本文主要是介绍【大数据】Flink 内存管理(二):JobManager 内存分配(含实际计算案例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Flink 内存管理》系列(已完结),共包含以下 4 篇文章:
- Flink 内存管理(一):设置 Flink 进程内存
- Flink 内存管理(二):JobManager 内存分配(含实际计算案例)
- Flink 内存管理(三):TaskManager 内存分配(理论篇)
- Flink 内存管理(四):TaskManager 内存分配(实战篇)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
Flink 内存管理(二):JobManager 内存分配
- 1.分配 Total Process Size
- 2.分配 Total Flink Size
- 3.单独分配 Heap Size
- 4.分配 Total Process Size 和 Heap Size
- 5.分配 Total Flink Size 和 Heap Size
JobManager 是 Flink 集群的控制元素。它由三个不同的组件组成: 资源管理器(Resource Manager)、调度器(Dispatcher)和每个运行中的 Flink 作业的一个作业管理器(JobMaster)。
JobManager 的内存模型如下:

以上 Total Process Memory 的模型图可以分为以下的 4 个内存组件,如果在分配内存的时候,显示的指定了组件其中的 1 1 1 个或者多个,那么 JVM Overhead 的值就是在其它组件确定的情况下,用 Total Process Size - 其它获取的值,必须在 min - max 之间,如果没有指定组件的值,那么就按照 0.1 0.1 0.1 的比例进行计算得到,如果计算出的值小于 min 取 min,如果大于 max 取 max,如果 min、max 指定的相等,那么这个 JVM Overhead 就是一个确定的值!
| 内存组件 | | |
|---|---|---|
| JVM Heap | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存大小。这个大小取决于提交的作业个数和作业的结构以及用户代码的要求。主要用来运行 Flink 框架,执行作业提交时的用户代码以及 Checkpoint 的回调代码。 |
| Off-Heap Memory | jobmanager.memory.off-heap.size | JM 的对外内存的大小。涵盖了所有 Direct 和 Native 的内存分配。用来执行 akka 等外部依赖,同时也负责运行 Checkpoint 回调及作业提交时的用户代码,有默认值 128 M 128M 128M。 |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | JM 的元空间大小,有默认值 256 M 256M 256M, 属于 Native Memory。 |
| JVM Overhead | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction | JVM 额外开销。为 Thread Stacks,Code Cache,Garbage Collection Space 预留的 Native Memory,有默认的 faction of total process size,但是必须在其 min & max 之间。 |
在 《Flink 内存管理(一):设置 Flink 进程内存》中我们提到,必须使用下述三种方法之一配置 Flink 的内存(本地执行除外),否则 Flink 启动将失败。这意味着必须明确配置以下选项子集之一,这些子集没有默认值。
| 序号 | for TaskManager | for JobManager |
|---|---|---|
| 1️⃣ | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| 2️⃣ | taskmanager.memory.process.size | jobmanager.memory.process.size |
| 3️⃣ | taskmanager.memory.task.heap.size 和 taskmanager.memory.managed.size | jobmanager.memory.heap.size |
1.分配 Total Process Size
jobmanager.memory.process.size
![]()
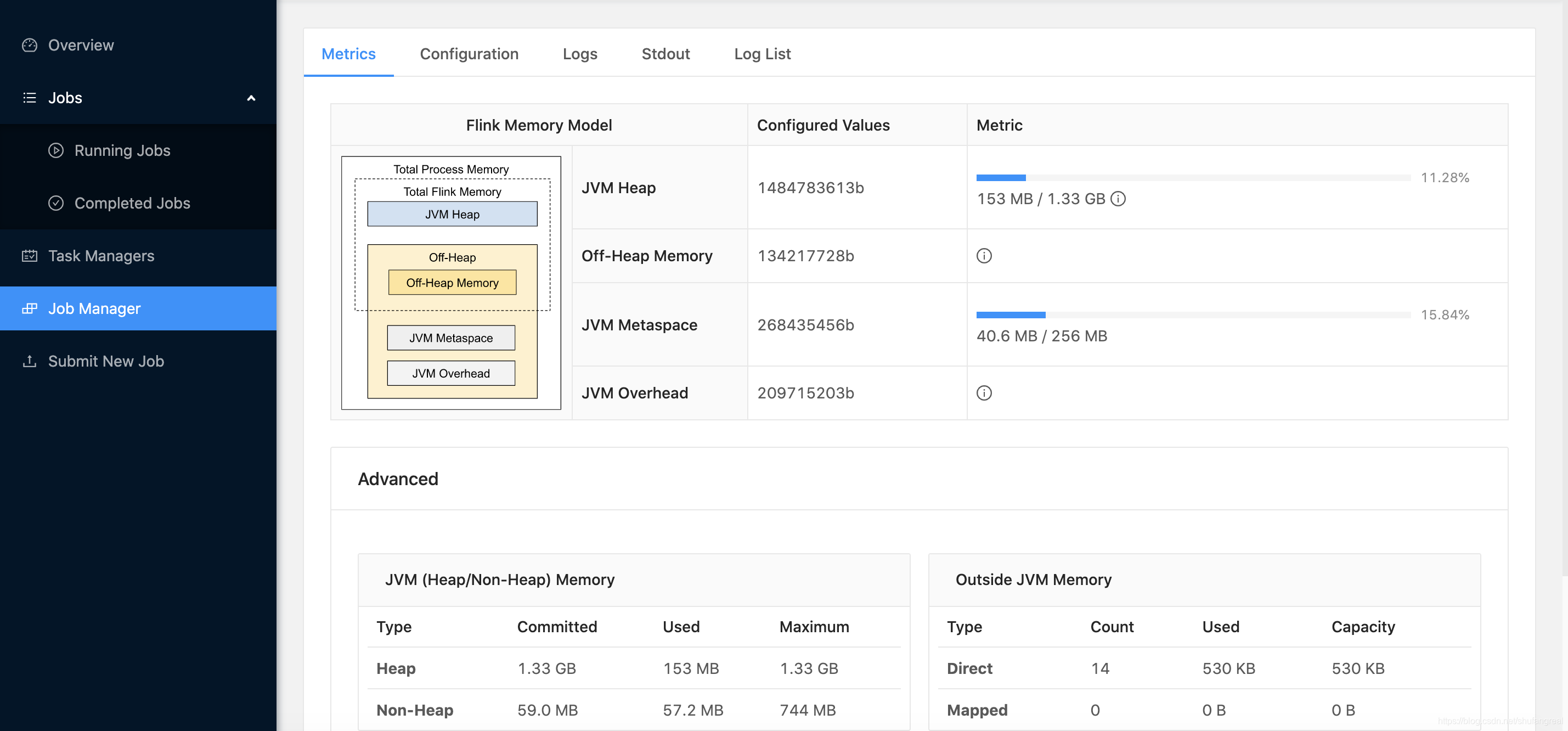
此时我们只显示指定了 jobmanager.memory.process.size 的值,没有指定其它组件,此时整个 JobManager 的 JVM 进程能占用的内存为 2000 M 2000M 2000M。
Total Process Size= 2000 M = 2000M =2000M(这是分配的基准值)JVM Overhead因为没有指定其它组件内存,所以被按照 0.1 0.1 0.1 的比例推断成: 2000 M × 0.1 × 1024 × 1024 = 209715203 B = 200 M 2000M × 0.1 × 1024 × 1024 = 209715203B = 200M 2000M×0.1×1024×1024=209715203B=200MJVM Metaspace默认值为 256 M 256M 256MOff-Heap Memeory默认值为 128 M 128M 128MJVM Heap最终被推断为 2000 M − 200 M − 256 M − 128 M = 1.38 G 2000M - 200M - 256M - 128M = 1.38G 2000M−200M−256M−128M=1.38G
为啥
JVM Heap只有 1.33 G B 1.33GB 1.33GB 而不是 1.38 G B 1.38GB 1.38GB 呢?

其实这个取决于你使用的 GC 算法会占用其中很小一部分固定内存作为 Non-Heap,该占用部分大小为: 1.38 − 1.33 = 0.05 G B 1.38-1.33 = 0.05GB 1.38−1.33=0.05GB。
2.分配 Total Flink Size
jobmanager.memory.flink.size
![]()
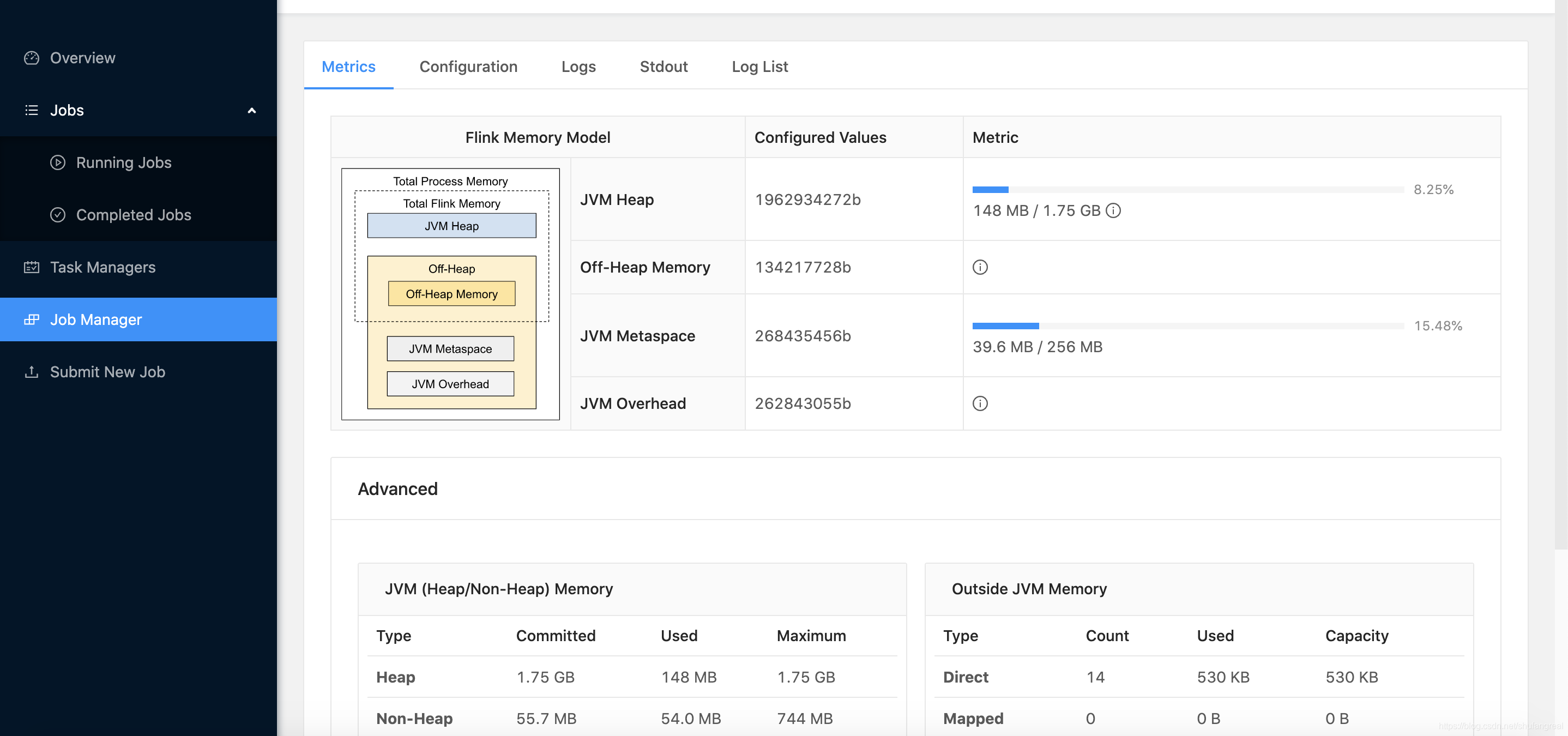
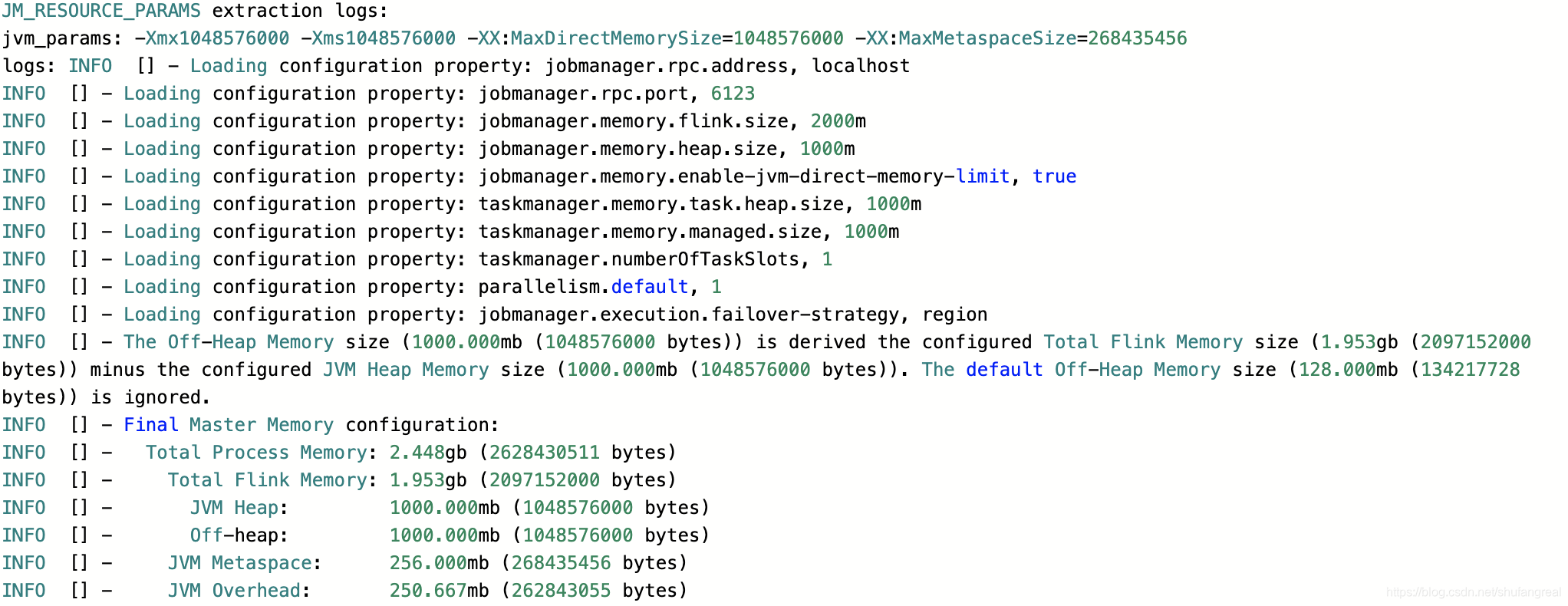
此时我们只显示指定了 jobmanager.memory.flink.size 的值,也没有指定其它组件如 Heap Size,此时整个 JobManager 的 JVM 进程除了 JVM Overhead 及 JVM Metaspace 之外能占用的内存为 2000 M 2000M 2000M。
Total Flink Size= 2000 M = 1.95 G = 2000M = 1.95G =2000M=1.95G(这属于Total Process Size的组件之一,Overhead只能最后按剩余的内存来被推断)JVM Metaspace默认值为 256 M 256M 256M(固定默认值)Off-Heap Memeory默认值为 128 M 128M 128M(固定默认值)JVM Heap= 2000 M − 128 M − 80 M B ( G C 算法占用) = 1.75 G B = 2000M - 128M - 80MB(GC算法占用)= 1.75GB =2000M−128M−80MB(GC算法占用)=1.75GB- 根据
JVM Overhead= = =(JVM Overhead+Metaspace256 M 256M 256M +Flink Size2000 M ) × 0.1 2000 M) ×\ 0.1 2000M)× 0.1,计算可得:Total Process Size= 2.448 G B = 2.448GB =2.448GBJVM Overhead= 2.448 G B × 0.1 = 262843055 B = 250.667 M B = 2.448GB × 0.1 = 262843055B = 250.667MB =2.448GB×0.1=262843055B=250.667MB,在 192 M ~ 1 G B 192M~1GB 192M~1GB,为有效
最终资源的分配如以下日志所示:
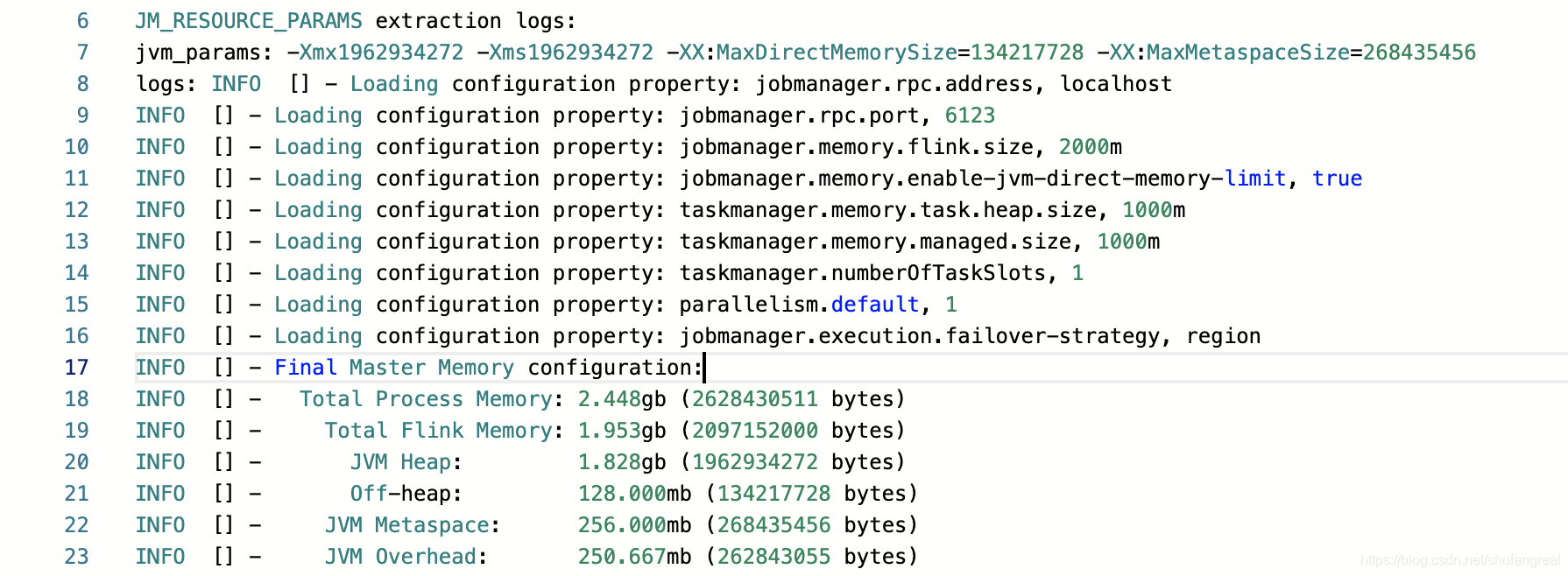
3.单独分配 Heap Size
jobmanager.memory.heap.size
![]()

此时我们只显示指定了 jobmanager.memory.heap.size 的值,相当于显示配置了组件的值,此时整个 JobManager 的 JVM Heap 被指定为最大内存为 1000 M 1000M 1000M。
JVM Heap被指定为 1000 M 1000M 1000M,但是得从 GC 算法中扣除 41 M B 41MB 41MB,实际JVM Heap= 959 M B = 959MB =959MBJVM Metaspace默认值为 256 M 256M 256MOff-Heap Memeory默认值为 128 M 128M 128MTotal Flink Size= 1128 M B = 1.102 G B = 1128MB = 1.102GB =1128MB=1.102GBJVM Overhead= ( 1128 M B + 256 M + = (1128MB + 256M + =(1128MB+256M+JVM Overhead) × 0.1 ) × 0.1 )×0.1JVM Overhead= 153.778 < 192 M B = 153.778 < 192MB =153.778<192MB(默认的min),所以JVM Overhead= 192 M B = 192MB =192MB
Total Process Size= 1128 M B + 256 M + = 1128MB + 256M + =1128MB+256M+JVM Overhead= 1576 M B = 1.5390625 G B = 1.539 G B = 1576MB = 1.5390625GB = 1.539GB =1576MB=1.5390625GB=1.539GB

4.分配 Total Process Size 和 Heap Size
![]()

由于指定了 heap.size 内存组件的的大小,那么 JVM Overhead 就是取剩余的 Total Process Size 的内存空间。
Total Process Size= 2000 M B = 2000MB =2000MB &&JVM Heap= 1000 M B = 1000MB =1000MB,实际只有 959 M B 959MB 959MB,因为减去了 41 M B 41MB 41MB 的 GC 算法占用空间JVM Metaspace默认值为 256 M 256M 256MOff-Heap Memeory默认值为 128 M 128M 128MTotal Flink Size= 1000 M B + 128 M B = 1128 M B = 1000MB + 128MB = 1128MB =1000MB+128MB=1128MBJVM Overhead= 2000 M B − 1128 M B − 256 M B = 616 M B = 2000MB - 1128MB - 256MB = 616MB =2000MB−1128MB−256MB=616MB

5.分配 Total Flink Size 和 Heap Size

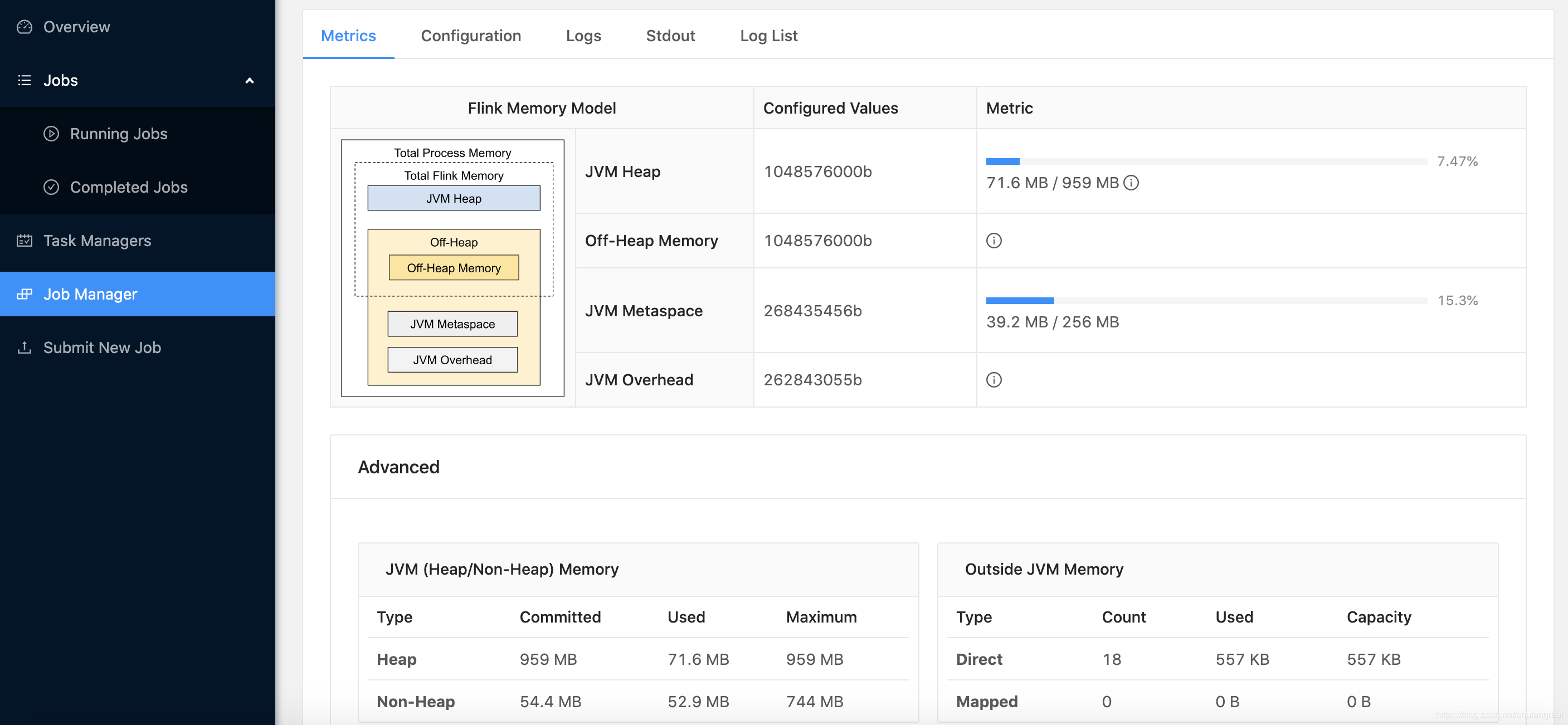
由于指定了 head.size 组件的大小,那么 Overhead 就按照剩余 Total Process Size 的内存空间分配。
Total Flink Size= 2000 M B = 2000MB =2000MB &&JVM Heap= 1000 M B = 1000MB =1000MB,实际 959 M B 959MB 959MB,减去了 GC 算法的占用空间JVM Off-Heap= 2000 M B − 1000 M B = 1000 M B = 2000MB - 1000MB = 1000MB =2000MB−1000MB=1000MBJVM Metaspace= 256 M B = 256MB =256MB- 首先根据
JVM Overhead= ( = ( =(JVM Overhead+ + +Metaspace256 M 256M 256M + + +Flink Size2000 M ) × 0.1 2000M) × 0.1 2000M)×0.1Total Process Size= 2.448 G B = 2.448GB =2.448GBJVM Overhead= 2.448 G B × 0.1 = 262843055 B = 250.667 M B = 2.448GB × 0.1 = 262843055B = 250.667MB =2.448GB×0.1=262843055B=250.667MB,在 192 M ~ 1 G B 192M~1GB 192M~1GB,为有效
- 最终确定
Total Process Size= 2.448 G B = 2.448GB =2.448GB &&JVM Overhead= 250.667 M B = 250.667MB =250.667MB
这篇关于【大数据】Flink 内存管理(二):JobManager 内存分配(含实际计算案例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






