本文主要是介绍力扣645. 错误的集合(排序,哈希表),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Problem: 645. 错误的集合
文章目录
- 题目描述
- 思路
- 复杂度
- Code
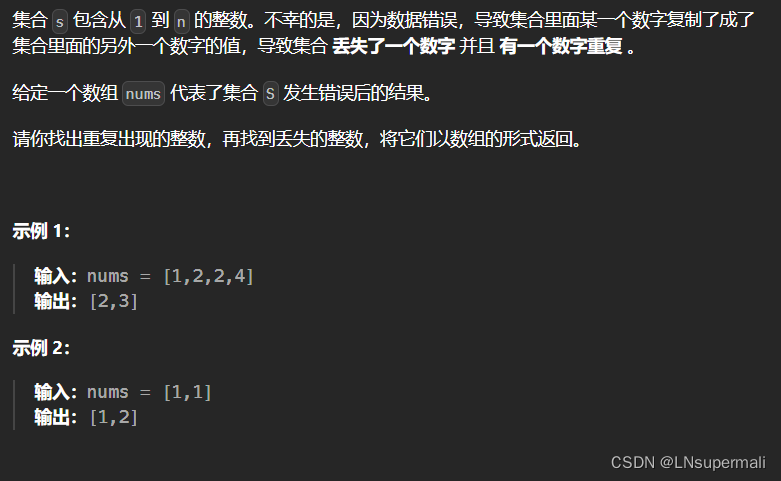
题目描述

思路
1.排序
1.对nums数组按从小到大的顺序排序;
2.遍历数组时若判断两个相邻的元素则找到重复元素;
3.记录一个整形变量prev一次置换当前位置元素并与其作差,若差等于2着说明缺失的数即为这中间的一个数(由于缺失的数可能是1,则初始化prev为0)
4.由于nums中本该记录1-n,则若nums[n - 1] != n,则说明缺失的数是n;
2.哈希表
1.对nums中的元素进行统计(以其大小为键,出现的次数为值);
2.从1-n开始遍历,若某一个值出现2次则为重复元素,若一个值没有出现(其值为0)则为缺失值
复杂度
思路1:
时间复杂度:
O ( n l o g n ) O(nlogn) O(nlogn);其中 n n n为数组nums的大小
空间复杂度:
O ( n ) O(n) O(n)
思路2 :
时间复杂度:
O ( n ) O(n) O(n)
空间复杂度:
O ( n ) O(n) O(n)
Code
思路1:
class Solution {
public:/*** Sort* * @param nums Given array* @return vector<int>*/vector<int> findErrorNums(vector<int>& nums) {int n = nums.size();vector<int> res(2);sort(nums.begin(), nums.end());int prev = 0;for (int i = 0; i < n; ++i) {int curr = nums[i];if (curr == prev) {res[0] = prev;} else if (curr - prev > 1) {res[1] = prev + 1;}prev = curr;}if (nums[n - 1] != n) {res[1] = n;}return res;}
};
思路2:
class Solution {
public:/*** Hash* * @param nums Given array* @return vector<int>*/vector<int> findErrorNums(vector<int>& nums) {vector<int> res(2);int n = nums.size();unordered_map<int, int> map;for (auto& num : nums) {map[num]++;}for (int i = 1; i <= n; ++i) {int count = map[i];if (count == 2) {res[0] = i;} else if (count == 0) {res[1] = i;}}return res;}
};
这篇关于力扣645. 错误的集合(排序,哈希表)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





