本文主要是介绍mongodb搭建校内搜索引擎——内容查询与排序2.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标:
针对mongodb搭建校内搜索引擎——内容查询与排序1.0进行改进
概要:
在已经存储好数据的情况下,运用BM25算法对查询的语句和网页的相关度进行相关度的计算。在实践中运用BM25算法,从1.0版本到2.0版本大大提高的查询的速度,普遍提高了1个量级,有些情况下可以优化提速两个量级。优化基于查询相关度计算,使整体运行速度加快。
实现过程:
版本2.0及思考:
在版本1.0的情况下,我的问题出在获得的url列表过大,导致计算的数目过多,并且在计算相关度时,对词语和url相关度的计算需要动态获得。解决办法是改变数据库的结构,使得词语与url的相关度可以事先计算好,静态存储然后直接调用(前提是对算法准确,不会修改,副作用是大量数据更新耗时),然后设置相应的阈值,如果词语“南京大学”在我获得的url中相关度最高是2.0,那么我选择提取相关度与“南京大学”相关且大于2.0/10(这里的阈值可以动态调整),可以大致想象,对排序前面的结果无影响(结果如此),而且大大加快运行速度。
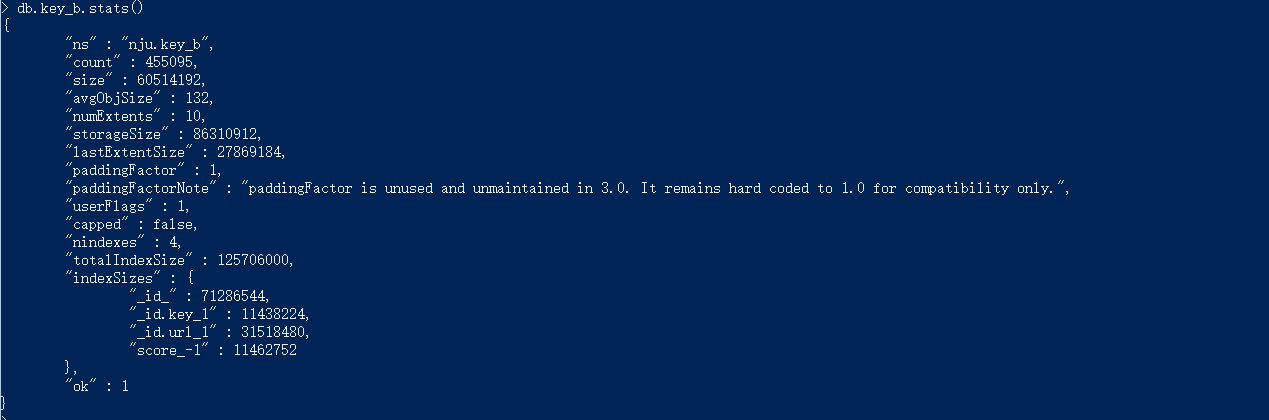
版本2.0的数据库结果如下:

复合的id 中url是链接,key是关键词,score是相关度,相对于1.0的数据库结果,将其打散,同时对url,key,score分别建立索引,副作用是更新会更慢。
数据库的情况如下:
代码如下:
import pymongo
import time
import jieba
import jieba.analyse
import sys
from functools import wraps
reload(sys)
sys.setdefaultencoding("utf-8")
setence=sys.argv[1]connection=pymongo.MongoClient("mongodb://localhost")
db=connection.nju
key=db.key_bdef fn_timer(function): #计算时间@wraps(function)def function_timer(*args, **kwargs):t0 = time.time()result = function(*args, **kwargs)t1 = time.time()print ("Total time running %s: %s seconds" %(function.func_name, str(t1-t0)))return resultreturn function_timer@fn_timer #计算时间
def cut(setence): #对用户输入的语句切分#list=jieba.lcut_for_search(setence)list=jieba.lcut(setence)return list@fn_timer
def score_limit(list): #计算score 的阈值,用来减少url的数目score_list=[]for word in list:
result=key.find({"_id.key":word}).sort("score",-1).limit(1)#获得单个词语在列表中的最大相关度if result==None:#如果词语查询不存在,输出使可见并删除print "word:%s is None"%wordlist.remove(word)else:for doc in result:score_list.append(doc["score"])print max(score_list)return max(score_list) #获得所有查询词语中与url相关度最高的词语@fn_timer
def find(score_limit,list):#进行查询result_list=[]url_list=[]for word in list:cursor=key.find({"_id.key":word,"score":{"$gte":score_limit}}) #查询if cursor==None:print "word:%s is None"%wordlist.remove(word)else:for doc in cursor:i=doc["_id"]url_list.append(i["url"])for url in url_list:cursor=key.aggregate([{"$match":{"_id.url":url,"_id.key":{"$in":list}}},{"$group":{"_id":url,"score":{"$sum":"$score"}}}],cursor={},allowDiskUse=True) #对一个url与语句的相关度计算for doc in cursor:result_list.append({"url":doc["_id"],"score":doc["score"]})return result_list #标准化输出def exchange(list,a,b): #排序-交换temp_0=list[a]["url"]temp_1=list[a]["score"]list[a]["url"]=list[b]["url"]list[a]["score"]=list[b]["score"]list[b]["url"]=temp_0list[b]["score"]=temp_1def partition(list,lo,high):排序-快速排序j=highv=list[lo]["score"]i=lo+1while True:while (v>=list[i]["score"]):if i==j:breaki+=1while (list[j]["score"]>=v):if j==i:breakj-=1if i>=j:breakexchange(list,i,j)if i==j+1:exchange(list,lo,j)return jelif list[j]["score"]>v:exchange(list,lo,j-1)return j-1else:exchange(list,lo,j)return jdef insert_sort(list,lo,hi):排序—插入排序i=lowhile i<hi:j=i+1while j>lo:if list[j]["score"]<list[j-1]["score"]:exchange(list,j,j-1)j-=1i+=1def quick_sort(list,lo,hi): #list过长用快速排序,较短时用插入排序if hi<lo+10:insert_sort(list,lo,hi)else:j=partition(list,lo,hi)quick_sort(list,lo,j-1)quick_sort(list,j+1,hi)
list=[]
result_list=[]list=cut(setence)
score_limit=1.0*score_limit(list)/2
result_list=find(score_limit,list)lo=0
hi=len(result_list)
quick_sort(result_list,lo,hi-1)
for i in result_list:print i
print len(result_list)反思:
- 数据的更新代价太大,45万条数据更新会出现错误:com.mongodb.MongoException$CursorNotFound: cursor 0 not found on server,理想情况下是两个小时更新完数据,所以更新一半出错,内心会很奔溃
- 想法朴素,对于阈值的设立没有理论依据,可能会有问题,不过目前表现良好,可以使计算相关度的时间控制在一秒左右,对于项目而言,差强人意,而且可以进一步简单调整阈值使变大,可以在0.2秒左右。
- 对分词的耗时依旧没有解决
- 查询的结果没有改进,依旧是查询输入越多越准确
这篇关于mongodb搭建校内搜索引擎——内容查询与排序2.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







