本文主要是介绍自动化行业文件数据\资料防泄密软件——天锐绿盾|@德人合科技,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
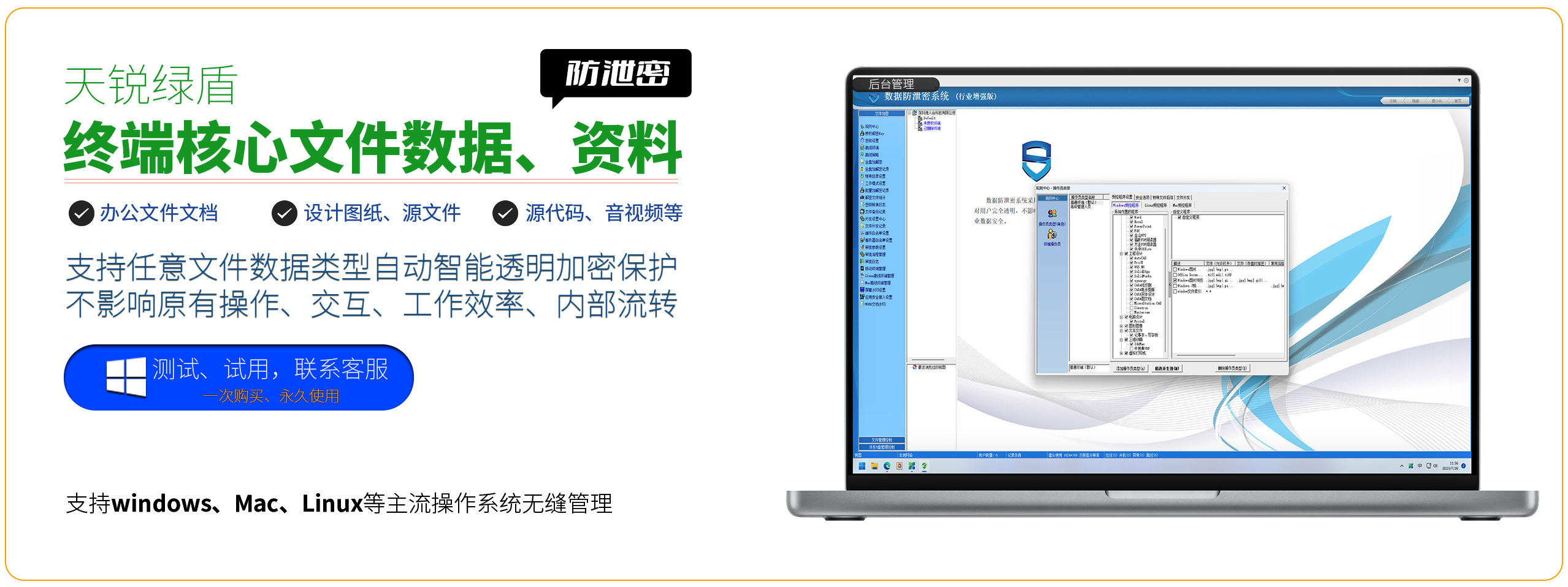
天锐绿盾是一款自动化行业文件数据防泄密软件,由德人合科技提供。该软件采用动态加解密技术,能够有效防止公司内部数据泄密,同时支持各种文件格式加密,如CAD、OFFICE、PDF、图纸等。

PC端:https://isite.baidu.com/site/wjz012xr/2eae091d-1b97-4276-90bc-6757c5dfedee
天锐绿盾具有事前主动防御、事中安全可控、事后有据可查的特点。在事前主动防御方面,软件在文件创建、编辑存盘时自动加密,防止硬盘、笔记本丢失造成的被动泄密。同时,提供多种加密模式灵活管理,严格的文件阅读权限,防止外出办公泄密,还提供文件外发管理方案。
移动端:http://tinyurl.com/5n977ttn
在事中安全可控方面,天锐绿盾具有上网行为管理、网络传输控制、硬件设备控制等功能,能够提升IT运维效率,并通过行为审计系统实现事后有据可查。软件可以记录网页浏览记录、邮件收发监控等,确保企业数据的安全。
此外,天锐绿盾还支持各种应用系统,如Windows、mac、Linux等操作系统上的业务应用软件加密,如PDM、PLM、ERP、OA、CRM等。软件支持局域网部署和互联网部署模式,支持总部和异地分支机构分别部署,同时支持单机部署模式,确保公司内部资料的相互流通。

www.drhchina.com
总之,天锐绿盾是一款功能强大的全行业把终端文件数据\ 资料防泄密软件,能够帮助企业实现数据的安全保护,避免数据泄密和非法扩散的风险。德人合科技作为该软件的提供商,可以为企业提供全面的技术支持和服务。
#深圳德人合科技有限公司#
这篇关于自动化行业文件数据\资料防泄密软件——天锐绿盾|@德人合科技的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





