本文主要是介绍文盲的数据库指令优化心得:第一部分,关于索引,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先说点废话,用了10年sqlserver了,楞是不知道指令怎么优化,怎么提高效率太失败了,经过2、3个月的重新学习,才明白之前工作中没有出过问题实在太幸运了
本文中出现的大部分心得内容,在网上也能搜索到,对部分内容有误的,也欢迎大家指正
1、先说说索引,反正文盲本身是野路子出身,没系统学过,说的错了大家来指正
首先,索引是用来优化查询效率的,针对于不同的条件,所需要的索引也千奇百怪,如果索引过多,又没有能够有效的覆盖所有需要的字段,还是会降低效率,那么索引到底应该怎么建立呢?
1.1、所有必定出现在条件内的字段建立一个统一索引,然后包含所有输出的字段,这样可以保证执行计划是索引查找(index seek)而不是索引扫描(index scan),同时因为包含了条件和输出内容,所以也不会出现表扫描(table scan)
1.2、所有可能出现的条件单独建立索引并包含主键,然后单独使用该条件进行主键查询,以确保执行计划是索引查找(index seek)
1.3、索引重复字段尽量减少,因为重复字段约多,更新时越慢,更新所表情况越严重
那么有了以上几点,咱们做个实例进行测试
if object_id('test_index') is not null drop table test_index
go
create table test_index(id bigint identity primary key,n1 int,n2 int,n3 int,n4 int,n5 int,n6 int,n7 int,n8 int,n9 int,d1 date,d2 date,d3 date,d4 date,d5 datetime,d6 datetime,b1 bit,b2 bit,b3 bit,b4 bit,s1 varchar(max),s2 varchar(max),s3 nvarchar(max),s4 nvarchar(max))
go
insert into test_index(n1,n2,n3,n4,n5,n6,n7,n8,n9,d1,d2,d3,d4,d5,d6,b1,b2,b3,b4,s1,s2,s3,s4)
values(RAND()*500,RAND()*500,RAND()*500,RAND()*500,RAND()*500,RAND()*500,RAND()*500,RAND()*500,RAND()*500,dateadd(d,-RAND()*500,getdate()),dateadd(d,-RAND()*500,getdate()),dateadd(d,-RAND()*500,getdate()),dateadd(d,-RAND()*500,getdate()),dateadd(d,-RAND()*500,getdate()),dateadd(d,-RAND()*500,getdate()),(case when RAND()*2 > 1 then 1 else 0 end),(case when RAND()*2 > 1 then 1 else 0 end),(case when RAND()*2 > 1 then 1 else 0 end),(case when RAND()*2 > 1 then 1 else 0 end),'','','',''
)
go 2000000
创建一个测试表,扔200万数据进去,来测试一下索引应该怎么玩
第一个指令
select id from test_index where n1>400
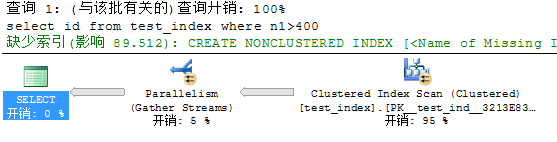
我们发现,基本上所有的查询都会提示缺少索引,那么我们就来分辨一下索引的条件
假设:n1、n2、d1、b1必定出现在查询条件中,而我们只输出主键,那么我们的索引应该这么建立
CREATE NONCLUSTERED INDEX [n1_n2_d1_b1_inc_id] ON [dbo].[test_index]
([n1] ASC,[n2] ASC,[d1] ASC,[b1] ASC
)
INCLUDE ( [id]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO建立好索引后,我们再次运行第一条指令,发现提示的还是缺少索引,那么我们不应该再去建立索引未了适应第一个指令,而是应该将指令变形,以适应我们已有的索引
那么来写第二条指令吧
select id from test_index where n1>40 and n2=n2 and b1=b1 and d1=d1再看看执行计划如何?
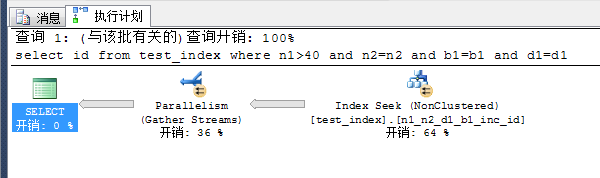
很好,经过我们在指令中加了两句废话,n2=n2,b1=b1,d1=d1这样的条件后,他的执行计划改变了,索引查找(index seek),好吧,sqlserver就是这么个性
那么结论1就是,我们未必需要很多索引,因为我们可以把指令变形,让数据库使用我们所期望的索引,即便实际应用中可能有些条件不完整,我们也要通过废话告诉数据库,来使用已有的索引,也就是1.1中的观点
好了,我们再看看,可能出现的条件,先写个第三条指令
select id from test_index where n1>40 and n2=n2 and b1=b1 and d1=d1 and n5<100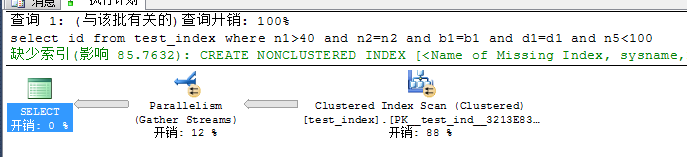
数据库傻掉了,没有使用我们建立的索引,因为n5不在我们的索引范围内,那么我们应该怎么去调整呢,文盲是通过一套组合拳来玩的,首先,建立一个n5为主的,包含主键的索引
CREATE NONCLUSTERED INDEX [n5_inc_id] ON [dbo].[test_index]
([n5] ASC
)
INCLUDE ( [id]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
然后把第三条语句变形一下,称为第四条语句
select main.id from test_index main
inner join (select id from test_index where n5<100) app_n5 on main.id=app_n5.id
where n1>40 and n2=n2 and b1=b1 and d1=d1
呵呵,我们的索引又回来了,那么这个语句的变形依据就是1.2的论点了,这样,我们就可以对所有不确定是否参与运算的字段进行单独索引,并且连排序都可以使用这些索引了
例如
select main.id from test_index main
inner join (select id from test_index where n5<100) app_n5 on main.id=app_n5.id
where n1>40 and n2=n2 and b1=b1 and d1=d1
order by n5
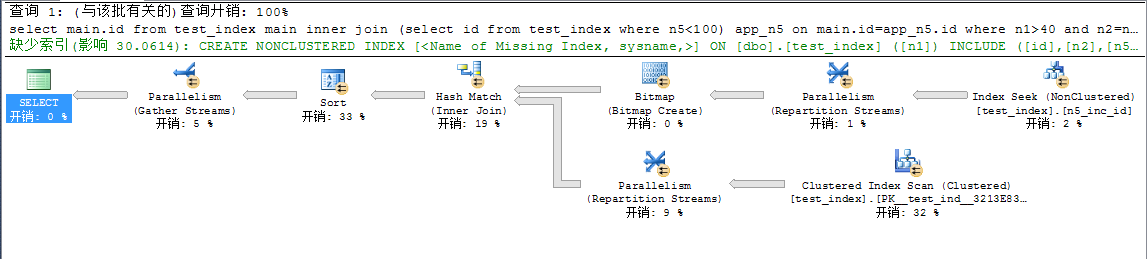
select main.id from test_index main
inner join (select id,n5 from test_index where n5<100) app_n5 on main.id=app_n5.id
where n1>40 and n2=n2 and b1=b1 and d1=d1
order by app_n5.n5
对比这两个指令,唯一的区别就是把索引对应的内容单独拿出来排序,而不是在无该字段索引的查询中排序,呵呵,sqlserver还真是个性啊
那么明白了这个内容之后,我们就可以根据执行计划和现有的索引来调整执行格式,而不是无限制的去加索引了
那么,1.3的观点大部分人都已经说明过了,我就简单说一下,如果一个字段出现在多个索引中,那么在更新这个字段的时候,所有相关的索引都会同时更新,有人说过,一个表上的相关索引最好不要超过5个,那么文盲自己的理解则是,同一个字段(除主键外)相关的索引最好控制在三个以下,索引总数到是无所谓
----------------------------------------------------------------------------------------
文盲的数据库指令优化心得:第一部分,关于索引
文盲的数据库指令优化心得:第二部分,指令变形和执行计划
SQL SERVER全面优化-------Expert for SQL Server 诊断系列
l这篇关于文盲的数据库指令优化心得:第一部分,关于索引的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



