本文主要是介绍ShardingJDBC分库分表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
ShardingSphere
ShardingJDBC客户端分库分表
ShardingProxy服务端分库分表
两者对比
ShardingJDBC分库分表实战
需求
步骤
分片策略汇总
ShardingSphere
ShardingSphere最为核心的产品有两个:一个是ShardingJDBC,这是一个进行客户端分库分表的框架。另一个是ShardingProxy,这是一个进行服务端分库分表的产品。他们代表了两种不同的分库分表的实现思路。
ShardingJDBC客户端分库分表
ShardingSphereJDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
ShardingProxy服务端分库分表
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
两者对比
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
ShardingJDBC分库分表实战
需求
将course表分到coursedb,coursedb2两个库, 两个库分别有course_1, course_1表, 总共四张表
步骤
1. 搭建开发环境SpringBoot+MyBatis+MyBatis-plus
2. 去数据库建真实库表
-- 建库
CREATE DATABASE `coursedb` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';CREATE TABLE `coursedb`.`course_1` (`cid` bigint(0) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(0) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;CREATE TABLE `coursedb`.`course_2` (`cid` bigint(0) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(0) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- 建库
CREATE DATABASE `coursedb2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';CREATE TABLE `coursedb2`.`course_1` (`cid` bigint(0) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(0) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;CREATE TABLE `coursedb2`.`course_2` (`cid` bigint(0) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(0) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;3. 引入ShardingJDBC maven依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.2.1</version><exclusions><exclusion><artifactId>snakeyaml</artifactId><groupId>org.yaml</groupId></exclusion><exclusion><artifactId>cosid-core</artifactId><groupId>me.ahoo.cosid</groupId></exclusion></exclusions></dependency>5. 修改配置文件。 设置分片策略, 分片键. 这里使用单一分片键
# 打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true# ----------------数据源配置
# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=3cNp1la?yw%wspring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=3cNp1la?yw%w
#------------------------分布式序列算法配置
# 雪花算法,生成Long类型主键。
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker.id=1
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.column=cid
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.key-generator-name=alg_snowflake
#-----------------------配置实际分片节点 m0.course_1,m0.course_2 ,m1.course_1,m1.course_2
spring.shardingsphere.rules.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
#MOD分库策略
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-algorithm-name=course_db_algspring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.props.sharding-count=2
#给course表指定分表策略 standard-按单一分片键进行精确或范围分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-algorithm-name=course_tbl_alg# 分表策略-INLINE:按单一分片键分表
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=INLINE
# 允许在inline策略中使用范围查询。
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.allow-range-query-with-inline-sharding=true
# 均匀分布到4张表
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{(cid%4).intdiv(2)+1}6. 插入数据测试
@Testpublic void addcourse() {for (int i = 0; i < 10; i++) {Course c = new Course();c.setCid(i + 0L);c.setCname("java");c.setUserId(1001L);c.setCstatus("1");courseMapper.insert(c);}}7. 验证分库分表效果
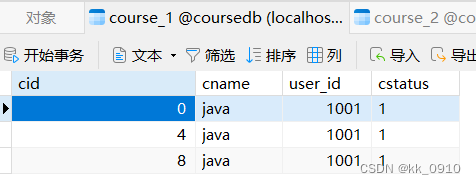

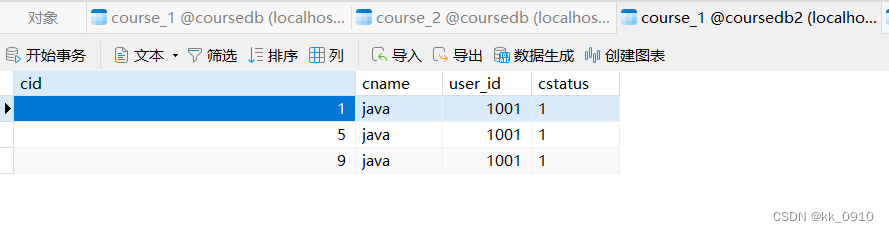

分片策略汇总
- INLINE简单分片
- STANDARD标准分片(范围查询)
- COMPLEX_INLINE复杂分片(多分片键)
- CLASS_BASED自定义分片 (自定义分片策略)
- HINT_INLINE强制分片算法 (不关心sql)
这篇关于ShardingJDBC分库分表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!