本文主要是介绍全国任意城市二手房价爬取(附源码)+分析教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
不喜欢太多废话,直接上分析。
过程:
(第一步找总体)
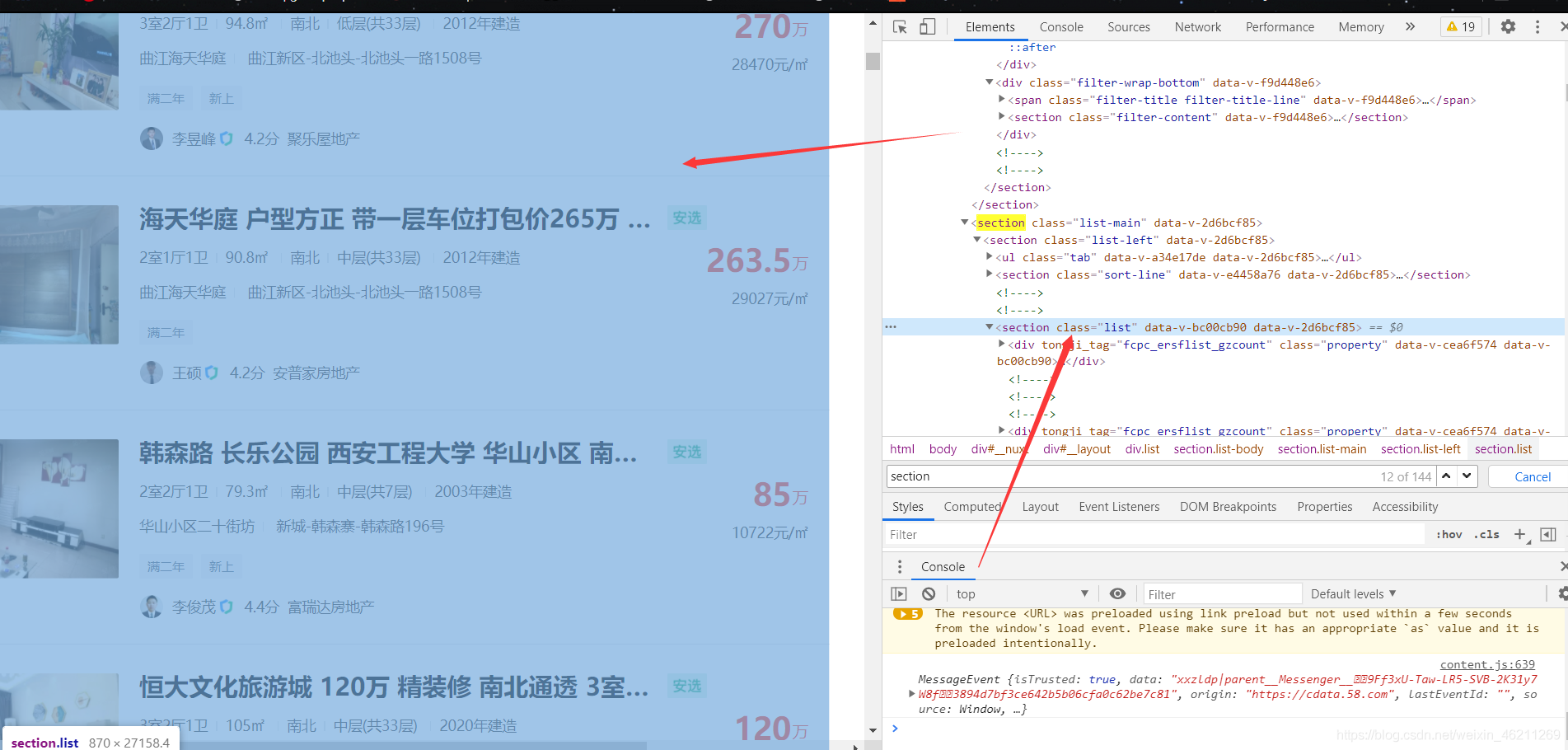
第二步看单个:
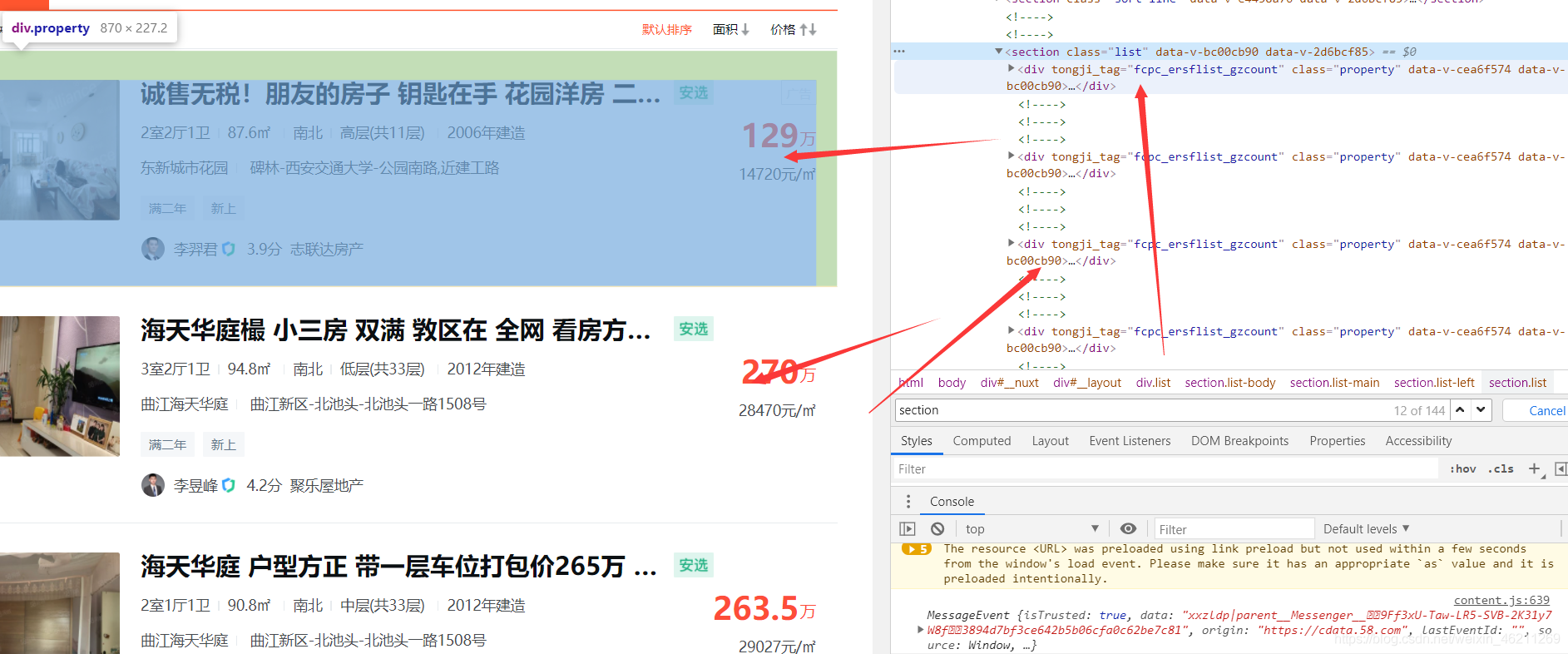
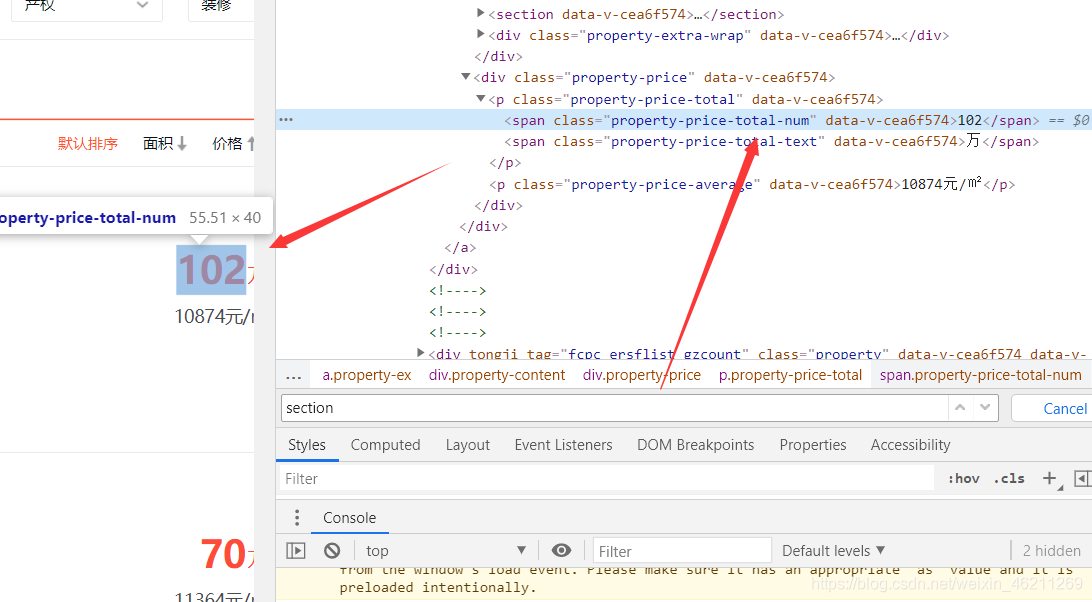
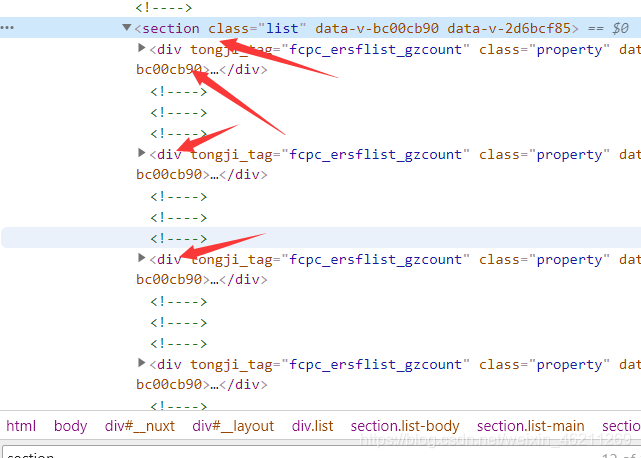
(找规律)可遍历:
#coding=utf-8
"""
作者:川川
时间:2021/6/26
"""
from lxml import etree
import requestsif __name__ == '__main__':headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}url = 'https://xa.58.com/ershoufang/?q=%E4%B8%8A%E6%B5%B7'page_text = requests.get(url=url,headers=headers).texttree = etree.HTML(page_text)div_list = tree.xpath('//section[@class="list"]/div')print(div_list)fp = open('./上海二手房.txt','w',encoding='utf-8')for div in div_list:title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]print(title)price=str('总价格为'+div.xpath('.//div[@class="property-price"]/p/span[@class="property-price-total-num"]/text()')[0])+'万元'print(price)fp.write(title+'\t'+price+'\n'+'\n')结果:
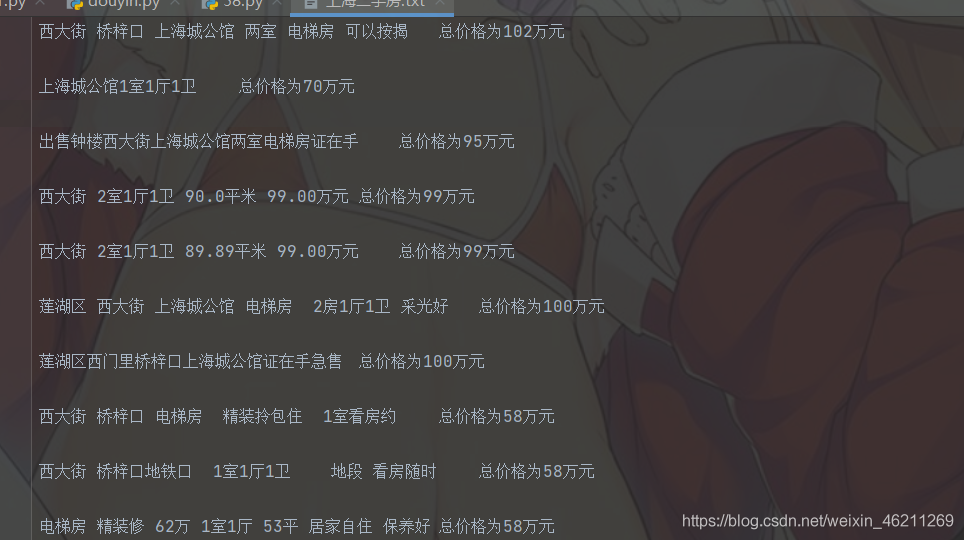
但是呢?这样会不会还是显得麻烦了呢?难不成每个城市都写一份这样的代码吗?不是的,请看如下分析:
上面这部分代码是爬取的上海的二手房价
然而网址却是这样的:

这样很容易想到,如果切换城市,仅仅只需要把上海换成别的城市就可以了。经过我分析,换个城市,网页结构并不用变化,所以唯一变动就是这个城市。
因此修改后代码:
#coding=utf-8
"""
作者:川川
时间:2021/5/10
"""
from lxml import etree
import requestsif __name__ == '__main__':headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}c=input('这里是二手房价爬取,请输入你想要爬取的城市:\n')url = 'https://xa.58.com/ershoufang/?q=%s'%cpage_text = requests.get(url=url,headers=headers).texttree = etree.HTML(page_text)div_list = tree.xpath('//section[@class="list"]/div')print(div_list)fp = open('./上海二手房.txt','w',encoding='utf-8')for div in div_list:title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]print(title)price=str('总价格为'+div.xpath('.//div[@class="property-price"]/p/span[@class="property-price-total-num"]/text()')[0])+'万元'print(price)fp.write(title+'\t'+price+'\n'+'\n')效果如下:
想爬取哪个城市就输入哪个城市即可

b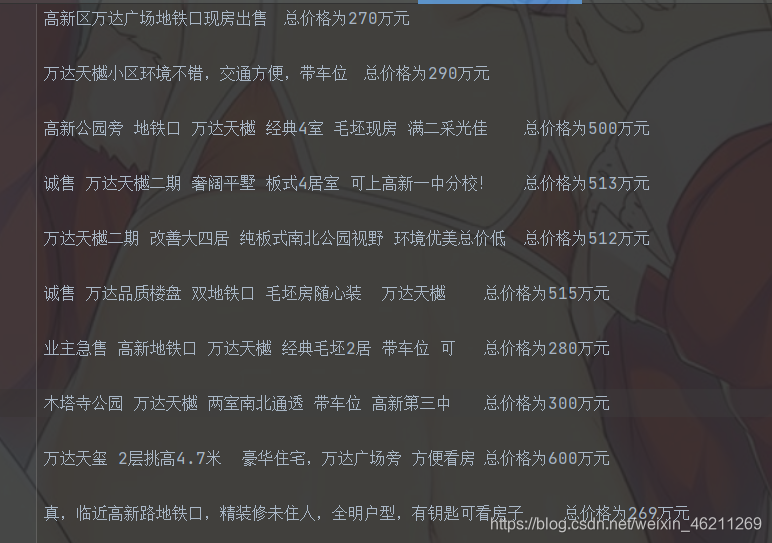
可是就算这样能爬取到每个城市的二手价,每次创建的文件名字没有变动啊,所以还得继续修改一点点,需要每次爬取就自动创建对应城市的文档,所以再次修改后如下:
#coding=utf-8
"""
作者:川川
时间:2021/5/10
"""
from lxml import etree
import requestsif __name__ == '__main__':headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}c=input('这里是二手房价爬取,请输入你想要爬取的城市:\n')url = 'https://xa.58.com/ershoufang/?q=%s'%cpage_text = requests.get(url=url,headers=headers).texttree = etree.HTML(page_text)div_list = tree.xpath('//section[@class="list"]/div')print(div_list)wen=c+'二手房价.txt'fp = open(wen,'w',encoding='utf-8')for div in div_list:title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]print(title)price=str('总价格为'+div.xpath('.//div[@class="property-price"]/p/span[@class="property-price-total-num"]/text()')[0])+'万元'print(price)fp.write(title+'\t'+price+'\n'+'\n')
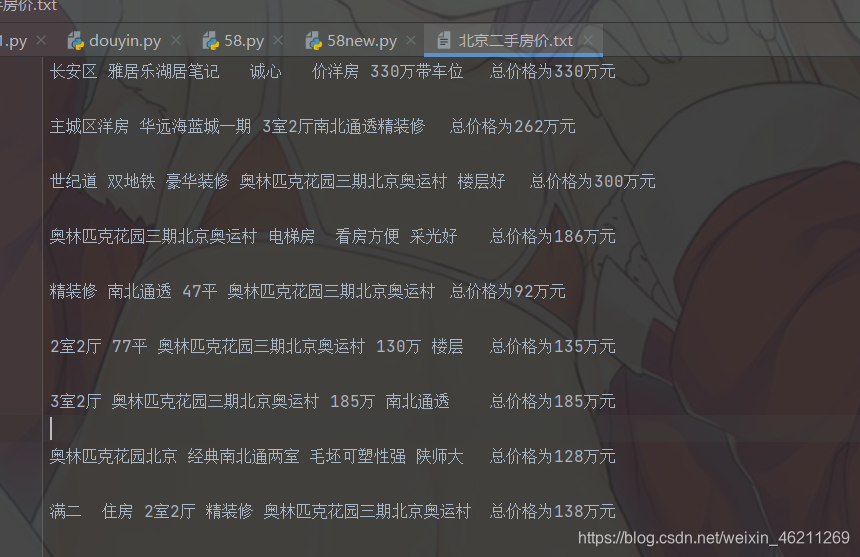
现在就完成了。
爬完二手房价,我都感觉要哭穷了,这房也太贵了吧!!酸了啊!
(顺便打上自己的小小群:970353786,任何代码资料均个人创造与分享)
这篇关于全国任意城市二手房价爬取(附源码)+分析教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





