本文主要是介绍6. 只要肯下功夫,10岁也能学的会的Kubernetes 控制器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、控制器简介
- 二、ReplicationController和ReplicaSet
- 三、Deployment
- 3.1 Deployment介绍和使用
- 3.2 扩容
- 3.3 更新
- 3.4 回滚
- 四、DaemonSet
- 五、Job/CronJob
- 六、StateFulSet
- 七、Horizontal Pod Autoscaling
一、控制器简介
Kubernetes中内建了很多 controller(控制器),这些相当于一个状态机,用来控制 Pod的具体状态和行为。 控制器大致分为如下介绍六种:
二、ReplicationController和ReplicaSet
ReplicationController( RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的 Pod来替代;而如果异常多出来的容器也会自动回收;
在新版本的 Kubernetes中建议使用 ReplicaSet来取代 RC。 ReplicaSet跟 RC没有本质的不同,只是名字不一样,并且 ReplicaSet支持集合式的 selector。
案例:
[root@master resource]apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:name: frontend
spec:replicas: 3selector:matchLabels:tier: frontendtemplate:metadata:labels:tier: frontendspec:containers:- name: myappimage: hub.hc.com/library/myapp:v1env:- name: GET_HOSTS_FROMvalue: dnsports:- containerPort: 80[root@master resource]
[root@master resource]
NAME READY STATUS RESTARTS AGE
frontend-44vbw 1/1 Running 0 21s
frontend-9lx78 1/1 Running 0 21s
frontend-q54pf 1/1 Running 0 21s[root@master resource]
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 60s[root@master resource]
pod "frontend-44vbw" deleted[root@master resource]
NAME READY STATUS RESTARTS AGE
frontend-9lx78 1/1 Running 0 15m
frontend-q54pf 1/1 Running 0 15m
frontend-scbzb 1/1 Running 0 14s
三、Deployment
3.1 Deployment介绍和使用
Deployment为 Pod和 ReplicaSet提供了一个声明式定义 (declarative) 方法,用来替代以前的 RC来方便的管理应用。
典型的应用场景包括:
- 定义
Deployment来创建Pod和ReplicaSet - 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续
Deployment
RS与 Deployment的关联:
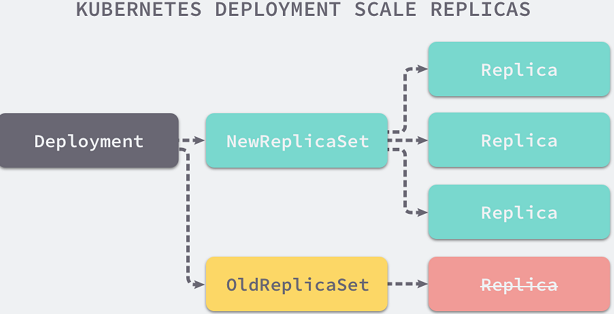
案例:
[root@master resource]apiVersion: extensions/v1beta1
kind: Deployment
metadata:name: nginx-deployment
spec:replicas: 3template:metadata:labels:app: nginxspec:containers:- name: nginximage: hub.hc.com/library/myapp:v1ports:- containerPort: 80[root@master resource]
deployment.extensions/nginx-deployment created[root@master resource]
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 13s[root@master resource]
NAME DESIRED CURRENT READY AGE
nginx-deployment-6b4dcdb44b 3 3 3 6m50s[root@master resource]
NAME READY STATUS RESTARTS AGE
nginx-deployment-6b4dcdb44b-bwzwq 1/1 Running 0 6m28s
nginx-deployment-6b4dcdb44b-kmv66 1/1 Running 0 6m28s
nginx-deployment-6b4dcdb44b-xmpcf 1/1 Running 0 6m28s

3.2 扩容
案例:
[root@master resource]
deployment.extensions/nginx-deployment scaled[root@master resource]
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 5/5 5 5 20m[root@master resource]
NAME READY STATUS RESTARTS AGE
nginx-deployment-6b4dcdb44b-b9knj 1/1 Running 0 43s
nginx-deployment-6b4dcdb44b-bwzwq 1/1 Running 0 20m
nginx-deployment-6b4dcdb44b-j278k 1/1 Running 0 43s
nginx-deployment-6b4dcdb44b-kmv66 1/1 Running 0 20m
nginx-deployment-6b4dcdb44b-xmpcf 1/1 Running 0 20m
如果集群支持 horizontal pod autoscaling的话,还可以为 Deployment设置自动扩展:
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
3.3 更新
案例:
[root@master resource]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6b4dcdb44b-b9knj 1/1 Running 0 5m58s 10.244.2.20 worker2 <none> <none>
nginx-deployment-6b4dcdb44b-bwzwq 1/1 Running 0 26m 10.244.2.18 worker2 <none> <none>
nginx-deployment-6b4dcdb44b-j278k 1/1 Running 0 5m58s 10.244.1.15 worker1 <none> <none>
nginx-deployment-6b4dcdb44b-kmv66 1/1 Running 0 26m 10.244.1.14 worker1 <none> <none>
nginx-deployment-6b4dcdb44b-xmpcf 1/1 Running 0 26m 10.244.2.19 worker2 <none> <none>[root@master resource]
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>[root@master resource]
deployment.extensions/nginx-deployment image updated[root@master resource]
NAME DESIRED CURRENT READY AGE
nginx-deployment-5c478875d8 5 5 5 72s
nginx-deployment-6b4dcdb44b 0 0 0 31m[root@master resource]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-5c478875d8-b5kh2 1/1 Running 0 83s 10.244.2.21 worker2 <none> <none>
nginx-deployment-5c478875d8-hrzl8 1/1 Running 0 65s 10.244.1.17 worker1 <none> <none>
nginx-deployment-5c478875d8-jvvbz 1/1 Running 0 83s 10.244.1.16 worker1 <none> <none>
nginx-deployment-5c478875d8-nm2cf 1/1 Running 0 64s 10.244.2.22 worker2 <none> <none>
nginx-deployment-5c478875d8-wj5w5 1/1 Running 0 52s 10.244.1.18 worker1 <none> <none>[root@master resource]
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>[root@master resource]
Deployment更新策略:
Deployment可以保证在升级时只有一定数量的 Pod是 down的。默认的,它会确保至少有比期望的 Pod数量少一个是 up状态(最多一个不可用)
Deployment同时也可以确保只创建出超过期望数量的一定数量的 Pod。默认的,它会确保最多比期望的 Pod数量多一个的 Pod是 up的(最多1个 surge)
未来的 Kuberentes版本中,将从1-1变成25%-25%
3.4 回滚
案例:
[root@master resource]
deployment.extensions/nginx-deployment rolled back[root@master resource]
NAME DESIRED CURRENT READY AGE
nginx-deployment-5c478875d8 0 0 0 5m34s
nginx-deployment-6b4dcdb44b 5 5 5 35m[root@master resource]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6b4dcdb44b-5qk6n 1/1 Running 0 45s 10.244.2.23 worker2 <none> <none>
nginx-deployment-6b4dcdb44b-72zvc 1/1 Running 0 43s 10.244.2.24 worker2 <none> <none>
nginx-deployment-6b4dcdb44b-c2dls 1/1 Running 0 43s 10.244.1.20 worker1 <none> <none>
nginx-deployment-6b4dcdb44b-d8mwz 1/1 Running 0 42s 10.244.2.25 worker2 <none> <none>
nginx-deployment-6b4dcdb44b-p8ttm 1/1 Running 0 44s 10.244.1.19 worker1 <none> <none>[root@master resource]
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>[root@master resource]
deployment "nginx-deployment" successfully rolled out
Deployment回滚策略(多个rollout并行):
假如您创建了一个有5个 niginx:1.7.9 replica的 Deployment,但是当还只有3个 nginx:1.7.9的 replica创建出来的时候您就开始更新含有5个 nginx:1.9.1 replica的 Deployment。在这种情况下, Deployment会立即杀掉已创建的3个 nginx:1.7.9的 Pod,并开始创建 nginx:1.9.1的 Pod。它不会等到所有的5个 nginx:1.7.9的 Pod都创建完成后才开始改变航道
更多回滚操作:
$ kubectl rollout history deployment/nginx-deployment$ kubectl rollout undo deployment/nginx-deployment --to-revision=2$ kubectl rollout pause deployment/nginx-deployment
清理Policy:
您可以通过设置 spec.revisonHistoryLimit项来指定 Deployment最多保留多少 revision历史记录。默认的会保留所有的 revision;如果将该项设置为0, Deployment就不允许回退了。
四、DaemonSet
DaemonSet确保全部(或者一些) Node上运行一个 Pod的副本。当有 Node加入集群时,也会为他们新增一个 Pod。当有 Node从集群移除时,这些 Pod也会被回收。删除 DaemonSet将会删除它创建的所有 Pod。
使用 DaemonSet的一些典型用法:
- 运行集群存储
daemon,例如在每个Node上运行glusterd、ceph - 在每个
Node上运行日志收集daemon,例如fluentd、logstash - 在每个
Node上运行监控daemon,例如Prometheus Node Exporter、collectd、Datadog代理、New Relic代理,或Ganglia gmond
案例:
[root@master resource]apiVersion: apps/v1
kind: DaemonSet
metadata:name: deamonset-examplelabels:app: daemonset
spec:selector:matchLabels:name: deamonset-exampletemplate:metadata:labels:name: deamonset-examplespec:containers:- name: daemonset-exampleimage: hub.hc.com/library/myapp:v1[root@master resource]
daemonset.apps/deamonset-example created[root@master resource]
NAME READY STATUS RESTARTS AGE
deamonset-example-jjd5z 1/1 Running 0 7s
deamonset-example-nltnz 1/1 Running 0 7s[root@master resource]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deamonset-example-jjd5z 1/1 Running 0 14s 10.244.2.26 worker2 <none> <none>
deamonset-example-nltnz 1/1 Running 0 14s 10.244.1.21 worker1 <none> <none>
五、Job/CronJob
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod成功结束。
** Job 使用注意事项:**
RestartPolicy仅支持Never或OnFailure- 单个
Pod时,默认Pod成功运行后Job即结束 .spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
案例:
[root@master resource]apiVersion: batch/v1
kind: Job
metadata:name: pi
spec:template:metadata:name: pispec:containers:- name: piimage: perlcommand: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]restartPolicy: Never[root@master resource]
job.batch/pi created[root@master resource]
NAME COMPLETIONS DURATION AGE
pi 0/1 5s 5s[root@master resource]
NAME READY STATUS RESTARTS AGE
pi-g694b 1/1 Running 0 9s[root@master resource]
NAME READY STATUS RESTARTS AGE
pi-g694b 0/1 Completed 0 28s[root@master resource]
log is DEPRECATED and will be removed in a future version. Use logs instead.3.14159265358979323846264338327950288419716939937510582097494...Cron Job管理基于时间的 Job,即:在给定时间点只运行一次 && 周期性地在给定时间点运行。
使用前提条件:当前使用的 Kubernetes集群,版本 >= 1.8(对 CronJob);对于先前版本的集群,版本
典型的用法如下所示:
- 在给定的时间点调度
Job运行 - 创建周期性运行的
Job,例如:数据库备份、发送邮件
CronJob spec用法:
.spec.schedule:调度,必需字段,指定任务运行周期,格式同Cron.spec.jobTemplate:Job模板,必需字段,指定需要运行的任务,格式同Job.spec.startingDeadlineSeconds:启动Job的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的Job将被认为是失败的。如果没有指定,则没有期限.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被Cron Job创建的Job的并发执行。只允许指定下面策略中的一种:Allow(默认):允许并发运行JobForbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个Replace:取消当前正在运行的Job,用一个新的来替换注意,当前策略只能应用于同一个Cron Job创建的Job。如果存在多个Cron Job,它们创建的Job之间总是允许并发运行。
.spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的Job不起作用。默认值为false。.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job。默认情况下,它们分别设置为3和1。设置限制的值为0,相关类型的Job完成后将不会被保留。
案例:
[root@master resource]apiVersion: batch/v1beta1
kind: CronJob
metadata:name: hello
spec:schedule: "*/1 * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: busyboxargs:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure[root@master resource]
cronjob.batch/hello created[root@master resource]
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 1 13s 15s[root@master resource]
NAME COMPLETIONS DURATION AGE
hello-1574487960 0/1 11s 11s[root@master resource][root@master resource]
Sat Nov 23 05:46:27 UTC 2019
Hello from the Kubernetes cluster
六、StateFulSet
StatefulSet作为 Controller为 Pod提供唯一的标识。它可以保证部署和 scale的顺序
StatefulSet是为了解决有状态服务的问题(对应 Deployments和 ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即
Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现 - 稳定的网络标志,即
Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现 - 有序部署,有序扩展,即
Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现 - 有序收缩,有序删除(即从
N-1到0)
七、Horizontal Pod Autoscaling
应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让 service中的 Pod个数自动调整呢?这就有赖于 Horizontal Pod Autoscaling了,顾名思义,使 Pod水平自动缩放。
这篇关于6. 只要肯下功夫,10岁也能学的会的Kubernetes 控制器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





