本文主要是介绍Pybind11 在C++中运行python脚本操作内存数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pybind11资料
官方Github:Pybind11 Github
Pybind11文档:Pybind11 文档
文档在深入使用后需要细细读懂,包括全局只能有一个解释器,如何从C++中返回指针/引用等。基本文档中需要注意的点都会遇到
Python环境安装及维护
对于正常使用人员,只要在自己机子上装好大于Python3.6的环境即可,这里我使用的是Python3.8.5:Python3.8.5 下载页
对于开发人员来说,最好是搭好一次,就随意移植。你拿到另外一个机器直接Copy还要能用。而显然原生Python是对这些不支持的,可以看博主另外一篇文章:Python环境移植
示例
下面是一个简单的示例,
// pybind11 头文件和命名空间
#include <pybind11/pybind11.h>
namespace py = pybind11;int add(int i, int j)
{return i + j;
}PYBIND11_MODULE(example, m)
{// 可选,说明这个模块是做什么的m.doc() = "pybind11 example plugin";//def( "给python调用方法名", &实际操作的函数, "函数功能说明" ). 其中函数功能说明为可选1,2为默认参数m.def("add", &add, "add function", pybind11::arg("i")=1, pybind11::arg("j")=2);
}
假如你的这个dll叫test.dll,你需要在cmake中添加改名,把他改成pyd,后缀是pyd不影响程序运行的,程序运行时还是可以正常索引,不要再生成个dll放到目录下避免内存不是同一块引起bug
#这条命令告诉cmake,我们想把生成的后缀改成pyd
set_target_properties(${PROJECT_NAME} PROPERTIES SUFFIX ".pyd")
外部如何使用呢?下面是一个python脚本,假设叫myTest.py,#执行这个脚本,result就是12
import test from *
result = add(10,2)
在C++中嵌入Python解释器
我们的程序如果要能执行外部的python脚本,我们需要
1.像示例那边。准备好我们需要导出的结构体或变量,生成pyd给外部python脚本使用
2.在程序里嵌入Python解释器
3.提供接口或界面,然后调用这个解释器执行脚本
可以直接执行导入pyd
#include <pybind11/embed.h>
#include <iostream>
namespace py = pybind11;
int main() {// 初始化Python解释器py::scoped_interpreter guard{};// 加载Python脚本py::module script = py::module::import("script");// 调用Python函数int result = script.attr("add")(1, 2).cast<int>();std::cout << "Result: " << result << std::endl;return 0;
}
或者直接执行自己写好的python文件,还可以在程序开始前设置启动参数等
//将环境变量添加到Python的模块搜索路径中pybind11::object sys_module = pybind11::module::import("sys");pybind11::list sys_path = sys_module.attr("path");sys_path.attr("append")(scriptDir);//清空argv,设置参数pybind11::list empty_list;sys_module.attr("argv") = empty_list;pybind11::list argv = sys_module.attr("argv");for (std::string oneArgv : rundata.allArgv){argv.append(oneArgv.toStdString());}//执行文件pybind11::eval_file(rundata.filePath.toStdString().c_str());//移除,否则影响下次执行sys_module.attr("argv") = empty_list;sys_path.attr("remove")(scriptDir);
一些BUG和注意的点
1.再次说明,Pybind11文档一定要细读
2.比如这个问题,并不一定所有模块都能被卸载,目前博主就遇到了cv2模块,安装完卸载了成功了。但是重新载入就会引发程序崩溃。目前做法是全局一个解释器,跟随程序周期走,只有其他小伙伴有内存占用特高的自写模块时才调用卸载接口,这样就能保证稳定运行
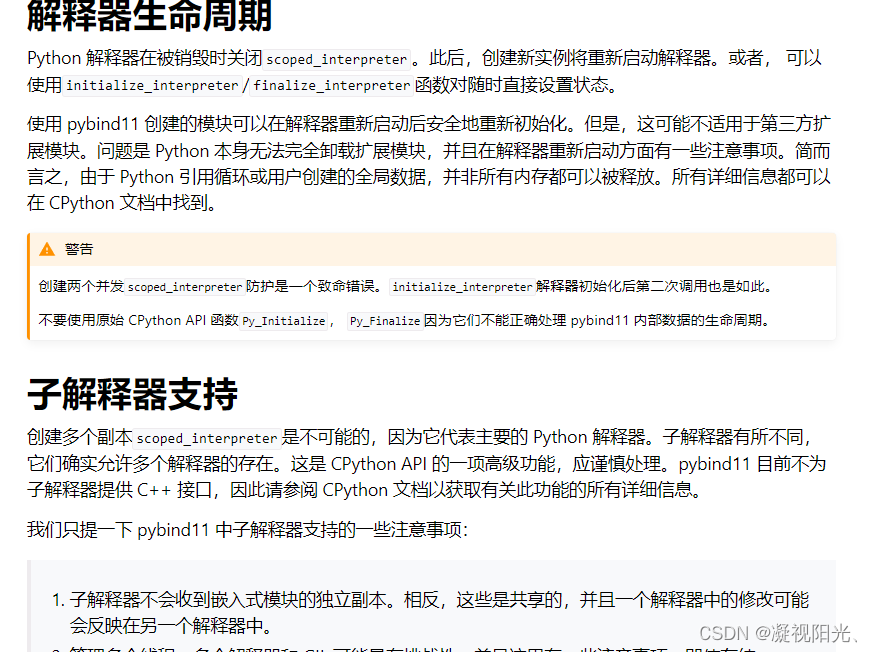
3.这个问题是一个多线程问题
3-1:python由于其实本身并发并不是并发,是靠锁来互斥的。
3-2:如果我们程序执行一个外部脚本出错或者崩溃了,我们解释器里try-catch会获取error的信息,问题就出在这里。
3-3:我们的解释器初始化肯定是在主线程的,但是我们为了不阻塞界面或其他任务,执行脚本时一般都是选择一个工作线程执行
3-4:这时候,工作线程执行就会出现在子线程里获锁,会出现死锁现象导致程序崩溃
3-5:如何解决?由于这个是python导致的,我们只需要将pybind11里几处错误获取锁的地方注释掉即可,我们只要外部程序保证好我们获取错误的顺序,不靠他这个锁保证互斥就没有任何问题了
这篇关于Pybind11 在C++中运行python脚本操作内存数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





