本文主要是介绍Web搜寻网站的多个网页,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
“Getting information off the internet is like taking a drink from a fire hose.” — Mitchell Kapor
“从互联网上获取信息就像从消防水带上喝一杯。” —米切尔·卡波(Mitchell Kapor)
A data scientist must go through the pain of finding data. But just finding the data isn’t enough, there are changes that must be made to the data so that it can be used for practical purposes. But is data easily available?
数据科学家必须经历寻找数据的痛苦。 但是仅仅找到数据是不够的,必须对数据进行更改,以便将其用于实际目的。 但是数据容易获得吗?
不,不是。 (No,it isn’t.)
In this article, i will show you how challenging it can be to gather data. We will also learn how to deal with such problems.
在本文中,我将向您展示收集数据的挑战 。 我们还将学习如何处理此类问题。
Before we jump to the problem, let us first understand the difference between a static website and a dynamic website. You might have noticed while going through your twitter feed as you scroll down, the tweets are loaded without the webpage being reloaded. How does this happen?
在跳到问题之前,让我们首先了解静态网站和动态网站之间的区别。 向下滚动浏览Twitter提要时,您可能已经注意到,加载了这些推文而没有重新加载该网页。 这是怎么发生的?
This happens because Twitter is a dynamic website. Dynamic website uses client-side scripting or server-side scripting, or both to generate dynamic content. To know more click here
发生这种情况是因为Twitter是一个动态网站。 动态网站使用客户端脚本或服务器端脚本,或同时使用两者来生成动态内容。 要了解更多,请点击这里
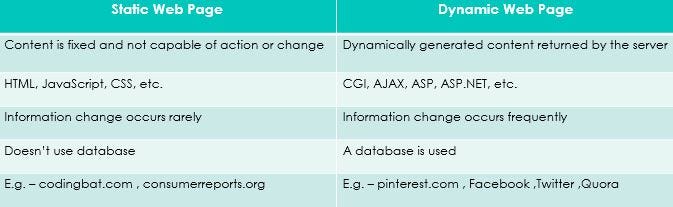
问题: (Problem :)
CodingBat is a website of live coding problems to build coding skill in Java and Python. CodingBat is a static website, which means it is easier to scrape data from but the challenge is different here!!
CodingBat是一个实时编码问题的网站,旨在培养Java和Python的编码技能。 CodingBat是一个静态网站,这意味着从中抓取数据更容易,但是这里的挑战不一样!!
Data Required: For all the coding enthusiasts, I wish to scrape all the java questions from all the sub-topics on the website.
所需数据 :对于所有编码爱好者,我希望从网站上所有子主题中删除所有Java问题。
Let’s see how the website looks like.
让我们看看网站的外观。
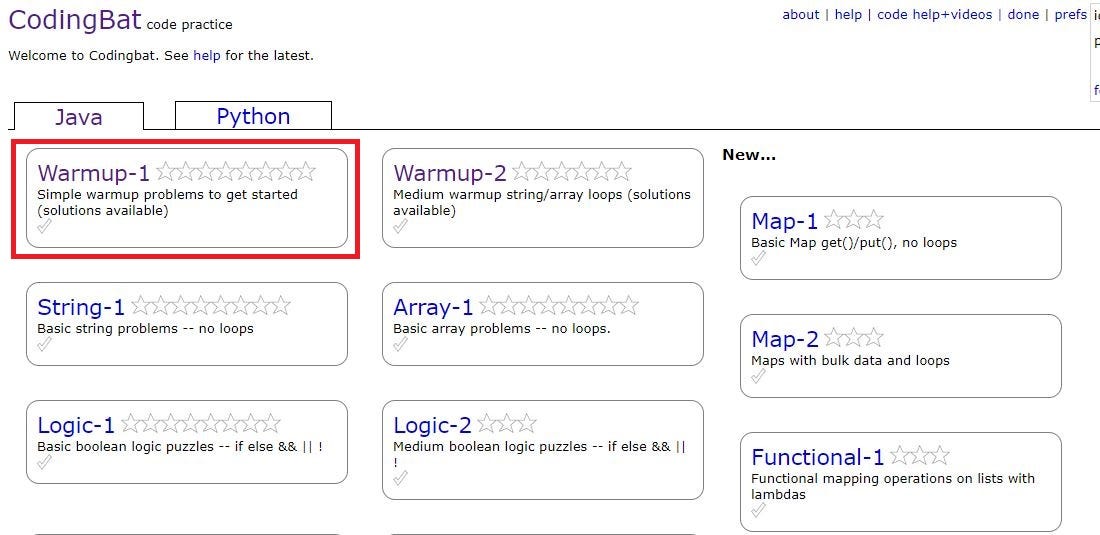
As you can see in the above picture, Java section has many subtopics, so lets click on the first one and see where this takes us.Hopefully to questions :)
如上图所示,Java部分包含许多子主题,因此让我们单击第一个子主题,看看它将我们带到何处。
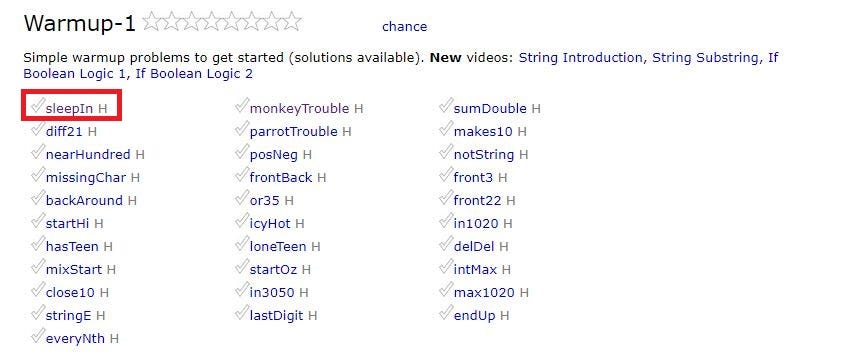
So we land up in a page of a another set of topics !! Let us see where the first link “sleepIn” takes us.
因此,我们进入了另一组主题的页面! 让我们看看第一个链接“ sleepIn”将我们带到何处。

So finally we arrive on the webpage which has a question. But this is just one question. What can we do to get other java related questions? Should we scrape them one by one ? That’s a tedious task. Web Scraping is meant to collect huge amounts of data at once and make our life easier. But we don't see that happening here. Don’t loose hope !!
所以最后我们到达了一个有疑问的网页。 但这只是一个问题。 我们如何做才能得到其他与Java相关的问题? 我们应该一头一刮吗? 那是一个乏味的任务。 Web Scraping旨在一次收集大量数据,并使我们的生活更轻松。 但是我们看不到这种情况发生。 不要失去希望!
挑战: (The challenge :)
Every time we wish to scrape data from a website, it is not necessary that we get the data in a single web page, like in a Wikipedia table. We might have to hop to different links on the website only to find that the data we need is present only in a small amount, which is useless.
每当我们希望从网站上抓取数据时,就不必像在Wikipedia表中那样在单个网页中获得数据。 我们可能不得不跳到网站上的其他链接,只是发现我们所需的数据仅少量存在,这是无用的。
Please understand that the above example was chosen only to highlight one of many problems that you encounter while web scraping. But, it must be tackled.
请理解,选择上面的示例只是为了突出您在网络抓取时遇到的许多问题之一。 但是,必须解决它。
解决方案 : (The solution :)
You need to have some basic knowledge of HTML pages to understand web scraping. We also need some python libraries like BeautifulSoup & Requests .
您需要具备HTML页面的一些基本知识才能了解网络抓取。 我们还需要一些Python库,例如BeautifulSoup & 请求 。
Let’s now understand the steps involved to scrape data from multiple webpages on a website.
现在,让我们了解从网站上的多个网页抓取数据所涉及的步骤。
Install BeautifulSoup and import necessary libraries : pip install beautifulsoup4 (Go to the terminal and use this pip command to install it)
安装BeautifulSoup并导入必要的库 :pip install beautifulsoup4(转到终端并使用此pip命令进行安装)
Save the HTML content of the website in a text file : When scraping a static website, saving its html content in a file is better as you can request for a page only a limited number of times. Once you have the HTML code saved in a text file, it can be used infinitely for scraping instead of making a call to the website multiple times.
将网站HTML内容保存在文本文件中 :抓取静态网站时,将其html内容保存在文件中会更好,因为您可以只请求有限次数的页面。 将HTML代码保存在文本文件中后,就可以将其无限次用于抓取,而不必多次致电网站。
# import libraries
from bs4 import BeautifulSoup
import requestsurl = 'https://codingbat.com/java'
file_name = 'pagesource.txt' #with keyword- automatically closes the file
page = requests.get(url)
with open(file_name,'w') as file:
file.write(page.content.decode('utf-8')) if type(page.content) == bytes else file.write(page.content)This is how the text files looks like :
这是文本文件的外观:

3. Define a function to read the text file :
3. 定义一个读取文本文件的函数:
#define a fucntion to read a file
def read_file():
file = open('pagesource.txt')
data = file.read()
file.close()
return data4. Extract links to all subtopics in Java section using BeautifulSoup : Let’s “Inspect” the CodingBat website to find where the links to subtopics are present.
4. 使用BeautifulSoup提取到Java部分中所有子主题的链接 :让我们“检查” CodingBat网站以找到子主题链接的位置。
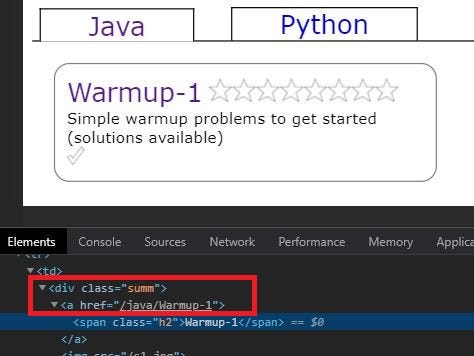
It is clear from the above figure that the link is present inside the <div> tag whose class attribute value is “summ”. Also notice the href attribute of the <a> tag. Its a partial link. So we need to concatenate the base URL of the website with this href value so as to form the proper link.
从上图可以清楚地看出,链接存在于<div>标记内,其类别属性值为“ summ”。 还要注意<a>标记的href属性。 它是部分链接。 因此,我们需要使用该href值连接网站的基本URL,以形成正确的链接。
soup = BeautifulSoup(read_file(), 'html.parser')
base_url = 'https://codingbat.com'
urls = soup.find_all('div', class_='summ')# Extracting the href attribute of "<a>" which is the first child of the <div> tag
main_links = [div.a['href'] for div in urls]# Append links in a list
new_links = []
for links in main_links:
out_links = base_url + links
new_links.append(out_links)
print(*new_links,sep="\n")5. Extracting sub-links : Now we have the links to each subtopic, but each sub-topic further contains the links to several questions. So the next task is to extract the links to each and every question belonging to each sub-topic.But first lets see where the link to each question is stored in the HTML content.
5. 提取子链接 :现在我们有每个子主题的链接,但是每个子主题还包含一些问题的链接。 因此,下一个任务是提取与每个子主题相关的每个问题的链接,但是首先让我们看看每个问题的链接在HTML内容中的存储位置。
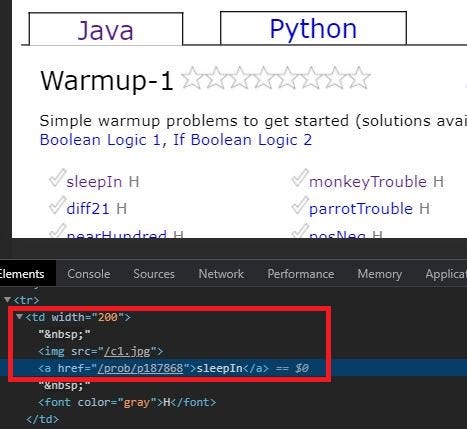
#PART-2-EXTRACTING SUB-LINKS
main_firstlinks = []# for the links to questions in each sub-topic
for i in new_links:
curr_link = i
#print(curr_link, "\n")
response = requests.get(curr_link)
html = response.text
soup = BeautifulSoup(html, 'lxml')
first_links = soup.find_all('td', width="200")
for mfl in first_links:
half_links = mfl.a['href']
out_links1 = base_url + half_links
main_firstlinks.append(out_links1)
print(*main_firstlinks, sep="\n")6. Extracting questions : Finally we attempt to scrape all the questions from all the links. Let’s see where the question is stored in the HTML content.
6. 提取问题 :最后,我们尝试从所有链接中抓取所有问题。 让我们看看问题在HTML内容中的存储位置。
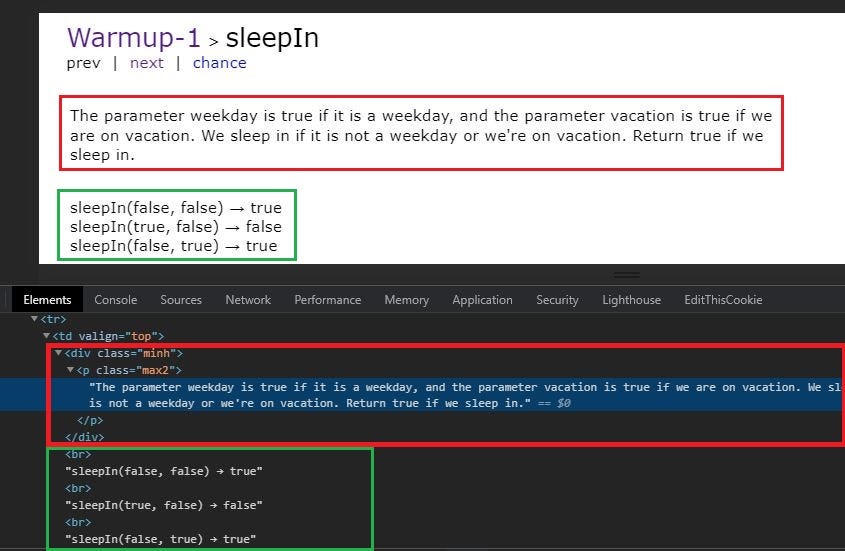
Observe that there are two parts of the question, the statement and the functions. The statement part is stored in table->div->p.
注意问题有两个部分,语句和函数。 语句部分存储在table-> div-> p中。
The function part is a sibling of the <div> tag . To know how we can navigate sideways in BeautifulSoup refer to the BeautifulSoup Documentation
功能部分是<div>标签的同级元素。 要了解我们如何在BeautifulSoup中横向浏览,请参阅BeautifulSoup文档
#PART -3- EXTRACTING ALL QUESTIONS#
for k in main_firstlinks:
# new_link=main_firstlinks[k]
new_response = requests.get(k)
new_data = new_response.text
soup = BeautifulSoup(new_data, 'lxml')
p = soup.find('div', class_="indent")
para_text = p.table.div.string
# print(para_text)
print("Question: ", para_text) rest = p.table.div.next_siblings
for sibling in rest:
if sibling.string is not None:
print(sibling.string)
print("\n\n")Output :
输出 :

This is only a sample of four questions from the output obtained. So you see how challenging it can be to collect data ? However, now you know what to do when you face a similar situation while scraping data from a static website.
这只是从输出中获得的四个问题的样本。 因此,您知道收集数据有多么艰巨吗? 但是,现在您知道在从静态网站抓取数据时遇到类似情况时该怎么办。
Refer to my GitHub Code
请参阅我的GitHub代码
Note : All the resources that you will require to get started have been mentioned and their links provided in this article as well. I hope you make good use of it :)
注意 :已经提到了您将需要的所有资源,本文还提供了它们的链接。 我希望你能好好利用它:)
I hope this article will get you interested in trying out new things like web scraping and help you add to your knowledge. Don’t forget to click on the “clap” icon below if you have enjoyed reading this article. Thank you for your time.
希望本文能使您对尝试新功能(例如网络抓取)感兴趣,并帮助您增加知识。 如果您喜欢阅读本文,请不要忘记单击下面的“拍手”图标。 感谢您的时间。
翻译自: https://medium.com/analytics-vidhya/web-scraping-multiple-webpages-of-a-website-1354040b7cba
相关文章:
这篇关于Web搜寻网站的多个网页的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








