本文主要是介绍CnOpenData中国工业企业基本信息数据增强版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CnOpenData中国工业企业基本信息数据增强版
目录)
- CnOpenData中国工业企业基本信息数据增强版
- 数据简介
- 字段展示
- 样本数据
- 数据更新频率
数据简介
拉动中国经济的三个产业中,工业企业在其中占有特殊的地位,是推动国内经济发展的重要产业。工业是最主要的物质生产部门,为居民生活、各行业的经济活动提供物质产品,这一重要作用是其他任何产业部门都无法替代的。工业企业为经济活动提供充足的物质基础,同时,工业也是研发投入最多、技术创新最活跃、辐射带动力最强的产业部门,那些成功跨越“中等收入陷阱”并进入发达经济体行列的国家和地区有一个普遍特征,就是在工业化发展的后期阶段依然保持了较高比重的制造业,这足以说明实现工业健康发展对一国的重要性。
根据数据公布显示:2019年,中国总计有129家企业进入世界500强行列,其中四分之一企业的主业是制造业。
另外,工业因其产业链长、带动性广、吸纳就业和技术扩散作用强等特点,对于带动落后地区经济发展的作用不可替代。
工业企业数据是学术界最常使用的经济数据之一,时间跨度为1998年至2013年,但在很多基础信息方面存在一定量的缺失,如企业注册时间、组织机构代码、纳税人识别号、经营期限及地址 等。CnOpenData通过匹配国家工商企业数据,获得了中国工业企业基本信息数据增强版。本数据有助于和其他数据信息进行进一步匹配,扩大学者的使用范围。
CnOpenData深知工业企业对经济的重要性,依据企业名称使用模糊匹配和精确匹配这两种方式,对工业企业的基本信息数据进行了汇总整理。
字段展示
| 中国工业企业基本信息表(模糊匹配) | 中国工业企业基本信息表(精确匹配) |
|---|---|
| 公司名称 | 公司名称 |
| 匹配公司名称 | 匹配公司名称 |
| 法定代表人 | 法定代表人 |
| 经营状态 | 经营状态 |
| 注册资本 | 注册资本 |
| 实缴资本 | 实缴资本 |
| 所属行业 | 所属行业 |
| 统一社会信用代码 | 统一社会信用代码 |
| 纳税人识别号 | 纳税人识别号 |
| 工商注册号 | 工商注册号 |
| 组织机构代码 | 组织机构代码 |
| 登记机关 | 登记机关 |
| 成立日期 | 成立日期 |
| 企业类型 | 企业类型 |
| 营业期限 | 营业期限 |
| 行政区划 | 行政区划 |
| 核准日期 | 核准日期 |
| 注册地址 | 注册地址 |
| 经营范围 | 经营范围 |
样本数据
- 中国工业企业基本信息表(模糊匹配)
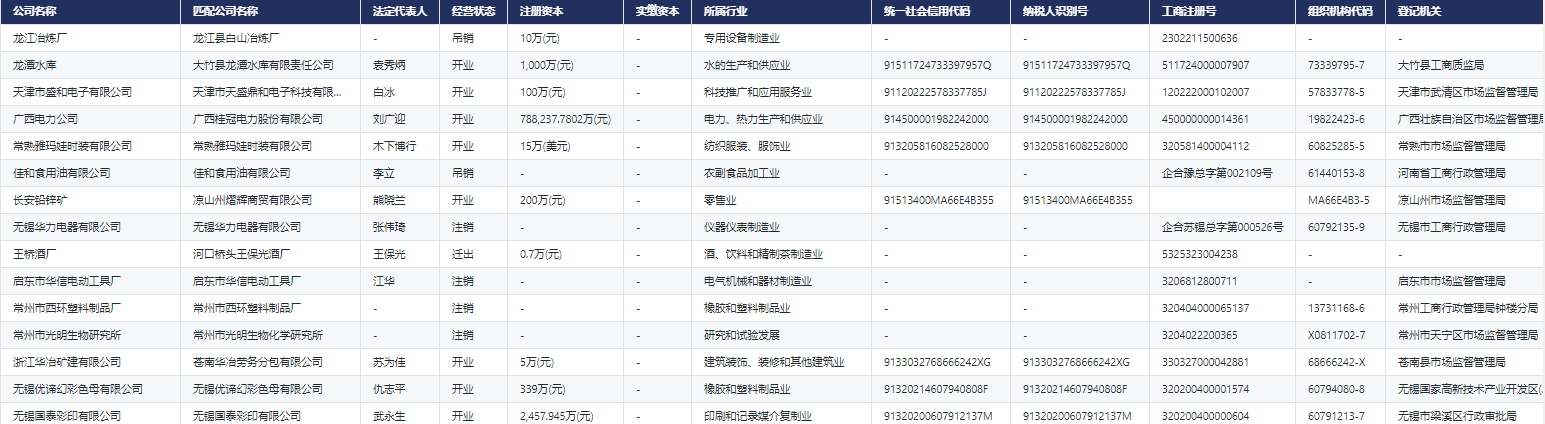
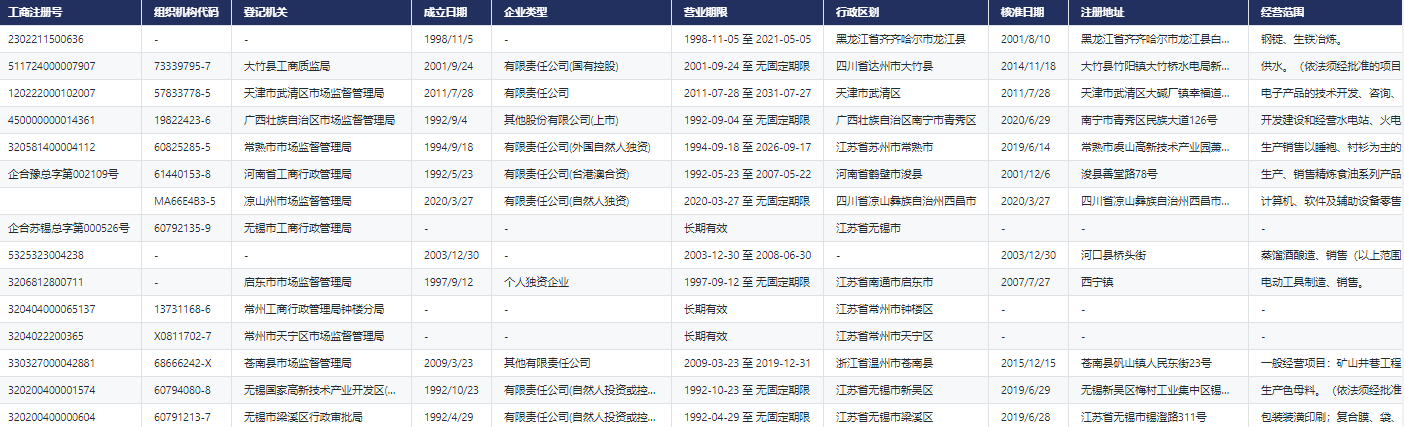
- 中国工业企业基本信息表(模糊匹配)
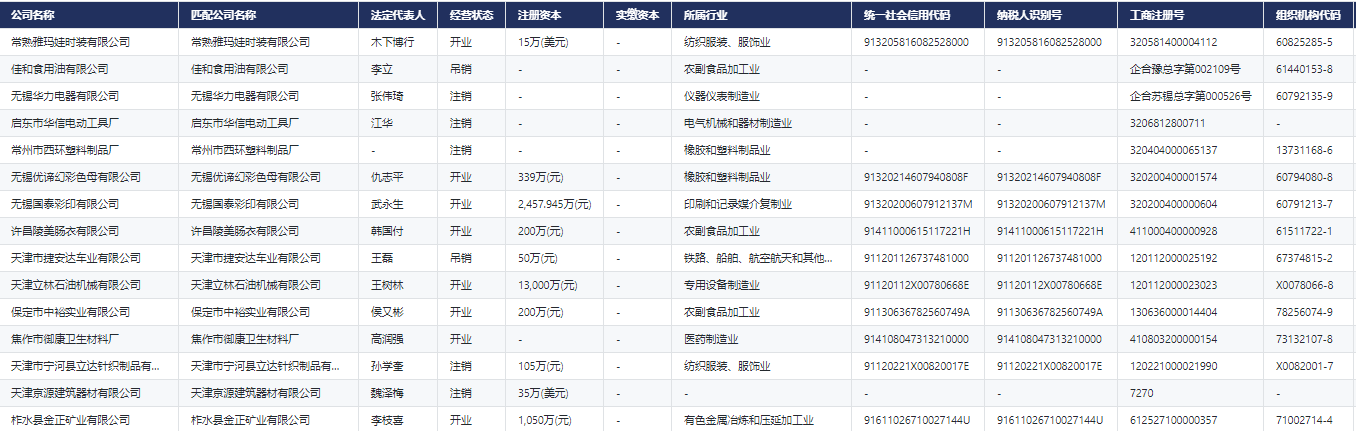

数据更新频率
年度更新
这篇关于CnOpenData中国工业企业基本信息数据增强版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








