本文主要是介绍mongodb搭建校内搜索引擎——内容查询与排序1.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标:
对已经存储好的数据进行查询,比如说我想查询”计科2015年研究生录取名单“,那么我想要的得到一系列的网页链接,其中前几个的网页中必须是得包含我需要的内容。
概要:
在已经存储好数据的情况下,运用BM25算法对查询的语句和网页的相关度进行相关度的计算。在实践中运用BM25算法,从1.0版本到2.0版本大大提高的查询的速度,普遍提高了1个量级。
实现过程:
版本1.0及其思考:
根据BM25算法,我首先将查询的语句进行分词,然后对词语映射到的链接取并集,然后对分别的连接进行进行与查询的相关度的计算。
相应的数据库的结构如下:
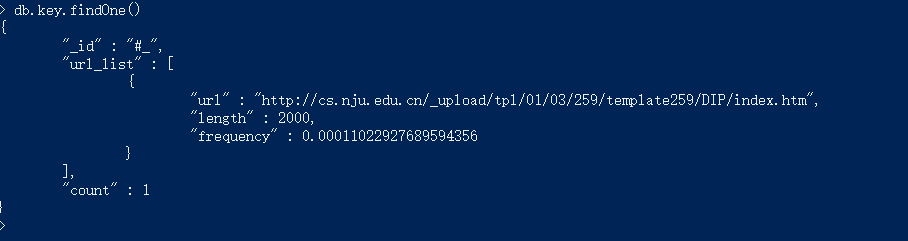
“_id”存储的是关键词,”url_list “存储的是包含此关键词的网页链接和这个网页的文本长度以及这个词在文本中的频率,”count”存储的是这个词在多少网页中出现,即“url_list “中的元素个数。
其中所含数据皆为我校计算机系到目前为止的数据。在这个版本中,我没有为集合key创建索引,数据库集合的情况如下:

代码如下:
import math
import pymongo
import sys
import jieba
import jieba.analyse
import cProfile
import time
from functools import wraps
reload(sys)
sys.setdefaultencoding("utf-8")
setences=sys.argv[1]
connection=pymongo.MongoClient("mongodb://localhost")
db=connection.nju
key=db.keydef fn_timer(function):#用于计算时间,方便有目的优化@wraps(function)def function_timer(*args, **kwargs):t0 = time.time()result = function(*args, **kwargs)t1 = time.time()print ("Total time running %s: %s seconds" %(function.func_name, str(t1-t0)))return resultreturn function_timer@fn_timer #计算时间,并运行函数
def cut(setence): #对用户输入的查询进行分词list=jieba.lcut(setence)return listdef add_score(N,ni,fi,dl,avdl): #计算相关度,运用的是BM25算法k1=1.2b=0.45K=k1*((1-b)+1.0*b*dl/avdl)score_first=math.log((N/(ni+1.0)),10)score_second=(k1+1)/(K+fi)*fiscore=score_first*score_second*100return score@fn_timer
def calculate(list_ask,list_result): #查询数据库得到需要的参数,并调用add_score计算相关度list_url=[]for words in list_ask:ask_get=key.find_one({"_id":words}) #获得相关的urlprint wordsif ask_get==None: #因为分词并不准确或者用户输入新词,那么输出使之能被观测print words," :None"else:example_list=ask_get["url_list"]for j in example_list: #need youhuaif j in list_url: #添加url到列表,如果列表中已经有此链接,不在添加passelse:list_url.append(j["url"])for k in list_url: #对url和链接的相关度进行打分key_score=0# print key_scorefor words in list_ask:ask_get=key.find_one({"_id":words})if ask_get==None:pass#print words," :None"else:ni=ask_get["count"]example_list=ask_get["url_list"]fi=0dl=0for j in example_list:# print group_kid["url"]if j["url"]==k:fi=j["frequency"]dl=j["length"]breakkey_score=key_score+add_score(N,ni,fi,dl,avdl)list_result.append({"url":k,"score":key_score}) #将结果保存下来,结构化输出return list_resultdef exchange(list,a,b):#排序-交换temp_0=list[a]["url"]temp_1=list[a]["score"]list[a]["url"]=list[b]["url"]list[a]["score"]=list[b]["score"]list[b]["url"]=temp_0list[b]["score"]=temp_1def partition(list,lo,high):排序-快速排序j=highv=list[lo]["score"]i=lo+1while True:while (v>=list[i]["score"]):if i==j:breaki+=1while (list[j]["score"]>=v):if j==i:breakj-=1if i>=j:breakexchange(list,i,j)if i==j+1:exchange(list,lo,j)return jelif list[j]["score"]>v:exchange(list,lo,j-1)return j-1else:exchange(list,lo,j)return jdef insert_sort(list,lo,hi):排序-插入排序i=lowhile i<hi:j=i+1while j>lo:if list[j]["score"]<list[j-1]["score"]:exchange(list,j,j-1)j-=1i+=1def quick_sort(list,lo,hi): #排序的策略是列表长度>10时,用快排,列表长度<10时用插入排序if hi<lo+10:insert_sort(list,lo,hi)else:j=partition(list,lo,hi)quick_sort(list,lo,j-1)quick_sort(list,j+1,hi)N=2465
avdl=184.6
list_ask=cut(setences)
list_result=[]
list_result=calculate(list_ask,list_result)
lo=0
hi=len(list_result)
print hi
quick_sort(list_result,lo,hi-1)
for i in list_result:print i
print len(list_result)反思:
- 当返回结果过多时,计算模块def calculate(list_ask,list_result):耗时线性递增,最夸张的一次测试是查询返回结果返回2000多条,耗时60多分钟,完全不可接受,还有导致快速排序递归调用次数过多,报错:RuntimeError: maximum recursion depth exceeded
- 结巴分词模块导入时间要6秒左右,对用户查询切分要2秒左右,耗时较多
- 结果并不理想,但是用户输入的词语越多,越准确,但是是缺少语义上的处理,纯属概率模型
推荐:mongodb搭建校内搜索引擎——内容查询与排序2.0
这篇关于mongodb搭建校内搜索引擎——内容查询与排序1.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






