本文主要是介绍【域适应论文汇总】未完结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- DANN:Unsupervised Domain Adaptation by Backpropagation (2015)
- TADA:Transferable Attention for Domain Adaptation(2019 AAAI)
- 1 局部注意力迁移:Transferable Local Attention
- 2 全局注意力迁移:Transferable Global Attention
- DAN:Learning transferable features with deep adaptation networks(JMLR 2015)
- 1 多层自适应
- 2 多核自适应
- 3 CNN经验误差
- 4 优化目标
- 5 learning Θ Θ Θ
- 6 learning β β β
- ADDA:Adversarial discriminative domain adaptation(CVPR 2017)
- 1 报错
- 2 代码
- 3 判别器
- 4 分类器
- 5 adapt
- MCD:Maximum classifier discrepancy for unsupervised domain adaptation(CVPR 2018)
- MDD:Bridging theory and algorithm for domain adaptation
- CDAN:Conditional Adversarial Domain Adaptation(Neural 2018)
- MCC:Moment Matching for Multi-Source Domain Adaptation(ICCV 2019)
- DAPL:Domain Adaptation via Prompt Learning(DA+prompt)(arXiv 2022)
- 特征提取器优化
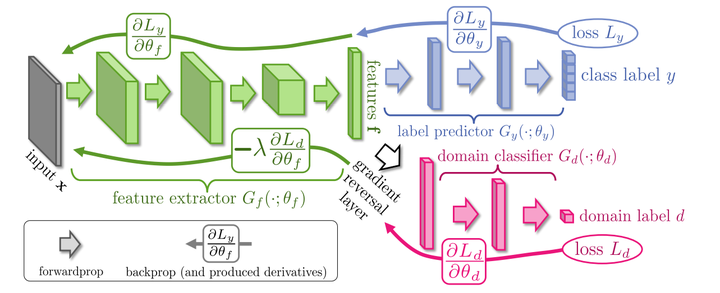
DANN:Unsupervised Domain Adaptation by Backpropagation (2015)
提出DANN
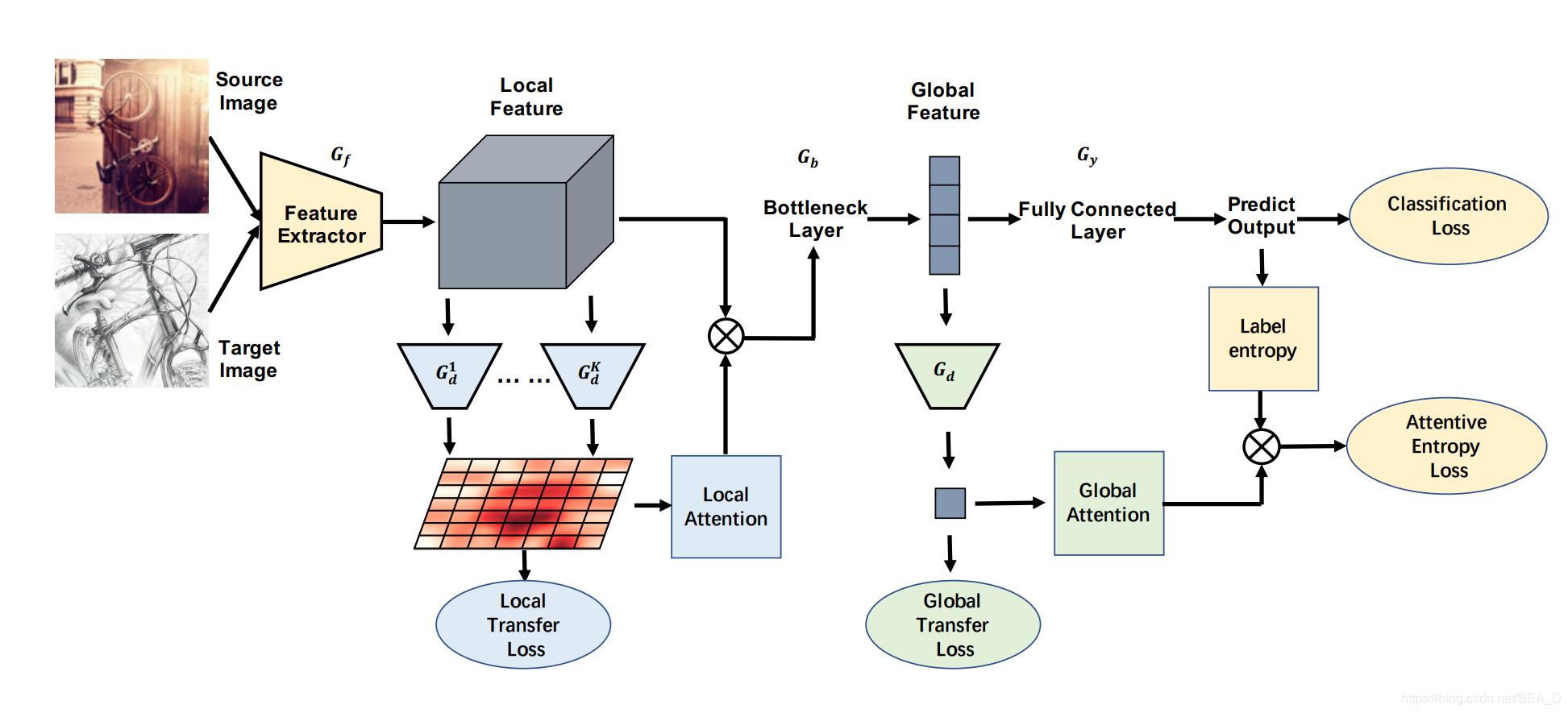
TADA:Transferable Attention for Domain Adaptation(2019 AAAI)
提出了TADA
- 由多个区域级 鉴别器产生的局部注意力来突出可迁移的区域
- 由单个图像级 鉴别器产生的全局注意力来突出可迁移的图像
通过注意力机制挑选出可迁移的图像以及图像中可以重点迁移的区域。因此作者提出了两个与注意力机制结合的迁移过程:
- Transferable Local Attention
- Transferable Global Attention。
1 局部注意力迁移:Transferable Local Attention
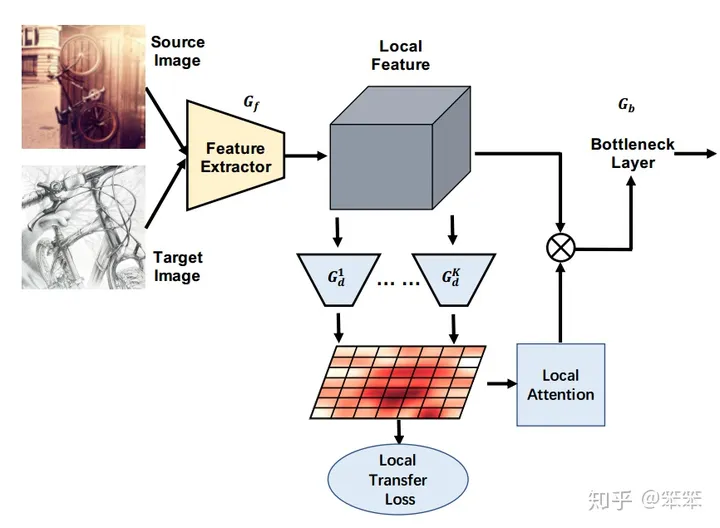
TADA与DANN的思想相同,都是通过一个特征提取器 来提取特征,之后会将提取的特征输入到域判别器 。但是TADA不同之处在于它的域判别器有多个,并且每一个域判别器是针对专门的一块区域的。在DANN中域判别器是判断输入的所有特征组合起来是属于源域还是目标域,而在TADA中每个域判别器只需要判断当前的这一块区域是属于源域还是目标域的。通过这种做法,可以将源域的图片拆开,找出最有用的区域信息,并且将不可迁移的源域信息过滤掉,减小负迁移的风险。
2 全局注意力迁移:Transferable Global Attention
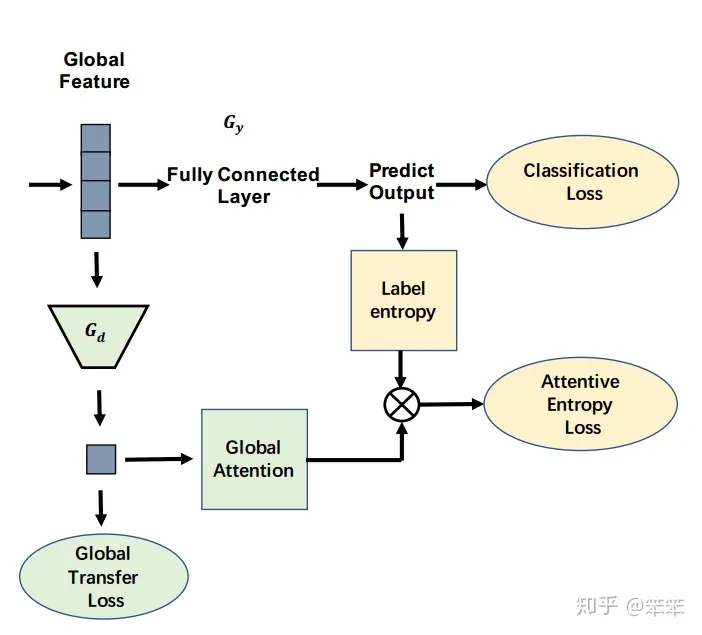
这一步骤和DANN的操作更为相似,作者的目的是找出哪些特征映射更值得迁移,不再将特征映射划分为各个区域,而是关注它的整体。
DAN:Learning transferable features with deep adaptation networks(JMLR 2015)
代码
- 在DAN中,所有特定于任务的层的隐藏表示都嵌入到一个可复制的内核Hilbert空间中,在这个空间中可以显式匹配不同域分布的平均嵌入。
- 采用均值嵌入匹配的多核优化选择方法,进一步减小了domain间的差异。
- DAN可以在有统计保证的情况下学习可转移的特性,并且可以通过核嵌入的无偏估计进行线性扩展。
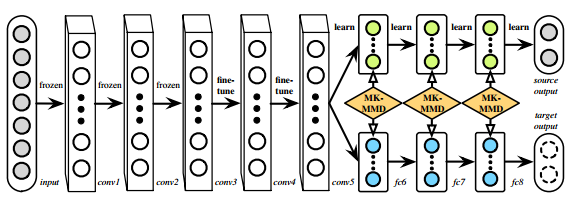
1 多层自适应
基本结构是AlexNet,其中三个全连接都已经和特定任务练习密切,当用于其他任务或数据集时会有较大误差,于是作者提出在最后的三个全连接层都使用MMD进行分布距离约束,从而使得模型具备更强的迁移能力。至于前边的卷积层,前三层提取到的是更为一般的特征,在预训练之后权重固定,4、5两层则要在预训练的基础上进行fine-tune(调整,以致达到最佳效果)
2 多核自适应
分布匹配主要依靠MMD作为分布距离约束来实现,而MMD的效果依赖于核函数的选择,单一核函数的表达能力是有限的,因此作者提出使用多核MMD (MK-MMD) 来作为损失
3 CNN经验误差
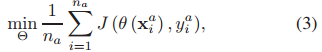 - J:交叉熵损失函数
- J:交叉熵损失函数
- θ ( x i a ) θ(x_i^{a}) θ(xia): x i a x_i^{a} xia被分配到 y i a y_i^{a} yia的条件概率
4 优化目标
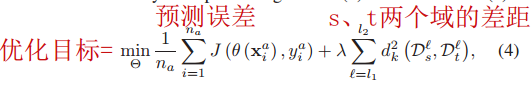
- D s ℓ D^ℓ_s Dsℓ:源域的第 ℓ ℓ ℓ层隐藏表征
- D t ℓ D^ℓ_t Dtℓ:目标域的第 ℓ ℓ ℓ层隐藏表征
- d k 2 ( D s ℓ , D t ℓ ) d_k^2(D^ℓ_s, D^ℓ_t) dk2(Dsℓ,Dtℓ):MK-MMD评估值
5 learning Θ Θ Θ
MK-MMD计算内核功能的期望
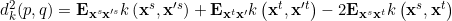
6 learning β β β
多层执行MK-MMD匹配
ADDA:Adversarial discriminative domain adaptation(CVPR 2017)
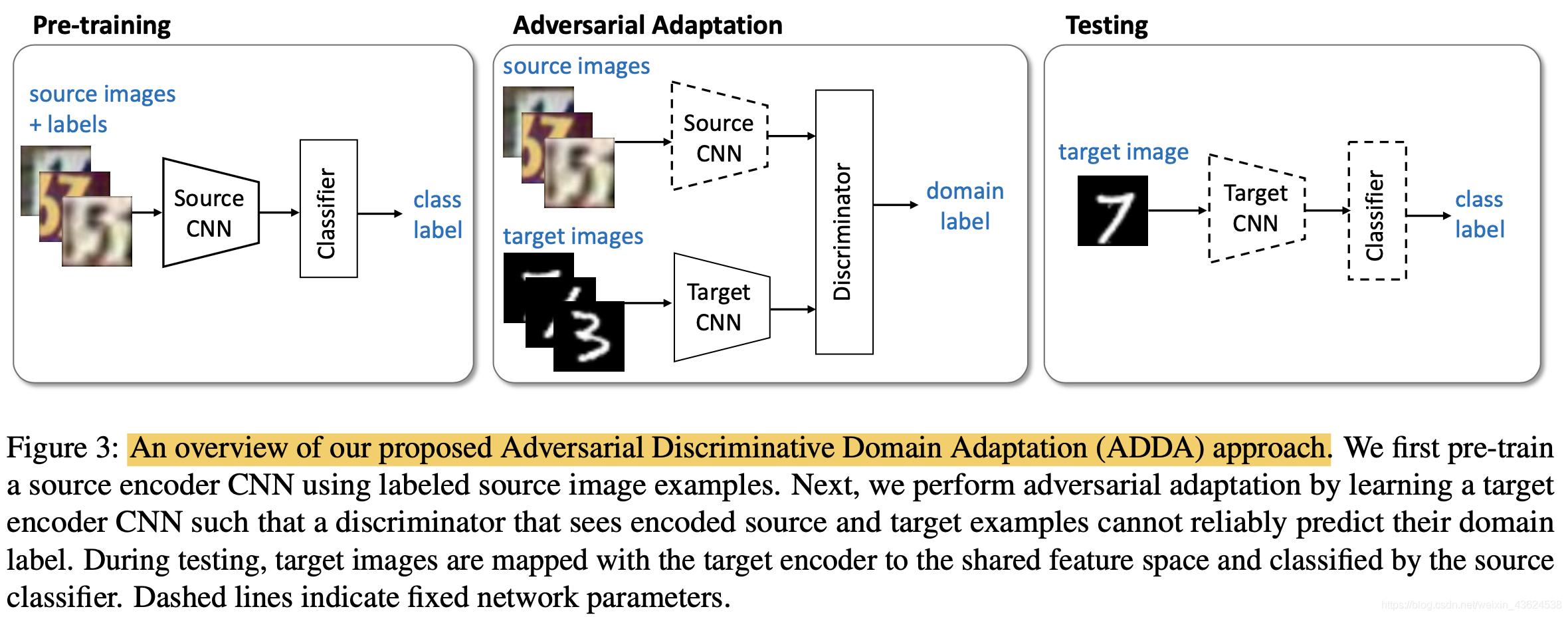
- 使用标记的源图像示例预训练源编码器CNN
- 通过学习目标编码器CNN来执行对抗性适应,使得看到编码源和目标示例的鉴别器无法可靠地预测它们的域标签
- 在测试过程中,目标图像与目标编码器一起映射到共享特征空间,并由源分类器进行分类
1 报错
-
RuntimeError: result type Float can’t be cast to the desired output type Long
acc /= len(data_loader.dataset)
改成
acc = acc / len(data_loader.dataset) -
取ViT输出的池化后结果
pred_tgt = critic(feat_tgt)
增加 pooler_output
pred_tgt = critic(feat_tgt.pooler_output) -
RuntimeError: output with shape [1, 28, 28] doesn’t match the broadcast shape [3, 28, 28]
mnist和usps需要从灰度图片转成RGB图片,通道数从1变成3
transform = transforms.Compose([transforms.Resize((224, 224)), # 调整大小为 224x224transforms.Grayscale(num_output_channels=3), #转化成3通道transforms.ToTensor(), # 将图像转换为张量])
- IndexError: invalid index of a 0-dim tensor. Use
tensor.item()in Python ortensor.item<T>()in C++ to convert a 0-dim tensor to a number
.data[0]
改成
.item()
2 代码
将lenet encoder换成vit
import torch
from transformers import ViTModel, ViTConfig
# 下载 vit-base-patch16-224-in21k def load_pretrained_vit_model():# Load pre-trained ViT-B/16 modelmodel_path = "./pretrained_models/pytorch_model.bin"config_path = "./pretrained_models/config.json"config = ViTConfig.from_json_file(config_path)vit_model = ViTModel.from_pretrained(pretrained_model_name_or_path=None,config=config,state_dict=torch.load(model_path),ignore_mismatched_sizes=True # 忽略大小不匹配的错误)return vit_model
3 判别器
"""Discriminator model for ADDA."""
from torch import nn
class Discriminator(nn.Module):"""Discriminator model for source domain."""def __init__(self, input_dims, hidden_dims, output_dims):"""Init discriminator."""super(Discriminator, self).__init__()print("Shape of input_dims:", input_dims)self.restored = Falseself.layer = nn.Sequential(nn.Linear(input_dims, hidden_dims),nn.ReLU(),nn.Linear(hidden_dims, hidden_dims),nn.ReLU(),nn.Linear(hidden_dims, output_dims),nn.LogSoftmax())def forward(self, input):"""Forward the discriminator."""out = self.layer(input)return out
4 分类器
"""LeNet model for ADDA."""
import torch
import torch.nn.functional as F
from torch import nnclass LeNetClassifier(nn.Module):"""LeNet classifier model for ADDA."""def __init__(self, input_size):"""Init LeNet encoder."""super(LeNetClassifier, self).__init__()self.input_size = input_size# Add linear layers to adjust the size of the input feature to fit LeNet# vitself.fc1 = nn.Linear(input_size, 500)# swin# self.fc1 = nn.Linear(49 * 1024, 500)self.fc2 = nn.Linear(500, 10)def forward(self, feat):"""Forward the LeNet classifier."""# vitfeat = feat.pooler_output# swin# feat = feat.view(feat.size(0), -1)# Apply the linear layers and activation functionout = F.dropout(F.relu(self.fc1(feat)), training=self.training)out = self.fc2(out)return out
5 adapt
"""Adversarial adaptation to train target encoder."""
import os
import torch
import torch.optim as optim
from torch import nn
import params
from utils import make_variabledef train_tgt(src_encoder, tgt_encoder, critic,src_data_loader, tgt_data_loader,model_type):"""Train encoder for target domain."""##################### 1. setup network ###################### set train state for Dropout and BN layerstgt_encoder.train()critic.train()# setup criterion and optimizercriterion = nn.CrossEntropyLoss()optimizer_tgt = optim.Adam(tgt_encoder.parameters(),lr=params.c_learning_rate,betas=(params.beta1, params.beta2))optimizer_critic = optim.Adam(critic.parameters(),lr=params.d_learning_rate,betas=(params.beta1, params.beta2))len_data_loader = min(len(src_data_loader), len(tgt_data_loader))##################### 2. train network #####################for epoch in range(params.num_epochs):# zip source and target data pairdata_zip = enumerate(zip(src_data_loader, tgt_data_loader))for step, ((images_src, _), (images_tgt, _)) in data_zip:############################ 2.1 train discriminator ############################# make images variableimages_src = make_variable(images_src.cuda())images_tgt = make_variable(images_tgt.cuda())# zero gradients for optimizeroptimizer_critic.zero_grad()# extract and concat featuresfeat_src = src_encoder(images_src).pooler_outputfeat_tgt = tgt_encoder(images_tgt).pooler_outputfeat_concat = torch.cat((feat_src, feat_tgt), 0)# predict on discriminatorpred_concat = critic(feat_concat.detach())# prepare real and fake labellabel_src = make_variable(torch.ones(feat_src.size(0)).long().cuda())label_tgt = make_variable(torch.zeros(feat_tgt.size(0)).long().cuda())label_concat = torch.cat((label_src, label_tgt), 0)# compute loss for criticloss_critic = criterion(pred_concat, label_concat)loss_critic.backward()# optimize criticoptimizer_critic.step()pred_cls = torch.squeeze(pred_concat.max(1)[1])############################# 2.2 train target encoder ############################## zero gradients for optimizeroptimizer_critic.zero_grad()optimizer_tgt.zero_grad()# extract and target featuresfeat_tgt = tgt_encoder(images_tgt)# predict on discriminatorpred_tgt = critic(feat_tgt.pooler_output)# prepare fake labelslabel_tgt = make_variable(torch.ones(feat_tgt.last_hidden_state.size(0)).long().cuda())# compute loss for target encoderloss_tgt = criterion(pred_tgt, label_tgt)loss_tgt.backward()# optimize target encoderoptimizer_tgt.step()######################## 2.3 print step info ########################if (step + 1) % params.log_step == 0:print("Epoch [{}/{}] Step [{}/{}]:""d_loss={:.5f} g_loss={:.5f} acc={:.5f}".format(epoch + 1,params.num_epochs,step + 1,len_data_loader,loss_critic.item(),loss_tgt.item(),acc.item()))############################## 2.4 save model parameters ##############################if ((epoch + 1) % params.save_step == 0):# 保存模型时加上特征提取器的标识符if model_type == "vit":model_name = "ADDA-target-encoder-ViT-{}.pt".format(epoch + 1)elif model_type == "mobilevit":model_name = "ADDA-target-encoder-MobileViT-{}.pt".format(epoch + 1)elif model_type == "swin":model_name = "ADDA-target-encoder-Swin-{}.pt".format(epoch + 1)torch.save(tgt_encoder.state_dict(), os.path.join(params.model_root,model_name))# 保存最终模型时也加上特征提取器的标识符if model_type == "vit":final_model_name = "ADDA-target-encoder-ViT-final.pt"elif model_type == "mobilevit":final_model_name = "ADDA-target-encoder-MobileViT-final.pt"elif model_type == "swin":final_model_name = "ADDA-target-encoder-Swin-final.pt"torch.save(tgt_encoder.state_dict(), os.path.join(params.model_root,final_model_name))return tgt_encoderMCD:Maximum classifier discrepancy for unsupervised domain adaptation(CVPR 2018)
最大分类器差异的领域自适应
引入两个独立的分类器F1、F2,用二者的分歧表示样本的置信度不高,需要重新训练。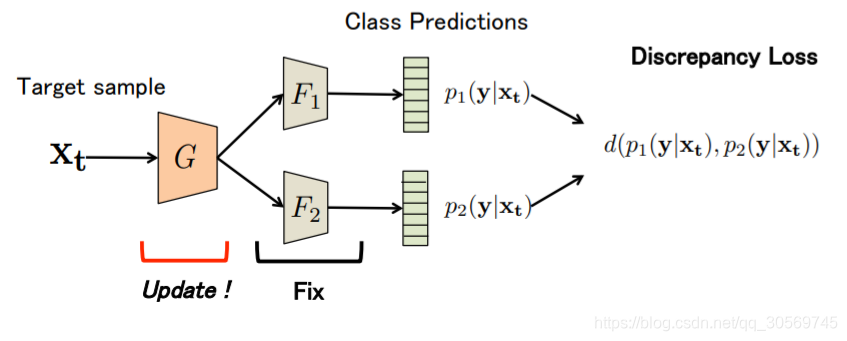
判别损失有两部分组成
MDD:Bridging theory and algorithm for domain adaptation
CDAN:Conditional Adversarial Domain Adaptation(Neural 2018)
条件生成对抗网络,在GAN基础上做的一种改进,通过给原始的GAN的生成器和判别器添加额外的条件信息,实现条件生成模型
复现代码:https://www.cnblogs.com/BlairGrowing/p/17099742.html
提出一个条件对抗性域适应方法(CDAN),对分类器预测中所传递的判别信息建立了对抗性适应模型。条件域对抗性网络(CDAN)采用了两种新的条件调节策略:
- 多线性条件调节,通过捕获特征表示与分类器预测之间的交叉方差来提高分类器的识别率
- 熵条件调节,通过控制分类器预测的不确定性来保证分类器的可移植性
MCC:Moment Matching for Multi-Source Domain Adaptation(ICCV 2019)
DAPL:Domain Adaptation via Prompt Learning(DA+prompt)(arXiv 2022)
代码:https://github.com/LeapLabTHU/DAPrompt
使用预训练的视觉语言模型,优化较少的参数,将信息嵌入到提示中,每个域中共享。
只有当图像和文本的领域和类别分别匹配的时候,他们才形成一对正例。
特征提取器优化
-
ViT
已部署,测试中 -
Swin Transformer:基于 Transformer 结构的新型模型,计算复杂度可能更高一些(对性能要求较高)
-
MobileViT:CNN的轻量高效,transformer的自注意力机制和全局视野,在速度和内存消耗方面优秀(2021)
文章:MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer -
ConvNeXt:结合了CNN和 Transformer 的模型(2022)
文章:A ConvNet for the 2020s
ConvNeXt用100多行代码就能搭建完成,相比Swin Transformer拥有更简单,更快的推理速度以及更高的准确率 -
EfficientNetV2:Google 提出的一系列高效的卷积神经网络,通过使用复合缩放方法和网络深度调整策略,实现了在不同任务上的良好性能和高效计算(对移动设备友好)(2021)
-
MobileNetV3:针对移动设备的轻量级卷积神经网络,有更快的推理速度和更低的内存消耗(对移动设备友好)(2019)
PyTorch Hub 下载模型
https://huggingface.co/models
这篇关于【域适应论文汇总】未完结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




