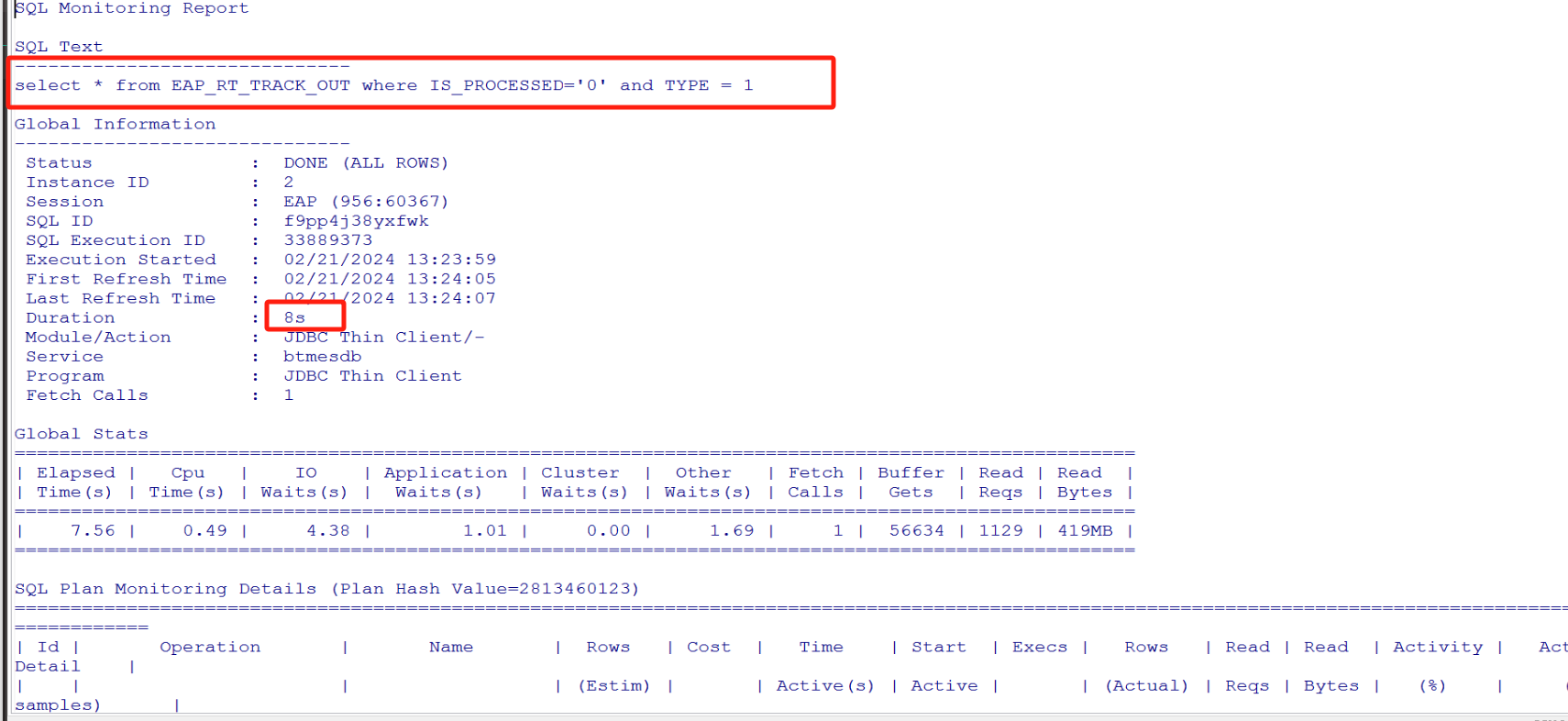
可以看到 table access full 的等待事件为 direct path read

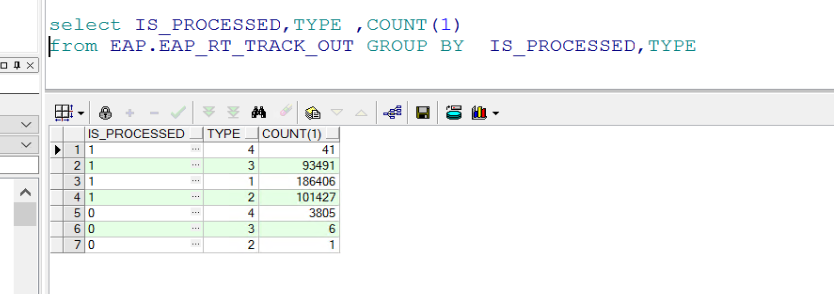
这种sql相对比较容易优化, 首先看一下检索项的数据分布,从数据的分布来看如果is_processed =0,则筛选度还是不错的,而看一下库中的查询
基本都是is_processed =0 and type = x ,
如果查询大部分为is_processed =1 则我认为没有必要加联合索引,因为筛选度不高,
一般认为如果一个查询的结果集达到表的全部数据的5-10% 则优化器会优先选择使用全表扫描,无论是否有索引
CREATE INDEX EAP.EAP_RT_TRACK_OUT_INX2
ON EAP.EAP_RT_TRACK_OUT(IS_PROCESSED,TYPE) ONLINE PARALLEL 8 NOLOGGING;
参数解释
noline :减少lock的概率
parallel :设置并发,加快索引的创建速度
nologging:减少 log的量(并不是完全没有log)
再次看执行计划 已经走了 新建的索引了
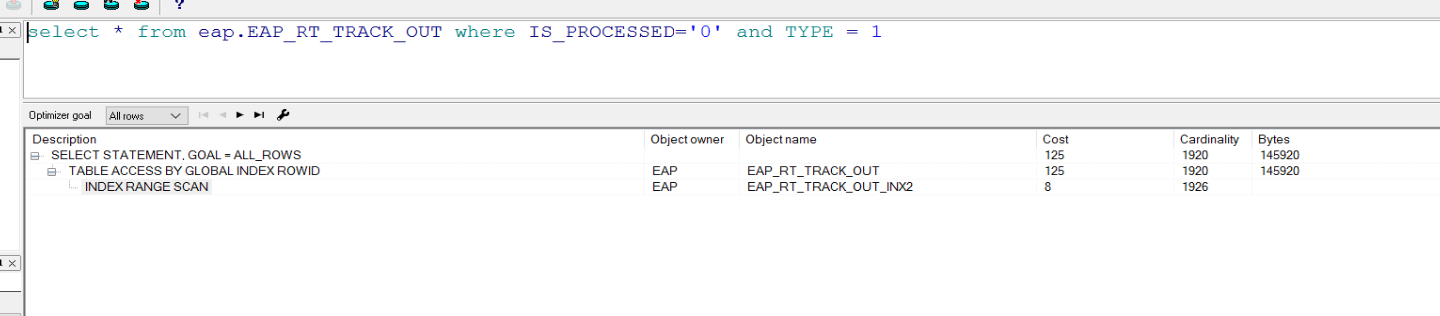
执行时间也由原来的8-9秒缩短为0.2秒左右,如果绑定了变量执行时间会更快

SQL2
很明显这个是OEM执行的数据库audit相关

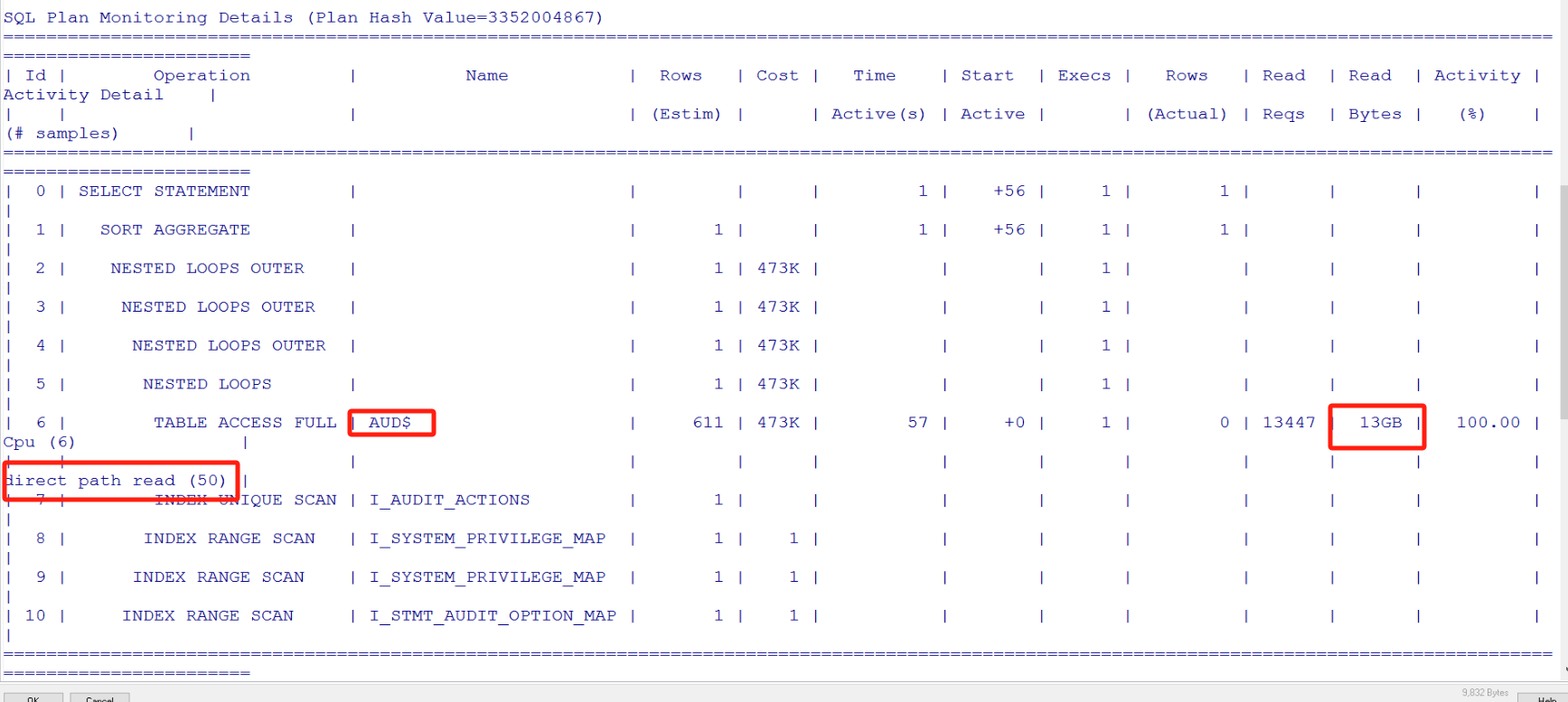
这个处理比较简单直接关闭数据库的audit
SQL> show parameter audit
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
audit_file_dest string /u01/app/oracle/admin/btmesdb/
adump
audit_sys_operations boolean FALSE
audit_syslog_level string
audit_trail string DB
audit_trail 参数介绍
- 设置为`none`以禁用审计功能。
- 设置为`os`以启用审计功能并将其记录写入操作系统文件。
- 设置为`db`或`true`以启用审计功能,并将审计记录写入数据库的`SYS.AUD$`表。
- 设置为`db, extended`以启用审计功能,并在`SYS.AUD$`表的基础上填充额外的列如`SQLBIND`和`SQLTEXT`。
- 设置为`xml`以启用审计功能,并将所有记录写入XML格式的文件。
- 设置为`xml, extended`以启用审计功能,并输出审计记录的所有列,包括`SQLBIND`和`SQLTEXT`的值。
SQL> alter system set audit_trail = ‘none’ scope=spfile;
System altered.
SQL> alter system set audit_trail = ‘none’ scope=spfile sid=’*’;
System altered.
SQL>
找合适的窗口重启数据库
SQL3
看到top 10有几个sql都是类似的只有个别参数不同,因为没有做绑定变量
选择一个sql单独拉出来看看
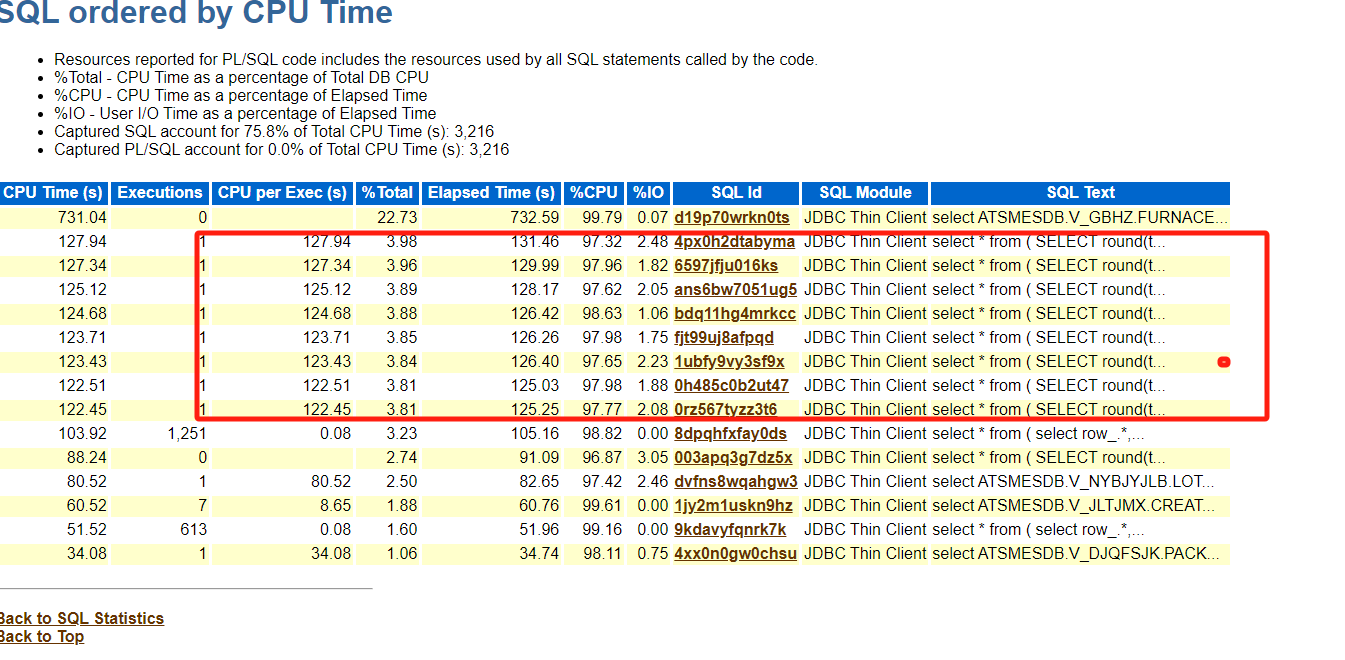
具体sql如下,下面看看在即使不了解业务,仅仅从sql的角度如何来优化
select *from (SELECT round(t2.MAIN_QTY - t1.MAIN_QTY, 2) MAIN_QTYFROM (SELECT ROUND(nvl(sum(MAIN_QTY), 0) / 1000, 2) MAIN_QTYFROM (SELECT sum(t.MAIN_QTY) MAIN_QTY, t.TRANS_TIME CREATEDFROM LJ_MAINTENANCE_PLAN tWHERE t.STEP_NAME = 'LJ'AND t.OUTPUT_SORT_NAME = 'JHCCYB'and WORK_SHIP = '1'GROUP BY t.TRANS_TIME)WHERE to_char(CREATED, 'yyyy-mm-dd') = '2024-02-14') t1,(SELECT round(MAIN_QTY / 1000, 2) MAIN_QTYFROM (SELECT t2.TRANS_TIME CREATED,sum(decode(attributeValue.Attribute_Name,'HX_DislocationFreeLength',attributeValue.Attribute_Value)) /t3.SPEC3 MAIN_QTYFROM AD_ATTRIBUTE_VALUE attributeValue,(SELECT TRANS_TIME,t.LOT_RRN,t.PART_NAME,row_number() over(partition by t.LOT_RRN order by TRANS_TIME DESC) rnFROM WIP_LOT_HIS t, WIP_WO wwWHERE t.TRANS_TYPE = 'TRACKIN'AND t.STEP_NAME = 'STEP_HX'AND ww.WORKSHIP = '1') t2,MM_MATERIAL t3WHERE attributeValue.TARGET_OBJECT_RRN = t2.LOT_RRNAND t2.PART_NAME = t3.nameAND t2.rn = 1AND STATUS = 'Active'GROUP BY t2.TRANS_TIME, t3.SPEC3)WHERE to_char(CREATED, 'yyyy-mm-dd') = '2024-02-14') t2)where rownum <= :1
老样子 想拉sql monitor看一下执行情况和执行计划
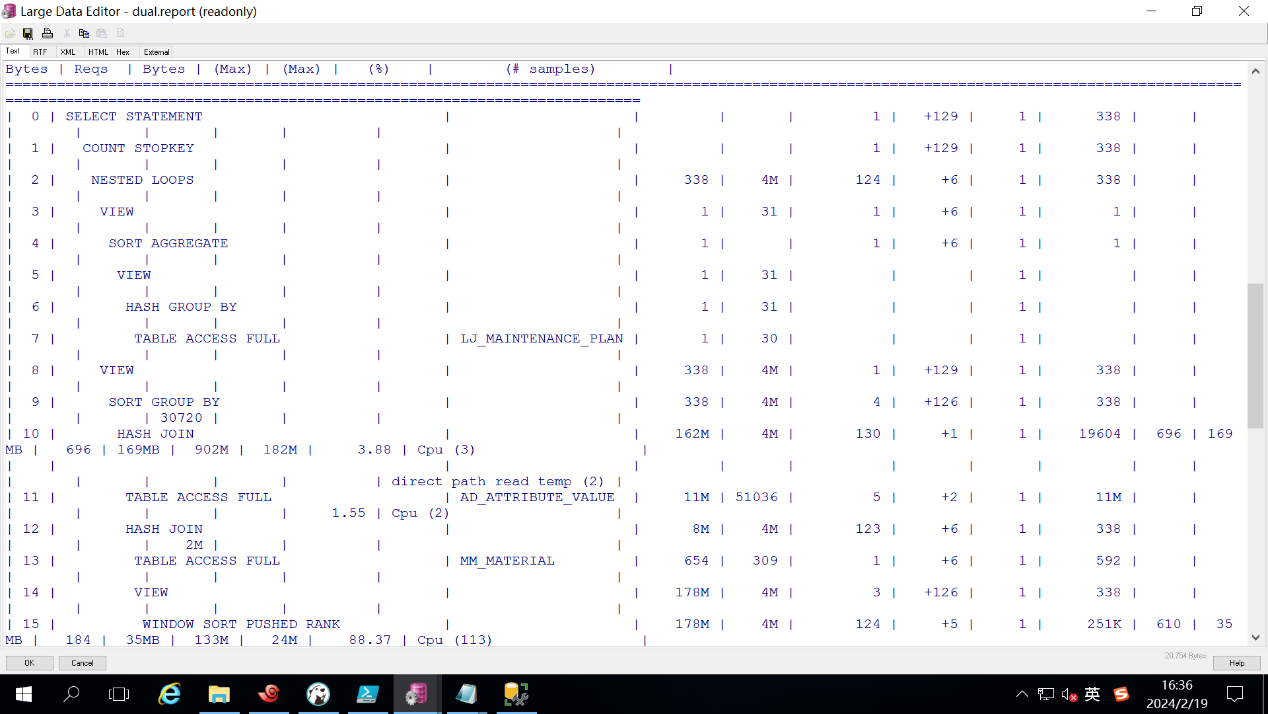
一步步来解决 尽可能吧full table scan的优化掉
LJ_MAINTENANCE_PLAN 看一下检索的三个条件和对应的数据分布
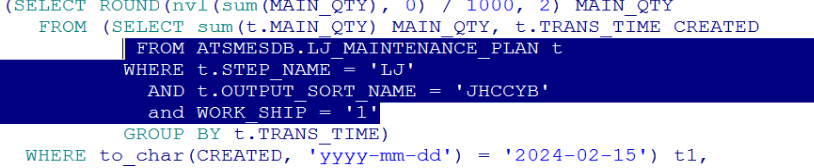
对应的数据分布
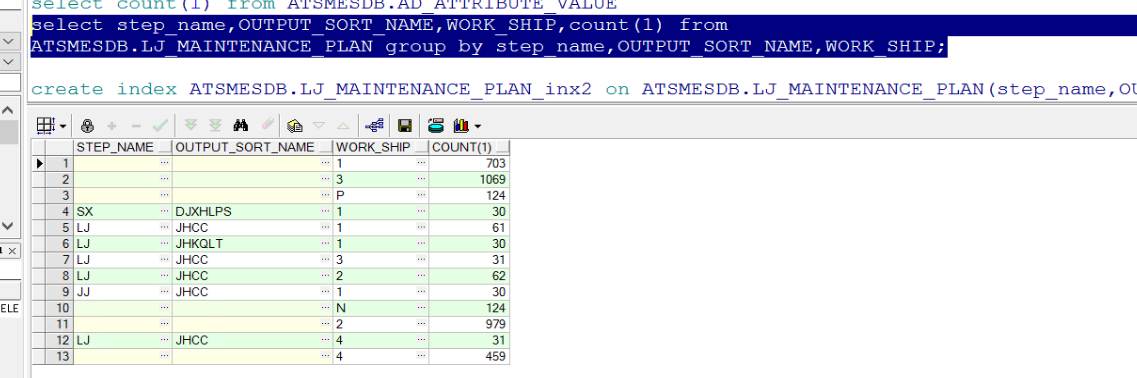
虽然数据量不大,但是三个条件在一起筛选度 还是可以的 , 很少量的数据落在三个参数都非空的位置上
而参数的数据都集中在这里,加上联合索引后看执行计划 ,有了明显改善

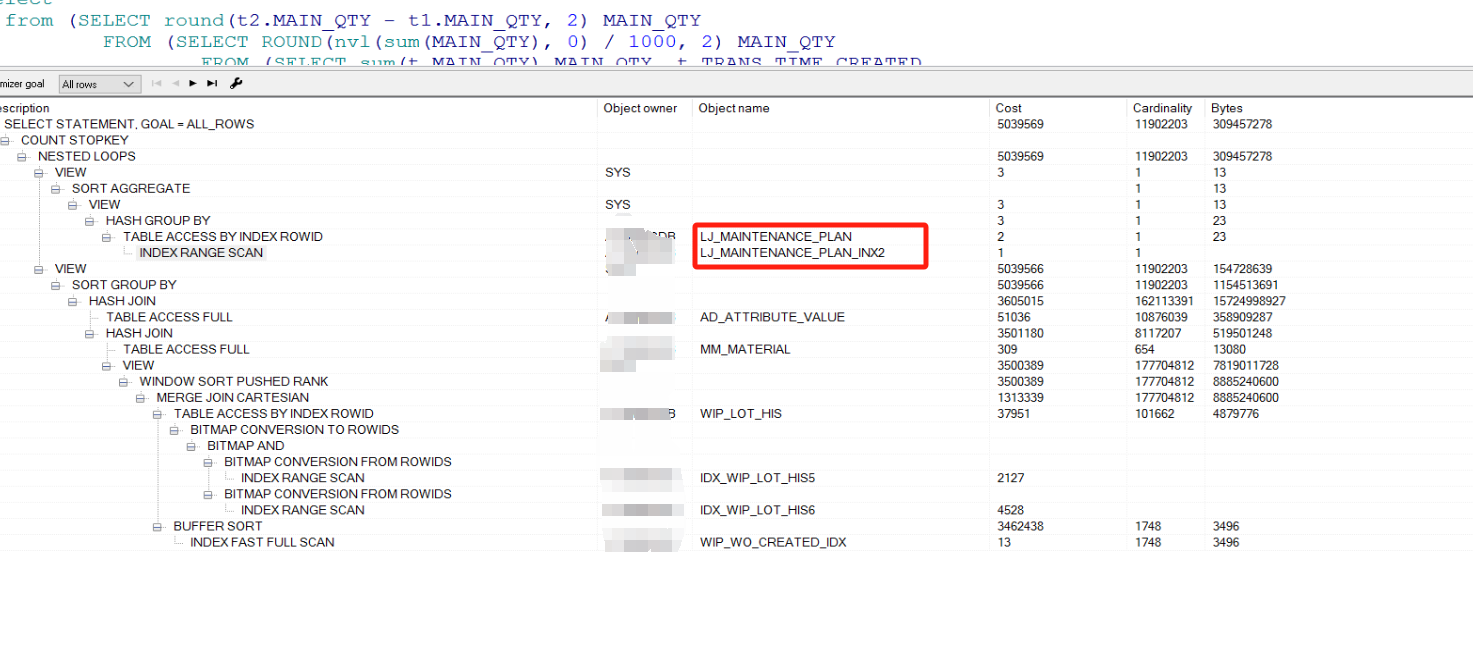
在自习观察这个sql 可以看出 筛选度最高的条件应该是最外围的
WHERE to_char(CREATED, 'yyyy-mm-dd') = '2024-02-14')
表连接的几个查询只有几个简单的筛选条件,导致查询的为几个大表的 hash join,cost非常看 如下图的执行计划
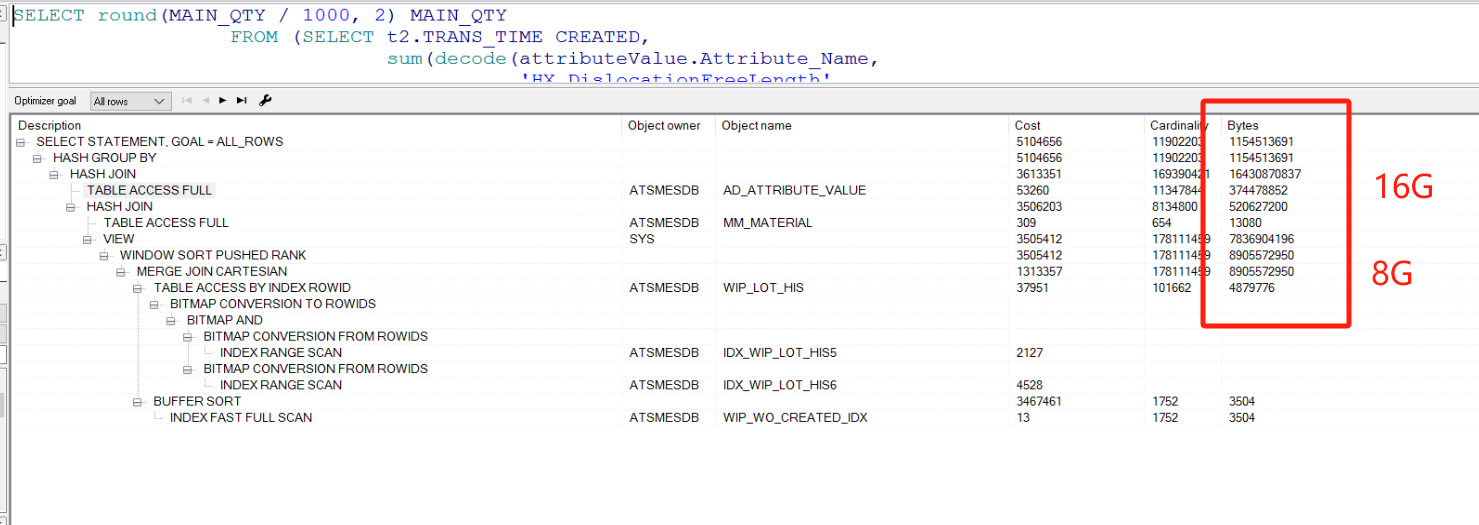
查看created 是来之t2.trans_time,如果将查询拿到子查询内 试试效果

对比执行计划 cost有100倍的缩小
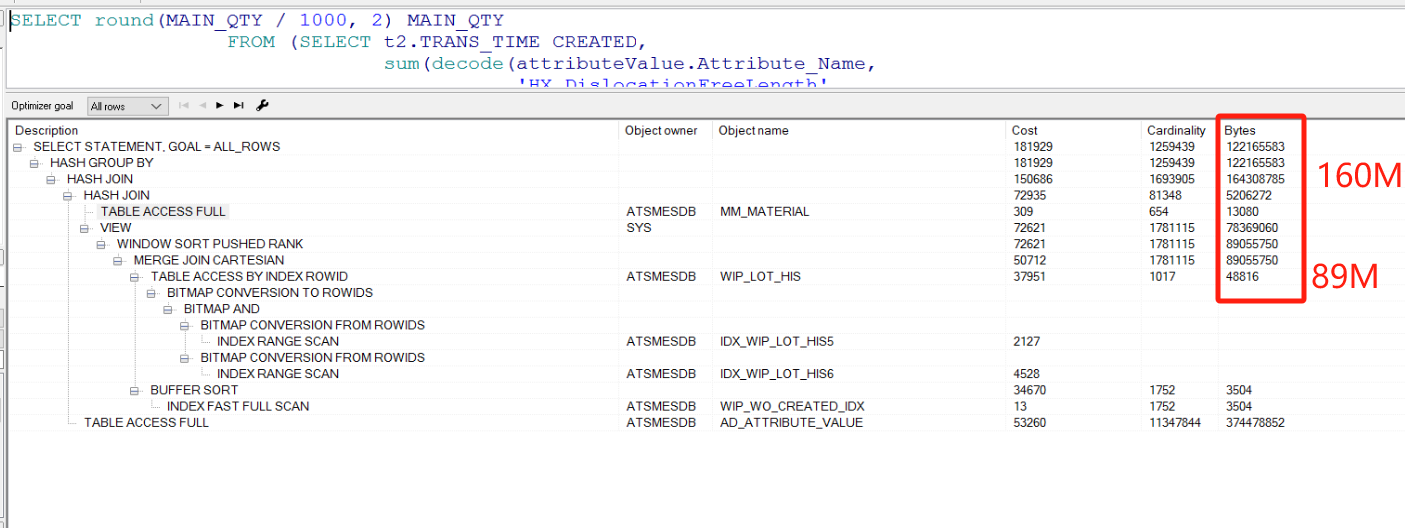
对比了原sql和 将条件拿到内部后 结果集一致的,执行时间由130秒缩短为3秒

因为涉及到需要修改代码,这部分只能邮件通知开发,来进行修改,并督促开发尽快绑定变量,减少硬解析的数量
后记: 数据库的优化 我个人总结的路径如下
以监控为引子(异常等待alert),通过OEM 监控平台总览数据库的状态,这时如果有明显的异常OEM 可以轻松看出
再通过AWR,ADDM,ASH等报表做更细致的分析,sql优化方面以后台优化为主(加索引),明显的sql代码问题,提出修改意见给开发
-------------------------------------------------------------------------------------
墨天伦,CSDN:潇湘秦 转载请注明出处
-------------------------------------------------------------------------------------
这篇关于如何优化一个看似正常的数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





