本文主要是介绍yolov8添加注意力机制模块-CBAM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
修改
- 在tasks.py(路径:ultralytics-main/ultralytics-main - attention/ultralytics/nn/tasks.py)文件中,引入CBAM模块。因为yolov8源码中已经包含CBAM模块,在conv.py文件中(路径:ultralytics-main/ultralytics-main - attention/ultralytics/nn/modules/conv.py),这里就就用自己写了。
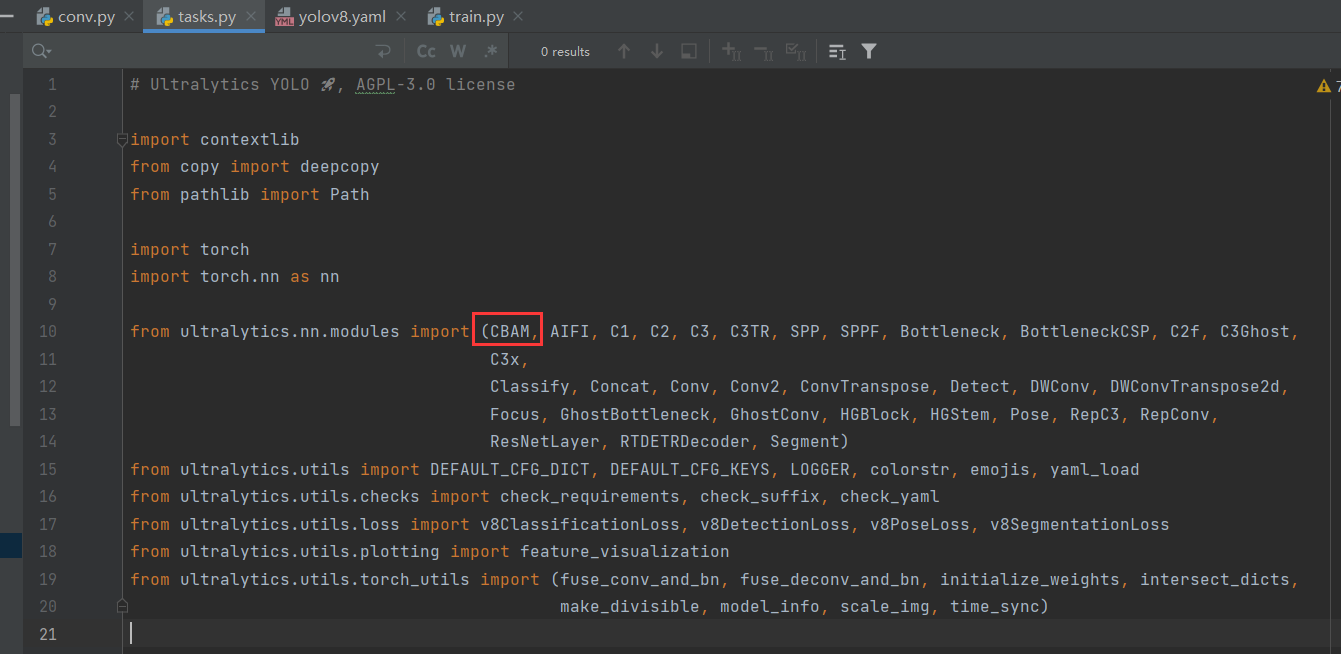
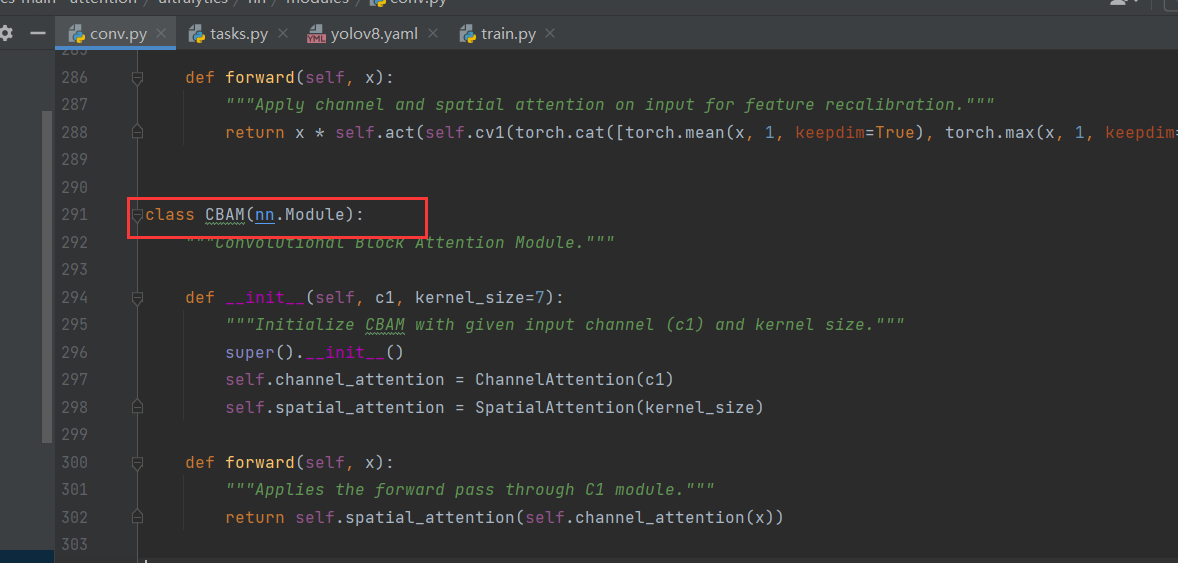
- 修改tasks.py文件,搜索parse_model。在指定位置添加代码。
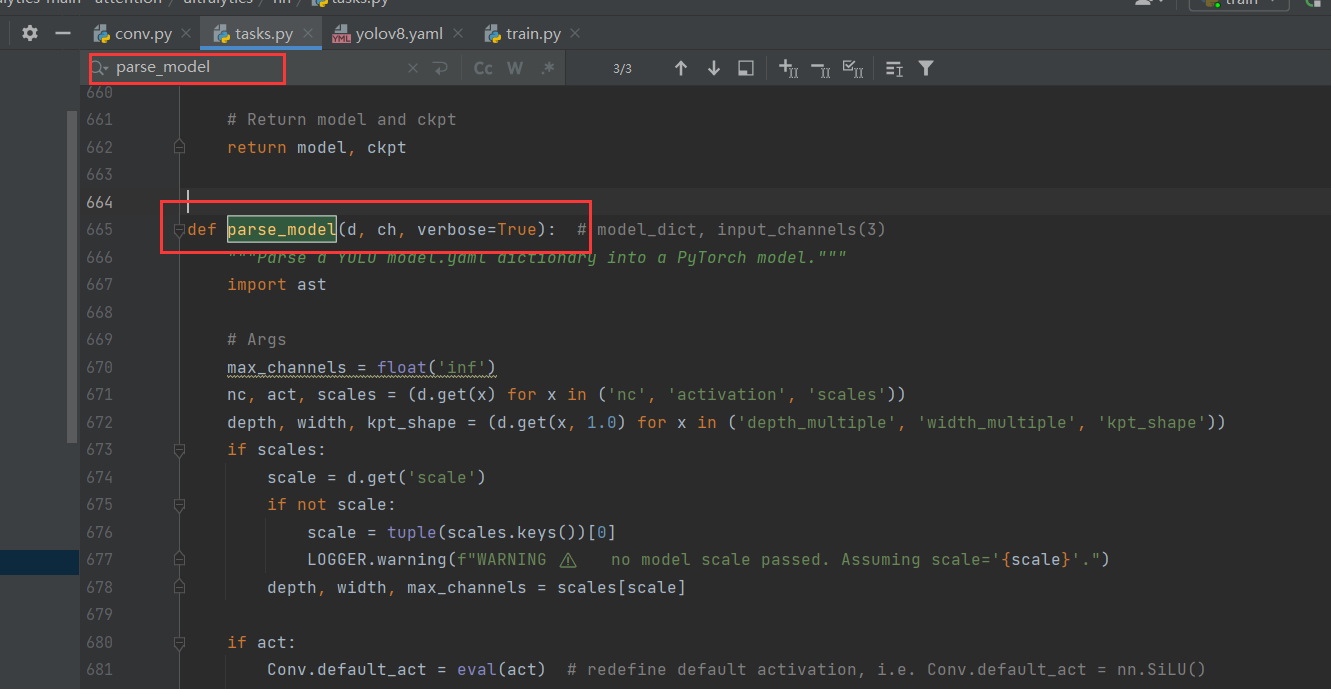

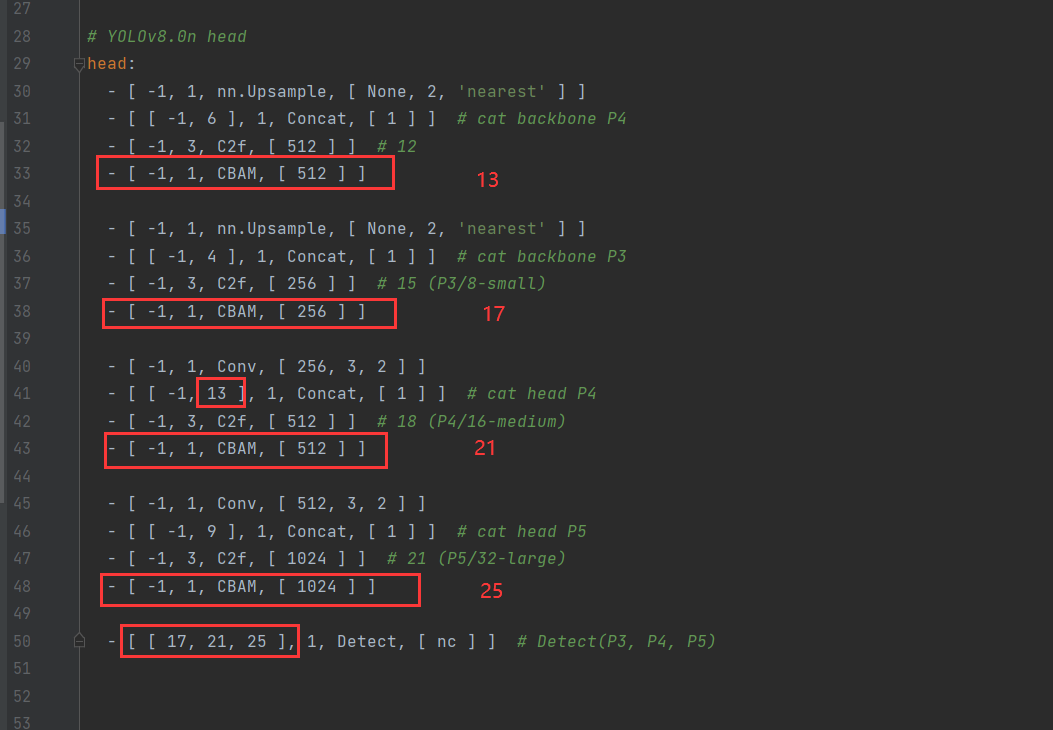
elif m is CBAM: # todo 源码修改 (增加了elif)"""ch[f]:上一层的args[0]:第0个参数c1:输入通道数c2:输出通道数"""c1, c2 = ch[f], args[0]# print("ch[f]:",ch[f])# print("args[0]:",args[0])# print("args:",args)# print("c1:",c1)# print("c2:",c2)if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(c2 * width, 8)args = [c1, *args[1:]]3.修改yolov8.yaml文件位置(ultralytics-main/ultralytics-main - attention/ultralytics/cfg/models/v8/yolov8.yaml)。修改head模块,修改的内容如下图。
4.测试打印网络。已经添加成功。

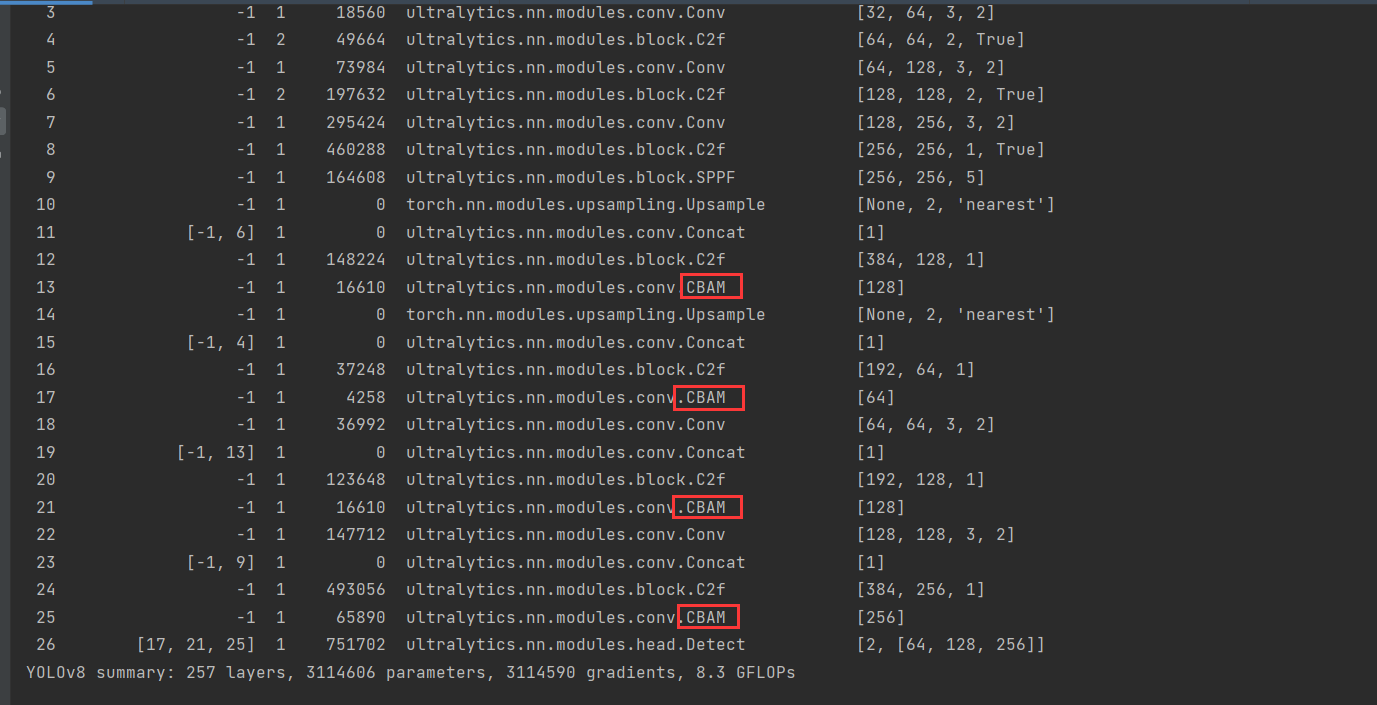
分析
一般来说,注意力机制通常被分为以下基本四大类:
通道注意力 Channel Attention
空间注意力机制 Spatial Attention
时间注意力机制 Temporal Attention
分支注意力机制 Branch Attention
CBAM:通道注意力和空间注意力的集成者
源码解读
这段代码是对通道的注意力。首先经过自适应平均池化层,它会对每个输入通道的空间维度进行全局平均池化,并输出一个具有空间大小为 1x1 的特征图。然后是一个卷积操作,这相当于是对每个通道进行独立的全连接层变换,因为卷积核大小为1。
最后经过Sigmoid函数,将卷积层的输出转换为权重因子,范围在(0, 1)。最后,这些权重因子与原始输入x逐元素相乘,以得到加权后的特征图,这一操作实现了注意力机制,允许模型专注于更有信息量的通道。
class ChannelAttention(nn.Module):"""Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""def __init__(self, channels: int) -> None:"""Initializes the class and sets the basic configurations and instance variables required."""super().__init__()self.pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)self.act = nn.Sigmoid()def forward(self, x: torch.Tensor) -> torch.Tensor:"""Applies forward pass using activation on convolutions of the input, optionally using batch normalization."""return x * self.act(self.fc(self.pool(x)))下面是一个空间注意力模块,旨在通过对输入特征图加权来强调或抑制某些空间区域。空间注意力通常用于强调图像的重要部分并抑制不重要的部分。
self.cv1 是一个卷积层,有两个输入通道,一个输出通道,和可选的 kernel_size 与 padding。由于 bias=False,这个卷积层不会有偏置参数。两个输入通道对应于输入特征图的均值和最大值。
forward中
-
torch.mean(x, 1, keepdim=True)计算输入张量x每个样本的通道维度的均值,keepdim=True表示保持输出张量的维度不变。 -
torch.max(x, 1, keepdim=True)[0]计算输入张量x每个样本的通道维度的最大值,[0]是因为torch.max返回一个元组,包含最大值和相应的索引。 -
torch.cat([avg_out, max_out], 1)将均值和最大值沿通道维度拼接起来,这样每个空间位置都有两个通道:其均值和最大值。 -
self.cv1(x_cat)对拼接的结果应用 1x2 卷积,生成一个单通道的特征图,该特征图对应于每个空间位置的注意力权重。 -
self.act(...)应用 Sigmoid 激活函数将注意力权重映射到 (0, 1) 范围内。 -
x * scale将原始输入x与计算得到的空间注意力权重相乘,这样每个空间位置的特征值都会根据其重要性加权,实现了特征重标定。
最终,forward 方法返回的是加权后的输入特征图(对特征图的每个元素值×权值),它突出了输入中更重要的空间区域。
class SpatialAttention(nn.Module):"""Spatial-attention module."""def __init__(self, kernel_size=7):"""Initialize Spatial-attention module with kernel size argument."""super().__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.act = nn.Sigmoid()def forward(self, x):"""Apply channel and spatial attention on input for feature recalibration."""return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))下面就是CBAM,是上面两个模块的组合,通道注意力和空间注意力。通道注意力专注于哪些通道更重要,而空间注意力则集中在输入特征图中的哪些空间位置更重要。
- 输入
x首先通过self.channel_attention,这个步骤会重新调整每个通道的重要性。 - 然后,调整通道重要性后的特征图
x通过self.spatial_attention,这个步骤会重新调整特征图中每个位置的重要性。 - 最终,这两个注意力机制的结果被串联起来,形成了最终的输出。
这种结构可以提高网络对于输入特征的逐通道和逐空间位置的重要性评估能力,进而可能提高模型的性能。
class CBAM(nn.Module):"""Convolutional Block Attention Module."""def __init__(self, c1, kernel_size=7):"""Initialize CBAM with given input channel (c1) and kernel size."""super().__init__()self.channel_attention = ChannelAttention(c1)self.spatial_attention = SpatialAttention(kernel_size)def forward(self, x):"""Applies the forward pass through C1 module."""return self.spatial_attention(self.channel_attention(x))这篇关于yolov8添加注意力机制模块-CBAM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





