本文主要是介绍Sora催化算力需求暴涨,星融元为泛在算力构建开放网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
龙年伊始,AI领域又出重磅新闻:OpenAI发布文生视频大模型Sora,生成式AI迎来新里程碑。
从技术层面来看,Sora的进化速度近乎不可思议。2023年6月发布的Gen-2只支持4秒视频生成并且掉帧明显得像幻灯片,11月,Meta发布的视频生成大模型Emu Video可以生成512*512、每秒16帧的视频,3个月后发布的Sora已经能够做到生成任意分辨率和长宽比的视频,还能够执行一系列图像和视频编辑任务,根据文本提示创建详细的视频、通过静态图像生成视频。
 Sora根据文字提示生成的视频截图
Sora根据文字提示生成的视频截图
AGI行业的快速发展需要大量模型训练和推理,推动算力需求持续高涨。在实际应用中,并不是所有的计算资源都能被充分利用,在计算、数据处理等过程中,大量算力被“闲置”,此时可以考虑泛在算力,从计算、存储和网络服务三个方面提高算力利用率。
泛在算力需要稳定的网络来连接各种计算资源,开放网络的高带宽、低时延、传输稳定性和可靠性等特性为泛在算力提供更多应用场景和可能性。国内企业想乘AI技术东风,推动数字化和智能化的发展,却不知道应该选择什么厂商来提供网络服务?
星融元致力于为泛在算力构建开放网络,业务覆盖云网络、高性能计算/人工智能、企业数据中心、园区接入等领域,同时支持分布式存储、网络可视等功能,在保障规模、带宽、时延及稳定性等性能的同时极大降低成本。
以Sora为例,由于Sora基于“Patch”而非整个视频进行训练,类似于大型语言模型(LLM)中的文本标记,把所有类型的视觉数据转换为统一的表示从而进行大规模的生成式训练,这一过程需要高效处理大量数据,Asterfusion星智AI网络解决方案轻松组建智算中心万卡网络:
- 在不影响数据传输性能的情况下,精简网络架构,极大降低用户网络建设成本;
- 将网络转发路径跳数降低至1跳,大大减少业务时延;
- 简化网络结构,降低运维以及故障排查难度。
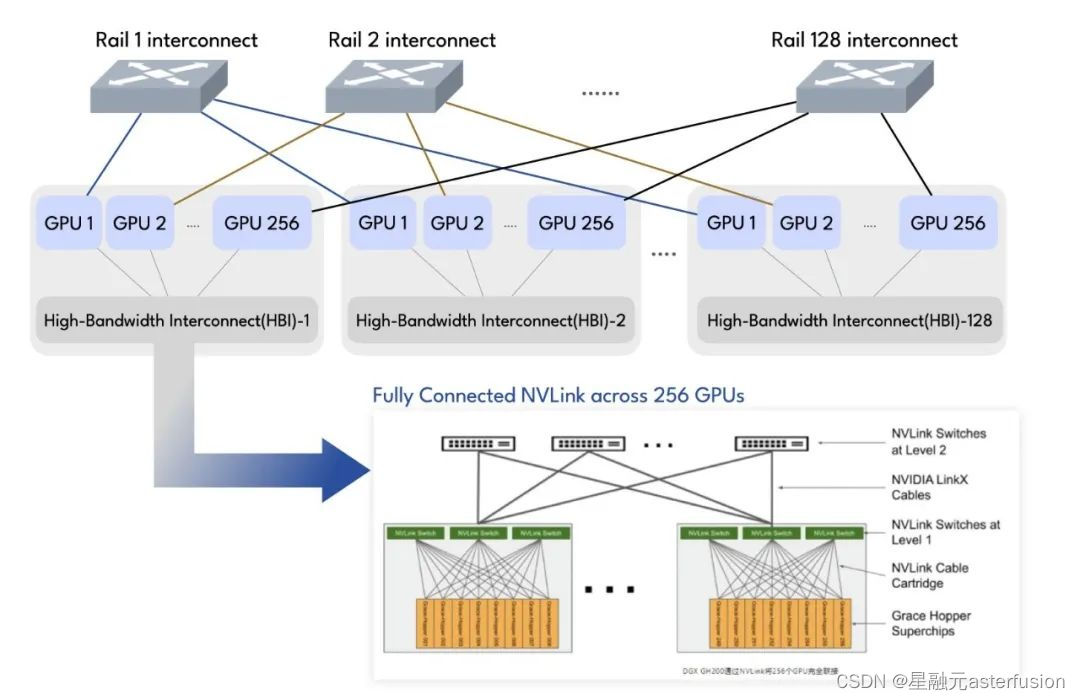
在网络性能方面,Asterfusion星智AI网络解决方案有以下优势:
- 提升了单机网络带宽
(1)增加网卡数量,初期业务量少可以考虑CPU和GPU共用,后期给CPU准备单独的1到2张网卡,给GPU准备4或8张网卡;
(2)提升单机网卡带宽,同时需要匹配主机PCle带宽和网络交换机带宽,星融元200G、400G、800G以太网交换机将配合网卡确保数据传输高带宽;

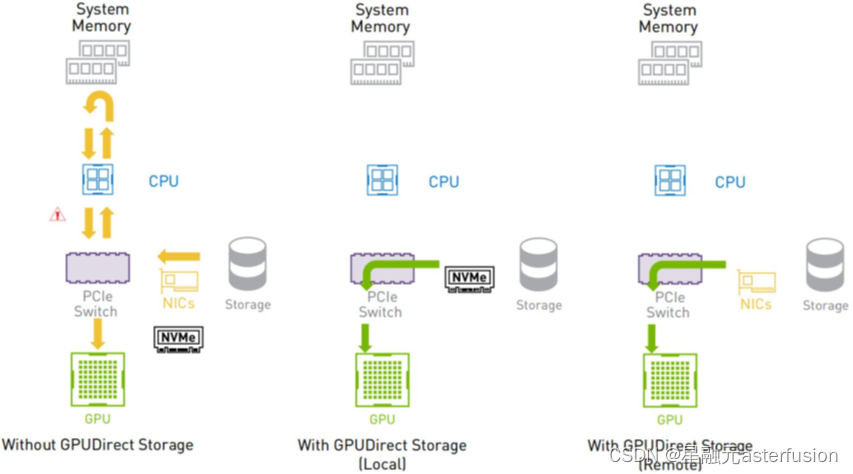
- 应用RDMA网络(RoCE)
(1)借助RDMA技术减少GPU通信过程中的数据复制次数,优化通信路径,降低通信时延;
(2)通过Easy RoCE一件下发复杂的RoCE相关配置(PFC、ECN等),帮助用户降低运维复杂度;
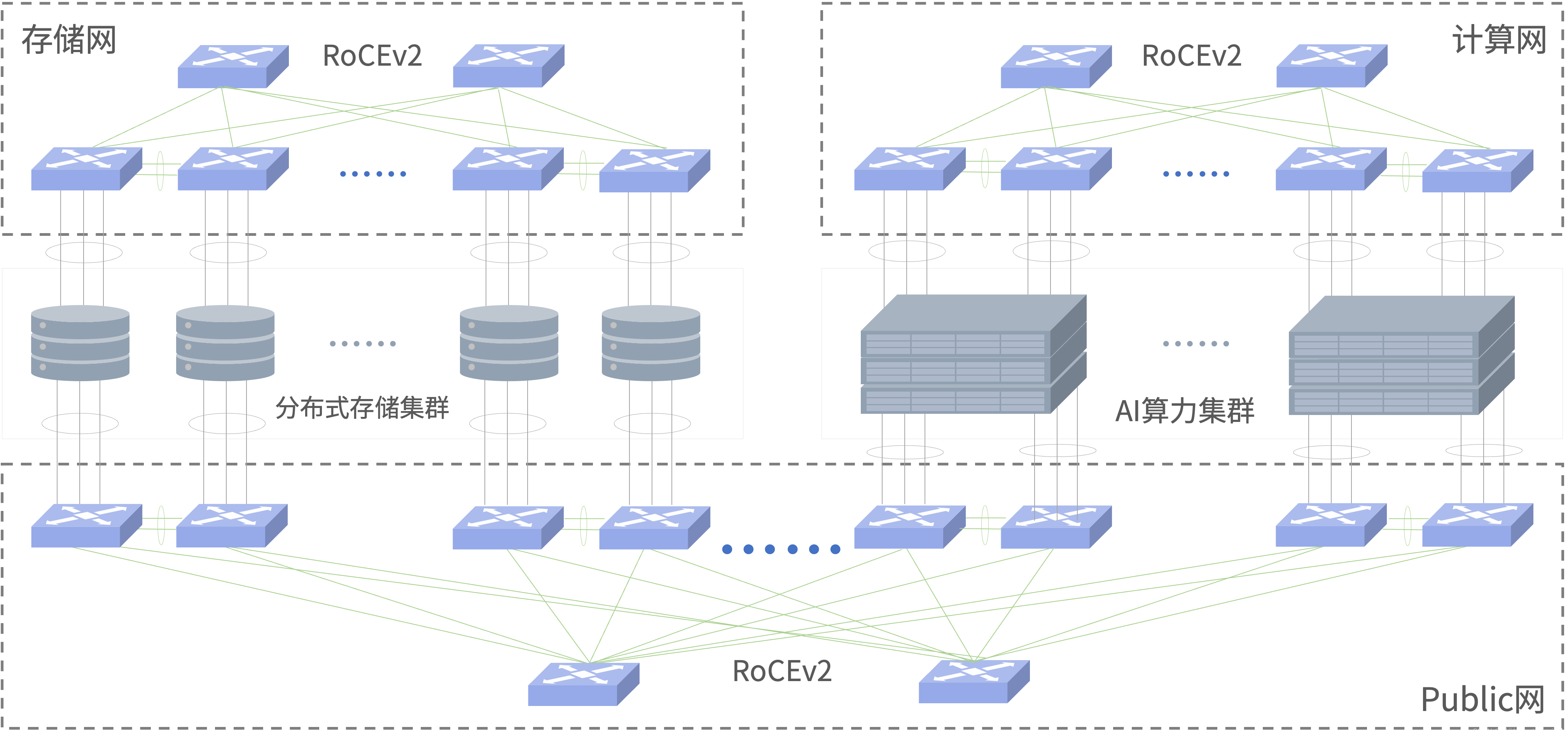
- 减少网络拥塞
(1)减少网络侧时延,提高GPU使用效率:超低时延降至400ns;
(2)通过DCB协议组减少网络拥塞:通过PFC、PFC WatchDog、ECN构建全以太网零丢包低时延网络。
(3)双网分流:CPU的流量与GPU流量彻底分离开,减少不同网络流量的占用和干扰。
作为开放网络领域的先行者,星融元持续为客户提供性能优越、成本优势明显的产品和方案,助力企业实现更高效的运营与发展。依托先进技术和丰富经验,星融元将为泛在算力的发展开辟更广阔的空间,为行业带来更多的机遇和可能性。
关注vx公号“星融元Asterfusion”,获取更多技术分享和最新产品动态。
这篇关于Sora催化算力需求暴涨,星融元为泛在算力构建开放网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







