本文主要是介绍【学习设计模式2】设计模式指导思想—面向对象设计原则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

如果说设计模式是24道佳肴,那么面向对象设计原则,就是制作美食的配方。一个理论,一个实践。
上篇:【学习设计模式1】豪华的菜单—设计模式概述_Aiky哇-CSDN博客我说实话,我也记不住那么多的条条框框,写这篇博客的目的主要是让自己有个印象,以后设计代码结构时,不会犯低级错误,要求不高。https://aikysay.blog.csdn.net/article/details/122061418
下篇:
【学习设计模式3】创建型模式三结义—简单工厂模式_Aiky哇-CSDN博客当你需要什么,只需要传入一个正确的参数,就可以获取你所需要的对象,而无须知道其创建细节https://aikysay.blog.csdn.net/article/details/122566896
目录
面向对象设计原则概述
单一职责原则
举例:
开闭原则
举例:
里氏代换原则
举例:
依赖倒转原则
开闭原则、里氏代换原则和依赖倒转原则的关系
举例:
接口隔离原则
举例:
合成复用原则
举例:
迪米特法则
举例:
总结
参考文献
面向对象设计原则概述
面向对象编程的出现到现在已经有半个世纪了(于1950s第一次出现在MIT),在几十年的发展中总结出了很多设计原则,这些原则为提高代码的可维护性和可复用性而产生。
经常被用到的有六大设计原则:单一职责原则,开闭原则,里氏代换原则,依赖倒转原则,接口隔离原则,迪米特原则,或者七大设计原则,多一个合成复用原则。
| 单一职责原则 (Single Responsibility Principle, SRP) | 一个类只负责一个功能领域中的相应职责 |
| 开闭原则 (Open-Closed Principle, OCP) | 软件实体应对扩展开放,而对修改关闭 |
| 里氏代换原则 (Liskov Substitution Principle, LSP) | 所有引用基类对象的地方能够透明地使用其子类的对象 |
| 依赖倒转原则 (Dependence Inversion Principle, DIP) | 抽象不应该依赖于细节,细节应该依赖于抽象 |
| 接口隔离原则 (Interface Segregation Principle, ISP) | 使用多个专门的接口,而不使用单一的总接口 |
| 合成复用原则 (Composite Reuse Principle, CRP) | 尽量使用对象组合,而不是继承来达到复用的目的 |
| 迪米特法则 (Law of Demeter, LoD) | 一个软件实体应当尽可能少地与其他实体发生相互作用 |
这些原则会非常频繁的出现在各类设计模式中,属于是指导性原则。
但是酸甜苦辣咸,据一味即可,多则必失。
设计模式并不一定会同时满足多个设计原则,比如“XXX模式符合XXX原则,但是违反了XXX原则”。
单一职责原则
单一职责原则(Single Responsibility Principle, SRP):一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
单一职责是实现高内聚、低耦合的指导方针,用于控制类的粒度大小。
是最简单的原则,也是最难运用的原则,所谓易懂难精就是它了。熟练掌握这个原则,需要程序员有丰富的经验,能够对类的职责进行分类总结,对分析设计能力的要求较高。
大家都认可的是,在软件系统中,一个类(大到模块,小到方法)承担的职责越多,它被复用的可能性就越小。所以要想提高代码复用,就需要把职责降下来。
因为如果一个类负责的职责不止一个,当其中一个职责变化时,可能会影响其他职责的运作,维护成本就会增加。这种设计会增加职责耦合,当发生变化时,设计会遭受意想不到的破坏[ASD]。
反过来说,如果有两个类,总是同时被调用,同时做改变,说明这两个类的职责高度重合,那么就可以合成一个类。
最后引申一下,单一职责原则不只是面向对象编程思想所特有的,只要是模块化的程序设计,都适用单一职责原则。
举例:
有个厨师开了餐馆,他要做的就是,收顾客的钱,炒好菜,给顾客端过去,然后等顾客吃完就去收拾桌子。那么我们的类方法如下:
class Cook //厨师类+CollectMoney() //收钱+Cook() //炒菜+SideDish() //端菜+ClearTheTable() //收桌子但是随着餐馆越来越火爆,厨师可能炒着炒着菜,就要去收钱,然后又要收拾桌子,忙的不行,有时候稍微收拾桌子满了,菜就糊了。于是雇了个人,这个人来跑堂,自己只用看着炒菜的火就行。
class Cook //厨师类+Cook() //炒菜--
class Waiter //跑堂的+CollectMoney() //收钱+SideDish() //端菜+ClearTheTable() //收桌子这样,职责分开了,自己不忙了,厨师再也没有炒糊过菜。
这就是所谓的职责分离,厨师就炒菜就行,符合单一职责原则。
开闭原则
开闭原则(Open-Closed Principle, OCP):一个软件实体应当对扩展开放,对修改关闭。即软件实体应尽量在不修改原有代码的情况下进行扩展。
开闭原则是面向对象的可复用设计的第一块基石,它是最重要的面向对象设计原则。
在开闭原则的定义中,软件实体可以指一个软件模块、一个由多个类组成的局部结构或一个独立的类。
在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
所以开闭原则认为,当软件需要变化时,应当尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
为了满足开闭原则,需要对系统进行抽象化设计。抽象化是开闭原则的关键。
开闭原则无非就是想表达这样一层意思:用抽象构建框架,用实现扩展细节。因为抽象灵活性好,适应性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节,我们用从抽象派生的实现类来进行扩展,当软件需要发生变化时,我们只需要根据需求重新派生一个实现类来扩展就可以了。当然前提是我们的抽象要合理,要对需求的变更有前瞻性和预见性才行。
举例:
有个厨师开了炸鸡店,他卖炸鸡
class Cook //厨师类+ZhaJi() //炸鸡有顾客来了,说这炸鸡没味,吃着不香
于是厨师把剩下的鸡肉都用酱料腌上了,之后做的炸鸡都够味
class Cook //厨师类+YanZhiZhaJi() //腌制炸鸡但是突然有顾客口味淡,说你这炸鸡吃着忒咸
厨子没法了,所有鸡肉都腌过了,然后他恍然大悟,哦!自己违背了开闭原则。
以下是他的改进策略:
class Cook //厨师类-ZhaJi {abstruct} //炸鸡类+SetZhaJi() //选择哪种炸鸡--
PuTongZhaJi : ZhaJi //普通炸鸡+zhaji()--
YanZhiZhaJi : ZhaJi //腌制炸鸡+zhaji()
这样就满足了开闭原则,厨师只是多增加了一种炸鸡类型,并没有对已经存在的炸鸡类型做改动。
这样就满足了所有顾客,也满足了开闭原则。
里氏代换原则
里氏代换原则(Liskov Substitution Principle, LSP):所有引用基类(父类)的地方必须能透明地使用其子类的对象。
里氏代换原则告诉我们,在软件中将一个基类对象替换成它的子类对象,程序将不会产生任何错误和异常,反过来则不成立,如果一个软件实体使用的是一个子类对象的话,那么它不一定能够使用基类对象
很像是数学上的包含关系。例如:我喜欢动物,那我一定喜欢狗,因为狗是动物的子类;但是我喜欢狗,不能据此断定我喜欢动物,因为我并不喜欢老鼠,虽然它也是动物。
里氏代换原则是实现开闭原则的重要方式之一,也是开闭原则的具体实现手段之一,由于使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用子类对象来替换父类对象。
我们在运用里氏代换原则时,尽量把父类设计为抽象类或者接口,让子类继承父类或实现父接口,并实现在父类中声明的方法,运行时,子类实例替换父类实例,我们可以很方便地扩展系统的功能,同时无须修改原有子类的代码,增加新的功能可以通过增加一个新的子类来实现。
当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。【由时候我们可以采用final的手段强制来遵循】
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改(当然这会违反开闭原则),就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
继承作为面向对象三大特性之一,在给程序设计带来巨大便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低,增加了对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能会产生故障。
举例:
里式代换原则是开闭原则的基础,我在开闭原则的举例就是里式代换原则的一种。
其他例子也特别多,只要是包含关系,基本都能用里式代换原则来解释。
这里就不再举其他例子。
但是想说一下自己工作中的例子。里氏代换原则肯定是为了更好地保证程序的可复用性的,但是真实工作中,情况要复杂很多,还要考虑其他的东西,比如可读性啊,性能啊。比如我现在在用go,定义时当然可以用父类来定义,但是实现时,如果代码的使用频率特别高,那么断言次数就会特别高,每次断言的性能损耗虽然可以忽略不计,但是挡不住量大。并且有时候父类的定义特别模糊,就不能明白这个父类在这里具体要使用哪个实现,因为有的实现可能永远不会用到,但是为了可维护性,还是会保留。
所以我感觉不能盲目,需要变通。
依赖倒转原则
依赖倒转原则(Dependency Inversion Principle, DIP):抽象不应该依赖于细节,细节应当依赖于抽象。换言之,要针对接口编程,而不是针对实现编程。
如果说开闭原则是面向对象设计的目标的话,那么依赖倒转原则就是面向对象设计的主要实现机制之一,它是系统抽象化的具体实现。刚开始看我会觉得,这个表述其实和里式代换原则很像,都描述抽象父类和具体子类的关系,然后又都是在实现开闭原则。
开闭原则、里氏代换原则和依赖倒转原则,在大多数情况下,这三个设计原则会同时出现,开闭原则是目标,里氏代换原则是基础,依赖倒转原则是手段,它们相辅相成,相互补充,目标一致,只是分析问题时所站角度不同而已。
依赖倒转原则要求我们在程序代码中传递参数时或在关联关系中,尽量引用层次高的抽象层类,即使用接口和抽象类进行变量类型声明、参数类型声明、方法返回类型声明,以及数据类型的转换等,而不要用具体类来做这些事情。
为了确保该原则的应用,一个具体类应当只实现接口或抽象类中声明过的方法,而不要给出多余的方法,否则将无法调用到在子类中增加的新方法。
开闭原则、里氏代换原则和依赖倒转原则的关系
开闭原则是目标,里氏代换原则是基础,依赖倒转原则是手段;
第一,要明确,所有的原则都是为了实现面向对象设计的可扩展性,可复用性,可维护性(对原有代码不要进行修改)而定义的。一个已有的代码模块,需要实现可扩展性,需要对外保持开放;为了实现可复用性,需要保持独立(单一职责,高内聚,低耦合);为了实现可维护性,需要对内封闭(对已有代码模块不要进行修改)。即软件实体应尽量在不修改原有代码的情况下进行扩展。所以说开闭原则是目的。
第二,为了实现开闭原则(可扩展性,可维护性和复用性)在最初就需要对代码模块进行抽象化设计(抽象化是实现开闭原则的关键);面向对象思想中的抽象化是指把现实中一类具有相同属性,行为的事物归类的方法。 如果需要修改系统的行为,无须对抽象层进行任何改动,只需要增加新的具体类来实现新的业务功能即可,实现在不修改已有代码的基础上扩展系统的功能,达到开闭原则的要求。具体操作是,针对抽象基类编程(业务逻辑关系的建立),具体运行时代换具体子类对象执行,可以达到开闭原则的目的,该实现过程就是里氏代换原则定义本身,所以说里氏代换原则是理论基础!
第三,通过里氏代换原则的操作过程,大牛们总结出抽象不依赖于细节,细节应该依赖于抽象的依赖倒转原则。具体就是变量、参数、方法返回、数据类型转换等都要用抽象定义声明,再通过依赖注入(构造注入、设值注入和接口注入)或依赖获取的方式将具体对象注入到有依赖关系的对象中。所以说依赖倒转原则是实现目的手段!
举例:
在开闭原则中的举例同样可以应用于依赖倒转原则,因为依赖倒转原则是实现开闭原则的手段。
所以大牛们认为说,在大多数情况下,开闭原则、里氏代换原则和依赖倒转原则,这三个设计原则会同时出现。
接口隔离原则
接口隔离原则(Interface Segregation Principle, ISP):使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
其原则字面的意思是:使用多个隔离的接口,比使用单个接口要好。本意降低类之间的耦合度,而设计模式就是一个软件的设计思想,从大型软件架构出发,为了升级和维护方便才会使用设计模式。所以上文中多次出现:降低依赖,降低耦合。
接口隔离原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少
这个听起来就非常有既视感,和单一职责原则异曲同工。事实也是如此,就像依赖倒转原则是开闭原则的实现手段一样,我的理解是,单一职责原则是接口隔离原则的理论方法,接口隔离原则是单一职责原则的实现手段。
接口从广义上和狭义上的解释是有点差别的:
- 从广义上,“接口”可以理解成一个类型所提供的所有方法特征的集合。这就是一种逻辑上的概念,接口的划分将直接带来类型的划分。可以把接口理解成角色,一个接口只能代表一个角色,每个角色都有它特定的一个接口,此时,这个原则可以叫做“角色隔离原则”。
- 从狭义上,“接口”可以理解成特定语言的接口。那么,接口应该仅仅提供客户端需要的行为,客户端不需要的行为则隐藏起来,应当为客户端提供尽可能小的单独的接口,而不要提供大的总接口。在面向对象编程语言中,实现一个接口就需要实现该接口中定义的所有方法,因此大的总接口使用起来不一定很方便,为了使接口的职责单一,需要将大接口中的方法根据其职责不同分别放在不同的小接口中,以确保每个接口使用起来都较为方便,并都承担某一单一角色。接口应该尽量细化,同时接口中的方法应该尽量少,每个接口中只包含一个客户端(如子模块或业务逻辑类)所需的方法即可,这种机制也称为“定制服务”,即为不同的客户端提供宽窄不同的接口。
举例:
只看解释的话可能不太好理解,如果看图举例子的话就非常好懂了。
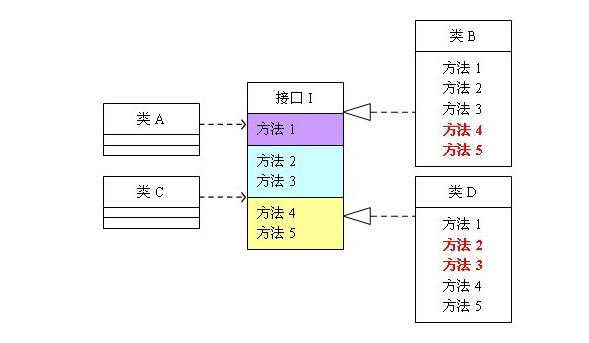
这是一个并没有符合接口隔离原则的实现,
类A会通过接口I调用方法4和方法5,使用的类型是类B
类C会通过接口I调用方法2和方法3,使用的类型是类D
那么很直观的看到,如果按照这样的设计,类B为了实现接口I,还会实现冗余的方法1,方法2,方法3;类D为了实现接口I,还会实现冗余的方法1,方法4,方法5。
这就造成了接口的臃肿。
但是有的同学就会想,可这个设计是符合开闭原则的啊!程序的可维护性和可扩展性也很好,你这接口隔离原则不是跟开闭原则对着干么?
其实没有对着干,只能说这个设计确实满足了开闭原则,但是其实还能有更好的设计,不但能满足开闭原则,还能满足接口隔离原则,两个原则是从不同的角度来评判代码的好坏的,并无矛盾。
那么使用接口隔离原则优化后的实现如下:
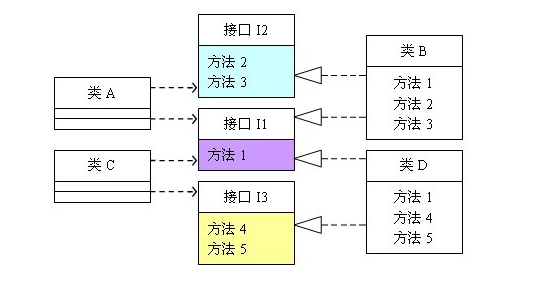
这样,细化了臃肿庞大的接口I,按照不同的方法分成了接口I1,接口I2,接口I3,这样类B和类D就只需要实现会被用到的方法,不会产生代码冗余。
这时候有的同学就会想,那你这维护性差了啊!那万一之后我类A需要用到方法4了,那你这设计不是完了么,增加类B的实现倒还好,能满足开闭原则,但是要改类A的接口,就不满足开闭原则了啊。
确实如此了,这就只能特定场景特定分析,这个例子的前提就是类A不会使用到方法4,但是实际工作场景中可没有这么多绝对限制条件。
所以采用接口隔离原则对接口进行约束时,要注意以下几点:
- 接口尽量小,但是要有限度。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
- 为依赖接口的类定制服务,只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来。只有专注地为一个模块提供定制服务,才能建立最小的依赖关系。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。
运用接口隔离原则,一定要适度,接口设计的过大或过小都不好。设计接口的时候,只有多花些时间去思考和筹划,才能准确地实践这一原则。
合成复用原则
合成复用原则(Composite Reuse Principle, CRP):尽量使用对象组合,而不是继承来达到复用的目的。
合成复用原则又称为组合/聚合复用原则,在人们常说的六大设计原则中是不包含合成复用原则的,但是合成复用原则还是值得一提的。
合成复用原则就是在一个新的对象里通过关联关系(包括组合关系和聚合关系)来使用一些已有的对象,使之成为新对象的一部分;新对象通过委派调用已有对象的方法达到复用功能的目的。简言之:复用时要尽量使用组合/聚合关系(关联关系),少用继承。
在面向对象设计中,可以通过两种方法在不同的环境中复用已有的设计和实现,即通过组合/聚合关系或通过继承,但首先应该考虑使用组合/聚合,组合/聚合可以使系统更加灵活,降低类与类之间的耦合度,一个类的变化对其他类造成的影响相对较少;其次才考虑继承,在使用继承时,需要严格遵循里氏代换原则,有效使用继承会有助于对问题的理解,降低复杂度,而滥用继承反而会增加系统构建和维护的难度以及系统的复杂度,因此需要慎重使用继承复用。
通过继承来进行复用的主要问题在于继承复用会破坏系统的封装性,因为继承会将基类的实现细节暴露给子类,由于基类的内部细节通常对子类来说是可见的,所以这种复用又称“白箱”复用,如果基类发生改变,那么子类的实现也不得不发生改变;从基类继承而来的实现是静态的,不可能在运行时发生改变,没有足够的灵活性;而且继承只能在有限的环境中使用(如类没有声明为不能被继承)。
举例:
从我个人角度而言,里氏代换原则是对继承关系而言的,那么合成复用原则就是里氏代换原则的补集。不如说,我感觉我在工作中写的所有代码,都无时无刻不在使用合成复用原则。
从对象设计的角度来将,往往是先抽象,再实现细节,那么如果我需要组装一台电脑,我就会这么干:
class Computer //电脑-CPU {abstruct}
+SetCpu() -主板 {abstruct}
+Set主板()-显卡 {abstruct}
+Set显卡()-电源 {abstruct}
+Set电源()-制冷 {abstruct}
+Set制冷()...模块化的组合,类与类之间职责并不相关,但是Computer类会通过合成复用原则将这一堆东西组合在一起,每一部分都可以进行复用,也可以进行替换。
这么一看,合成复用原则反而是最常用的原则了,可能就是因为太常用,所以人们在说六大设计原则时,不带合成复用原则玩吧。
迪米特法则
迪米特法则(Law of Demeter, LoD):一个软件实体应当尽可能少地与其他实体发生相互作用。一个对象应该对其他对象保持最少的了解。
设计原则排名不分先后,但这个是最后一个介绍的设计原则了。
迪米特法则又称为最少知识原则(LeastKnowledge Principle, LKP),来自于1987年美国东北大学(Northeastern University)一个名为“Demeter”的研究项目。
如果一个系统符合迪米特法则,那么当其中某一个模块发生修改时,就会尽量少地影响其他模块,扩展会相对容易,这是对软件实体之间通信的限制,迪米特法则要求限制软件实体之间通信的宽度和深度。迪米特法则可降低系统的耦合度,使类与类之间保持松散的耦合关系。
迪米特法则还有几种定义形式,包括:不要和“陌生人”说话、只与你的直接朋友通信等,在迪米特法则中,对于一个对象,其朋友包括以下几类:
- 当前对象本身(this);
- 以参数形式传入到当前对象方法中的对象;
- 当前对象的成员对象;
- 如果当前对象的成员对象是一个集合,那么集合中的元素也都是朋友;
- 当前对象所创建的对象。
任何一个对象,如果满足上面的条件之一,就是当前对象的“朋友”,否则就是“陌生人”。在应用迪米特法则时,一个对象只能与直接朋友发生交互,不要与“陌生人”发生直接交互,这样做可以降低系统的耦合度,一个对象的改变不会给太多其他对象带来影响。
如果两个对象之间不必彼此直接通信,那么这两个对象就不应当发生任何直接的相互作用,如果其中的一个对象需要调用另一个对象的某一个方法的话,可以通过第三者转发这个调用。
简言之,就是通过引入一个合理的第三者来降低现有对象之间的耦合度。
举例:
比如说我作为北漂,现在要租房,但是我这人怕麻烦,并且我的目的只有一个,租房,我并不想了解这房主多少岁,在哪工作,我甚至不想与房主有交集。
而房主呢,可能在外地,想租出去,但又不知道谁要租房。
如果没有迪米特法则,那么就不太可能实现,我租房子只能直接与房东联系。
class I //这是我fangyuan {abstruct} //这是我的需求,房源+ZhuFang() //这是我的目的,我要住房fangdong[] {abstruct}[] //但是我没办法,只能和房东直接沟通,房东肯定有很多位+GetFangDongTCP() //获取到房东联系方式+SendMessage() //给房东发租房需求+GetMessage() //获取房东的房源需求我只能一户一户问,和房东类出现大量无用关系耦合。
迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。
class I //这是我fangyuan {abstruct} //这是我的需求,房源+ZhuFang() //这是我的目的,我要住房ZhongJie {abstruct} //我现在不用找一大堆房东了,我找个中介干+GetZhongJieTCP() //获取到房东联系方式+GetMessage() //获取房源
有了迪米特法则,我加了个中介,只用从他那获取到房源就行(这里不讨论三次握手等数据通信理论),我也不用去认识一大堆房东,中介就是第三者,能减少我跟房东之间的联系耦合度。
只是个简单的例子,大家理解就好。
但是凡事都有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系。例如本例中,“我”就是通过“中介”来与“房东”发生联系的。过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。
所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
总结
理论看一遍就能懂,实践起来可就不是一朝一夕能学会的事了,这个需要大量的实践才能慢慢融会贯通,就像“开闭原则是目标,里氏代换原则是基础,依赖倒转原则是手段”,这句话,如果没有任何工作经验,我必然是无法理解的,而现在也只是理解而已,真正能无缝衔接,运用自如,就不知何年何月了。
理论和实践必定不同,比如,raft算法保证数据一致性,理论非常精妙,但厂商实际应用时,考虑到性能,谁又会完完全全照着来呢。
几大设计原则也是,在我翻阅的介绍中,都会重点强调一句话,需要反复权衡,力度未到不行,过犹不及不行,掌握火候,才考验的出程序员的深浅。
参考文献
面向对象设计之魂的六大原则 - 知乎
面向对象六大设计原则 - 月染霜华 - 博客园
面向对象设计原则概述_刘伟技术博客-CSDN博客_面向对象设计准则有哪些
面向对象设计原则之开闭原则_刘伟技术博客-CSDN博客_如何实现开闭原则
面向对象设计原则之里氏代换原则_刘伟技术博客-CSDN博客_里是替换原则
面向对象设计原则之接口隔离原则_刘伟技术博客-CSDN博客
这篇关于【学习设计模式2】设计模式指导思想—面向对象设计原则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








