本文主要是介绍介绍 PIL+IPython.display+mtcnn for 音视频读取、标注,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. nn.NLLLoss是如何计算误差的?
nn.NLLLoss是负对数似然损失函数,用于多分类问题中。它的计算方式如下:首先,对于每个样本,我们需要将其预测结果通过softmax函数转换为概率分布。softmax函数可以将一个向量映射为一个概率分布,使得所有元素的和为1。然后,我们将真实标签表示为一个one-hot向量,其中只有正确类别的位置为1,其他位置为0。接下来,我们将预测结果与真实标签进行对数概率的计算。对于每个样本,我们取预测结果中对应真实标签位置的对数概率。最后,我们将所有样本的对数概率求平均,并取其负值作为损失值。这个损失值表示了模型预测结果与真实标签之间的差异程度,越小表示模型的预测越准确。
2. python cv2有哪些常见函数
Python的OpenCV库(cv2)是一个广泛使用的计算机视觉库,提供了许多常见的函数和方法来处理图像和视频。
以下是一些常见的cv2函数:1. cv2.imread():用于读取图像文件。
2. cv2.imshow():用于显示图像窗口。
3. cv2.imwrite():用于保存图像文件。
4. cv2.cvtColor():用于颜色空间转换。
5. cv2.resize():用于调整图像大小。
6. cv2.flip():用于翻转图像。
7. cv2.rectangle():用于在图像上绘制矩形。
8. cv2.circle():用于在图像上绘制圆形。
9. cv2.line():用于在图像上绘制直线。
10. cv2.putText():用于在图像上绘制文本。这些只是cv2库中的一小部分函数,还有很多其他功能强大的函数可供使用。你可以根据具体需求查阅OpenCV官方文档以获取更详细的信息。
3. IPython是什么
IPython是一个交互式的Python解释器,它提供了许多增强的功能和工具,使得编写、调试和测试Python代码更加方便和高效。下面是一些IPython的使用例子:交互式编程:IPython提供了一个交互式的命令行界面,可以直接在命令行中输入Python代码并立即执行。这使得编写和测试代码变得非常快速和方便。自动补全:IPython具有自动补全功能,可以通过按下Tab键来自动补全代码。这对于记忆函数名、属性和变量名等非常有帮助,可以提高编码效率。内省功能:IPython允许通过在对象或函数名后面加上问号来获取相关的文档和源代码。这对于了解函数的使用方法和查看源代码非常有用。魔术命令:IPython提供了一些特殊的命令,称为魔术命令,可以执行一些特殊的操作。例如,%run命令可以运行外部Python脚本,%timeit命令可以测量代码的执行时间等。可视化支持:IPython支持在交互式环境中进行数据可视化,可以使用Matplotlib等库来绘制图表、图像等。Jupyter Notebook集成:IPython是Jupyter项目的一部分,可以与Jupyter Notebook无缝集成。
Jupyter Notebook是一个基于Web的交互式计算环境,可以在浏览器中编写和运行代码,并将代码、文本、图表等组合在一起形成可交互的文档。
- Example:
python test.py,then you can enter model IPython
# 导入IPython库
from IPython import embed# 定义一个函数
def greet(name):print(f"Hello, {name}!")# 在代码中插入embed()函数,进入IPython交互环境
embed()# 在交互环境中调用函数
greet("Alice")
then we can debug with previous variable
4. Utilizing Ipython to play mp3
- IPython和IPython.display分别是什么?
IPython是一个交互式的Python编程环境,它提供了比标准的Python shell更多的功能和便利性。
IPython支持代码自动补全、语法高亮、代码编辑、代码调试等功能,使得Python编程更加方便和高效。而IPython.display是IPython中的一个模块,它提供了一些用于在交互式环境中显示和操作多媒体对象的函数和类。
通过IPython.display,我们可以在IPython中展示图像、音频、视频、HTML、Markdown等多种格式的内容,
使得交互式编程更加丰富和直观。
to display image
😀:在Jupyter环境下才行,terminal fails!
from IPython.display import display,Image
from IPython import embed
import pandas as pd# 显示一个字符串
display('Hello, world!')# 显示一个 Pandas 数据框
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
display(df)# 显示一张图片
# from PIL import Image
img = Image(filename='ml1.jpg')
display(img)# 显示一段 HTML 代码
display('<h1>This is a heading</h1>')
😊result:

to play audio!
In IPython or jupyter notebook
from IPython.display import Audio
mmp3=r'./dance.mp3'
Audio(data=mmp3,autoplay=False)
mean2: by IPython.display.display
from IPython.display import Audio,displayaudio_file = r'dance.mp3' # 替换为你的音频文件路径
audio=Audio(audio_file)
display(audio)
💪TypeError: ‘module’ object is not callable means we call/transfer a module not a function
5. PIL
PIL(Python Imaging Library)是一个用于图像处理的Python库。它提供了丰富的图像处理功能,包括图像的打开、保存、裁剪、缩放、旋转、滤镜应用等。PIL库可以处理多种图像格式,如JPEG、PNG、BMP等。通过使用PIL库,开发者可以方便地对图像进行各种操作和处理。PIL库的主要功能由一组函数和类提供。其中一些常用的函数包括:Image.open():用于打开图像文件,并返回一个Image对象。
Image.save():用于将Image对象保存为图像文件。
Image.resize():用于调整图像的大小。
Image.rotate():用于旋转图像。
Image.crop():用于裁剪图像。
Image.filter():用于应用滤镜效果。
除了这些函数外,PIL库还提供了一些类,如Image类和ImageDraw类,用于更高级的图像处理操作
python那些操作需要PIL而cv2不行
一些常见的操作需要使用PIL(Python Imaging Library)而不是cv2(OpenCV)的操作包括:1. 图片的打开和保存:PIL可以直接使用`Image.open()`和`Image.save()`来打开和保存图片,而cv2则需要使用`cv2.imread()`和`cv2.imwrite()`来进行操作。2. 图片的缩放和剪裁:PIL提供了`Image.resize()`和`Image.crop()`来进行图片的缩放和剪裁,而cv2则需要使用`cv2.resize()`和`cv2.crop()`来进行操作。3. 图片的旋转和翻转:PIL提供了`Image.rotate()`和`Image.transpose()`来进行图片的旋转和翻转,而cv2则需要使用`cv2.warpAffine()`来进行操作。4. 图片的像素操作:PIL提供了许多用于像素级别操作的函数,如`Image.getpixel()`和`Image.putpixel()`,而cv2则没有直接相应的函数。5. 图片的滤镜和调整:PIL提供了一系列滤镜和调整图像颜色的函数,如`ImageFilter`和`ImageEnhance`模块,而cv2则没有直接相应的函数。值得注意的是,PIL和cv2都是非常强大的图像处理库,它们在不同的情况下都有各自的优势。因此,在选择使用哪个库时,需要根据具体的需求和情况来决定。
🧐Image的是什么对象
IPython.display.display() ⟹ \Longrightarrow ⟹Display a Python object in all frontends.
While, np.ndarray doesn’t belong to frontend objects,It must be transformed into PIL form
from PIL import Image
image = cv2.imread(img_name+'.jpg')
display.display(Image.fromarray(image),display_id=True)
or In np.ndarray form
import numpy as np
from PIL import Image# 创建一个numpy数组
array = np.diag(list(range(256)))# 将数组转换为PIL图像对象
image = Image.fromarray(array)# 显示图像
# image.show()
image.save('zero.png')
6. 如何用facenet_pytorch.mtcnn而不是mtcnn分割人脸图像,它是如何实现的
- 所有的图像在cv2中被读取为np.ndarray数组
from facenet_pytorch import MTCNN
import cv2
from IPython import display
from PIL import Image
# 初始化MTCNN模型
mtcnn = MTCNN()img_name='ml1'# 加载图像
image = cv2.imread(img_name+'.jpg')
# print(image)
cv2.imshow('image', image)# # 进行人脸检测和对齐
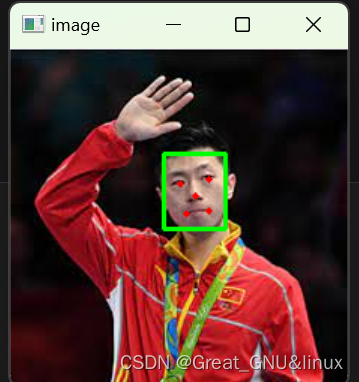
boxes, probs, landmarks = mtcnn.detect(image, landmarks=True)# 绘制人脸框和关键点
for box, landmark in zip(boxes, landmarks):cv2.rectangle(image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)for point in landmark:cv2.circle(image, (int(point[0]), int(point[1])), 2, (0, 0, 255), -1)display.display(Image.fromarray(image),display_id=True)
display.display(Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)),display_id=True)print(type(image))
# display.display(Image.fromarray(image))# # 显示结果图像
cv2.imshow('image', image)
cv2.waitKey(0)
cv2.imwrite(img_name+'detect.jpg',image)
cv2.destroyAllWindows()
Notebook显示结果:

😊(savior)cv2.cvtColor(image, cv2.COLOR_BGR2RGB):
这段代码的作用是将一张图像从BGR颜色空间转换为RGB颜色空间。
- IPython.display.display()(显示在IPython交互中)采用RGB空间,cv2默认采用BGR空间

cv2.imshow()的结果正常:
7.How to use resnet storage for face recongnization?
- python mmcv 的用途
是的,mmcv库依赖于numpy。numpy是Python中用科学计算的一个重要库,提供了高效的多维数组对象和对这些数组进行操作的函数。mmcv库是用于计算机视觉任务的工具包,它提供了许多常用的计算机视觉函数和工具,如图像处理、数据增强、模型评估等。在mmcv库中,很多函数和类都需要使用numpy数组进行输入和输出。因此,在使用mmcv库之前,需要先安装并导入numpy库。mmcv是一个用于计算机视觉任务的开源工包,它是基于Python语言开发的。mmcv提供了丰富的计算机视觉相关的函数和类,可以帮助开发者更高效地进行图像和视频处理、模型训练和评估等任务。具体来说,mmcv在以下几个方面有着广泛的应用:1. 数据处理:mmcv提供了一系列用于数据加载、预处理和增强的函数和类,可以方便地处理图像和视频数据,包括读取、裁剪、缩放、翻转、旋转等操作。2. 模型构建:mmcv支持常见的计算机视觉模型的构建,包括各种经典的卷积神经网络(如ResNet、VGG等),以及一些新颖的模型结构(如HRNet、YOLO等)。开发者可以使用mmcv提供的接口来构建自己的模型。3. 训练和评估:mmcv提供了训练和评估模型的工具,包括优化器、学习率调整策略、损失函数等。开发者可以使用mmcv提供的接口来方便地进行模型训练和评估,并得到相应的性能指标。4. 工具函数:mmcv还提供了一些实用的工具函数,用于计算机视觉任务中常见的操作,如计算IoU(交并比)、绘制曲线、保存模型等。总之,mmcv是一个功能强大的计算机视觉工具包,可以帮助开发者更高效地进行图像和视频处理、模型构建、训练和评估等任务。
这篇关于介绍 PIL+IPython.display+mtcnn for 音视频读取、标注的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




