本文主要是介绍1.deeplabv3+网络结构及原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里的网络结构及原理可以看这篇博客,DeepLabV3+: 在DeepLabV3基础上引入了Decoder_matlab deeplabv3+resnet101-CSDN博客该博客翻译原论文解释得很清楚。
一、引言
语义分割的目标是为图像中的每个像素分配语义标签。在这项研究中,考虑了两种类型的神经网络:使用了空间金字塔池化的模块、编解码器结构;前者可以通过在不同分辨率下汇集特性来获取丰富的上下文信息,后者能够获得清晰的物体边界。
为了在不同尺度下获得上下文信息,DeepLabv3使用了几个并行的不同速率的空洞卷积(空洞空间金字塔池化,ASPP);而PSPNet则是在不同网格尺度上执行池化操作。尽管在最后一个feature map上编码了丰富的语义信息,但由于在网络backbone中使用了带有步长的池化或者卷积操作,与物体边界相关的细节信息却丢失了。这个问题,可以通过使用空洞卷积提取密集的feature maps来改善。
DeepLabv3+,通过增加一个简单有效的解码器模块扩展了DeepLabv3,以恢复物体边界。在DeepLabv3的输出中,已经编码了丰富的语义信息,其使用空洞卷积来控制编码特征的密度,这取决于计算资源。此外,解码器模块可以恢复详细的物体边界。本质上deeplabv3+就是deeplabv3加上一个decoder.
总体来讲,贡献如下:
- 在DeepLabv3基础上,加了一个解码器;
- 可以通过控制空洞卷积速率来任意改变编码器输出的feature map分辨率;
- 使用Xception作为backbone(也可使用ResNet101等),并在ASPP和解码器模块中使用了深度可分离卷积,从而产生了一个更快、更强的编解码网络;
- 该模型达到了新的SOTA;
- 开源了代码;
二、网络结构
DeepLabV3+的网络结构如下图所示,主要为Encoder-Decoder结构。
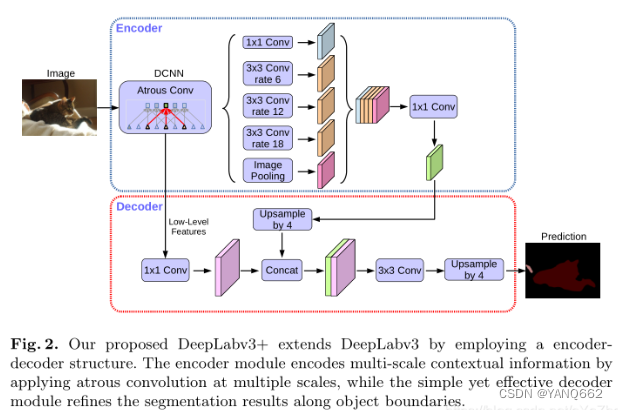
Encoder-decoder: 编解码结构已经被用于多种计算机视觉任务,如人体姿态估计、目标检测、语义分割。通常,编码器-解码器网络包含(1)一个编码器模块(Encoder),逐步减少特征映射并捕获更高的语义信息,(2)一个解码器模块(Decoder),逐步恢复空间信息。在此基础上,我们提出了使用DeepLabv3作为编码器模块,并添加一个简单而有效的解码器模块,以获得更清晰的分割。
1.Encoder
在encoder部分,主要包括了backbone(DCNN)、ASPP两大部分。encoder中连接的第一个模块是DCNN, 他代表的是用于提取图片特征的主干网络,DCNN右边是一个ASPP网络,他用一个1*1的卷积、3个3*3的 空洞卷积和一个全局池化来对主干网络的输出进行处理。然后再将其结果都连接起来并用一个1*1的卷积 来缩减通道数。具体如下:
- 其中backbone有两种网络结构:将layer4改为空洞卷积的Resnet系列、改进的Xception。从backbone出来的feature map分两部分:一部分是最后一层卷积输出的feature maps,另一部分是中间的低级特征的feature maps;backbone输出的第一部分送入ASPP模块,第二部分则送入Decoder模块。
- ASPP模块接受backbone的第一部分输出作为输入,使用了四种不同膨胀率的空洞卷积块(包括卷积、BN、激活层)和一个全局平均池化块(包括池化、卷积、BN、激活层)得到一共五组feature maps,将其concat起来之后,经过一个1*1卷积块(包括卷积、BN、激活、dropout层),最后送入Decoder模块。
可分离空洞卷积的优点:
- 减小计算量,是普通卷积计算量的1/9;
- 扩大感受野:神经网络加深,单个像素感受野扩大,但特征图尺寸缩小,空间分辨率降低,为此,空洞卷积出现了,一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
- 捕获多尺度上下文信息:两列之间填充 (r-1) 个0,这个 r 可自己设置,不同 r 可得到不同尺度信息。
2.Decoder
在Decoder部分,接收来自backbone中间层的低级feature maps和来自ASPP模块的输出作为输入。
- 首先,对低级feature maps使用1*1卷积进行通道降维,从256降到48(之所以需要降采样到48,是因为太多的通道会掩盖ASPP输出的feature maps的重要性,且实验验证48最佳);
- 然后,对来自ASPP的feature maps进行插值上采样,得到与低级featuremaps尺寸相同的feature maps;
- 接着,将通道降维的低级feature maps和线性插值上采样得到的feature maps使用concat拼接起来,并送入一组3*3卷积块进行处理;
- 最后,再次进行线性插值上采样,得到与原图分辨率大小一样的预测图。
3.Xception
Xception网络结构如下:
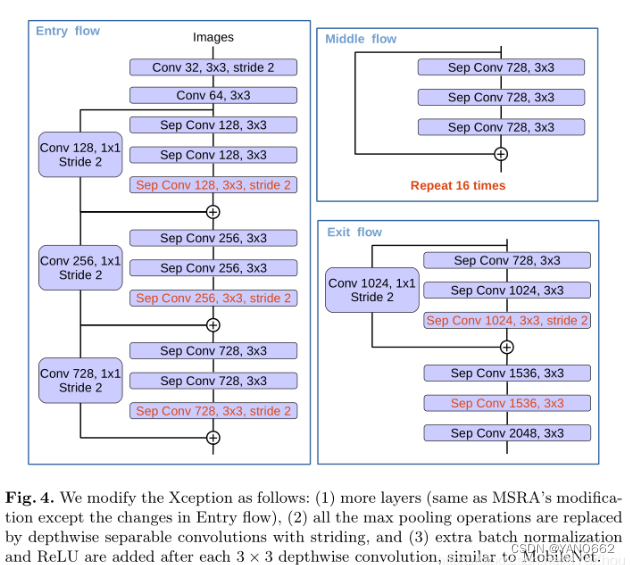
Xception网络是由inception结构加上depthwise separable convlution,再加上残差网络结构改进而来。Xception结构由36层卷积层组成网络的特征提取基础,分为Entry flow,Middle flow,Exit flow;被分成了14个模块,除了第一个和最后一个外,其余模块间均有线性残差连接。
Xception结构演变:(轻量化网络结构——Xception_xception网络结构-CSDN博客)
Xception 并不是真正意义上的轻量化模型,是Google继Inception后提出的对Inception v3的另一种改进,主要是采用depthwise separable convolution来替代原来的Inception v3中的卷积操作,这种性能的提升是来自于更有效的使用模型参数而不是提高容量。
既然是在Inception v3上进行改进的,那么Xception是如何一步一步的从Inception v3演变而来。Inception v3结构如下图1(这个网络结构是最基础的google提出的inceptuon网络结构的改进,大家可以查找资料进一步了解)
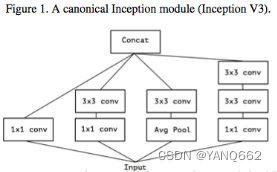
注:1x1卷积的作用: 1)降维:较少计算量 2)升维:小型网络,通道越多,效果会更好 3)1x1是有一个参数学习的卷积层,可以增加跨通道的相关性。
下图简化了上图的inception module(就只考虑1x1的那条支路,不包含Avg pool)如下:

下图把上图的第一部分的3个1x1卷积核统一起来,变成1个1x1的卷积核,然后连接3个3x3的卷积,这3个卷积操作只将前面1x1卷积结果中的一部分作为自己的输入(只负责一部分通道)。

下图An“extreme” version of Inception module,先用1x1卷积核对各通道之间(cross-channel)进行卷积,之后使用3x3的卷积对每个输出通道进行卷积操作,也就是3x3卷积的个数和1x1卷积的输出channel个数相同。
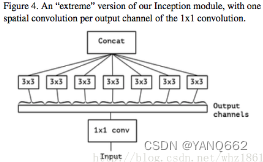
在Xception中主要采用depthwise separable convolution,和原版的相比有两个不同之处:
(1)原版的Depthwise convolution,先是逐通道卷积,再1x1卷积;而Xception是反过来,先1x1卷积,再逐通道卷积。
(2)原版Depthwise convolution的两个卷积之间是不带激活函数的,而Xception再经过1x1卷积之后会带上一个Relu的非线性激活函数。
三、结论
我们提出的模型“DeepLabv3+”采用了编码器-解码器结构,其中使用DeepLabv3对丰富的上下文信息进行编码,采用简单有效的解码器模块恢复对象边界。也可以根据可用的计算资源,应用空洞卷积以任意分辨率提取编码器特征。还对Xception模型和空洞可分离卷积进行了研究,使所提出的模型更快、更强。最后,我们的实验结果表明,所提出的模型在PASCAL VOC 2012和Cityscapes数据集达到SOTA。
一句话总结DeepLabV3+:
DeepLabv3作为Encoder提取特征,上采样后与backbone中间的低级特征以concat的方式融合,然后利用3*3卷积获得细化的特征,最后再进行上采样恢复到原始分辨率;在backbone部分,使用可分离卷积改进了Xception。
本质上,DeepLabV3+就是DeepLabV3加上一个decoder。
这篇关于1.deeplabv3+网络结构及原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





