本文主要是介绍Flink中的双流Join,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Flink中双流Join介绍
| Flink版本 | Join支持类型 | Join API |
| 1.4 | inner | Table/SQL |
| 1.5 | inner,left,right,full | Table/SQL |
| 1.6 | inner,left,right,full | Table/SQL/DataStream |
Join大体分为两种:Window Join 和 Interval Join 两种。
Window Join又可以根据Window的类型细分为3种:
Tumbling Window Join、Sliding Window Join、Session Window Join。
Windows类型的join都是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;所以实际开发注意状态的过期时间,免得关联不到数据
目前Stream join的结果是数据的笛卡尔积;
2. Window Join
将两条实时流中元素分配到一个时间窗口中完成 Join
-
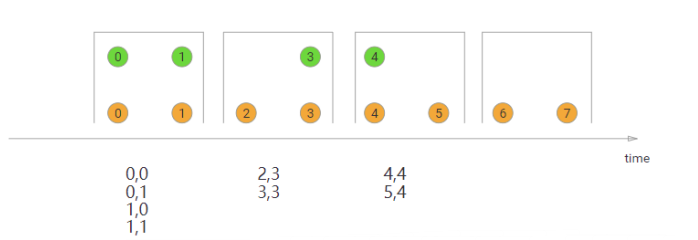
Tumbling Window Join(滚动窗口)
执行翻滚窗口联接时,具有公共键和公共翻滚窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。因为它的行为类似于内部连接,所以一个流中的元素在其滚动窗口中没有来自另一个流的元素,因此不会被发射!
如图所示,我们定义了一个大小为2毫秒的翻滚窗口,结果窗口的形式为[0,1]、[2,3]、。。。。该图显示了每个窗口中所有元素的成对组合,这些元素将传递给JoinFunction。注意,在翻滚窗口[6,7]中没有发射任何东西,因为绿色流中不存在与橙色元素⑥和⑦结合的元素。
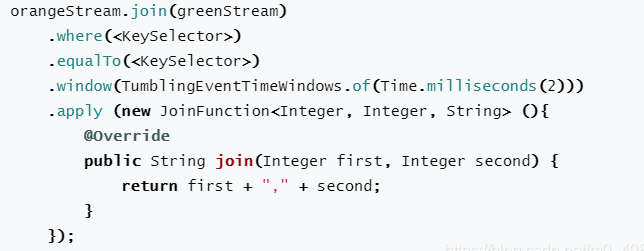
-
Sliding Window Join(滑动窗口)
在执行滑动窗口联接时,具有公共键和公共滑动窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。在当前滑动窗口中,一个流的元素没有来自另一个流的元素,则不会发射!请注意,某些元素可能会连接到一个滑动窗口中,但不会连接到另一个滑动窗口中!
在本例中,我们使用大小为2毫秒的滑动窗口,并将其滑动1毫秒,从而产生滑动窗口[-1,0],[0,1],[1,2],[2,3]…。x轴下方的连接元素是传递给每个滑动窗口的JoinFunction的元素。在这里,您还可以看到,例如,在窗口[2,3]中,橙色②与绿色③连接,但在窗口[1,2]中没有与任何对象连接。


-
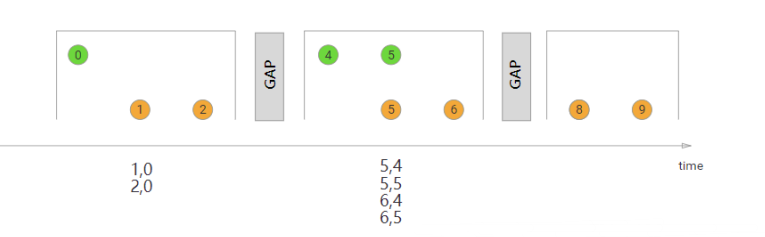
Session Window Join(会话窗口)
在执行会话窗口联接时,具有相同键(当“组合”时满足会话条件)的所有元素以成对组合方式联接,并传递给JoinFunction或FlatJoinFunction。同样,这执行一个内部连接,所以如果有一个会话窗口只包含来自一个流的元素,则不会发出任何输出!
在这里,我们定义了一个会话窗口连接,其中每个会话被至少1ms的间隔分割。有三个会话,在前两个会话中,来自两个流的连接元素被传递给JoinFunction。在第三个会话中,绿色流中没有元素,所以⑧和⑨没有连接!

两条流数据按照关联主键在这三种窗口内进行inner join,底层基于State存储,并支持处理时间和事件时间两种特征
3. Interval Join
Window Join必须要在一个Window中进行JOIN,那如果没有Window如何处理呢?
interval join根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join。
也是使用相同的key来join两个流(流A、流B),并且流B中的元素中的时间戳,和流A元素的时间戳,有一个时间间隔。
条件:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
也就是
流B的元素的时间戳 >= 流A的元素时间戳 + 下界,且,流B的元素的时间戳<=流A的元素时间戳+上界

在上面的示例中,我们将两个流“orange”和“green”连接起来,其下限为-2毫秒,上限为+1毫秒。默认情况下,这些边界是包含的,但是可以应用.lowerBoundExclusive()和.upperBoundExclusive来更改行为.
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound
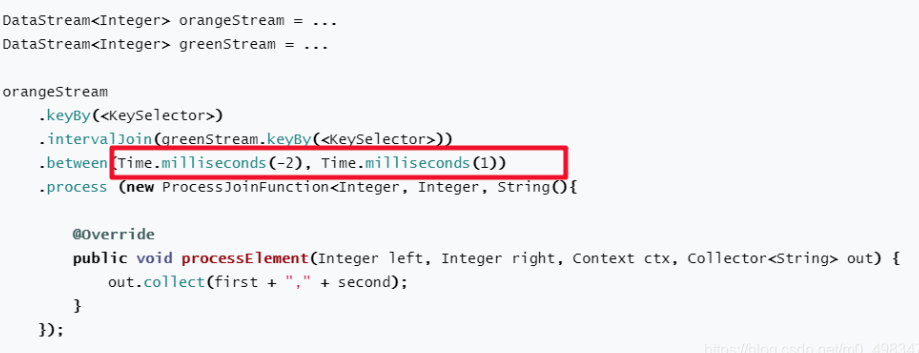
在流入程序后,等候(low,high)时间间隔内的数据进行join, 否则继续处理下一个流。
从代码中我们发现,interval join需要在两个KeyedStream之上操作,即keyBy(),并在between()方法中指定偏移区间的上下界。
需要注意的是interval join实现的也是inner join,且目前只支持事件时间。
这篇关于Flink中的双流Join的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


