本文主要是介绍蔡鸟的pyhon、深度学习、视觉学习笔记 不断更正,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- python
- 1、python3模块
- 在脚本中修改sys.path来引入一些不在搜索路径中的模块
- 使用模块的函数方法集合
- 2、python3 函数
- 参数传递
- 可更改(mutable)与不可更改(immutable)对象,python中一切都是对象
- python传不可变对象实例
- python传可变对象实例
- 关键字参数
- 不定长参数
- 3、python3数据结构
- 列表
- 将列表当作堆栈使用
- 将列表当作队列使用
- 列表推导式
- 嵌套列表解析
- 遍历技巧
- 集合
- 大佬们的文章
- 二、深度学习:
python
1、python3模块
- 模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引用,以使用模块中的函数等功能,这同样也是使用python标准库的方法。
- import:想使用Python源文件,只需要在另一个源文件中执行import语句,当解释器遇到import语句,如果模块在当前的搜索路径就会被导入(搜索路径是一个解释器会先进行搜索的所有目录的列表)
eg:
#!/usr/bin/python3#Filename:mark.pydef print_func(self)print("hello:",self)return
test.py引入mark.py模块(一个模块只会被导入一次):
#!/usr/bin/python3
#Filemile:test.py
#引入mark模块
import mark
#调用模块中的函数print_func
mark.print_func("markmark")
- 当我们使用import时,python解释器是怎样找到对应的文件的呢????答:PYthon解释器从组成搜索路径的一系列目录名中去寻找引入的模块。
搜索路径的查找方式:
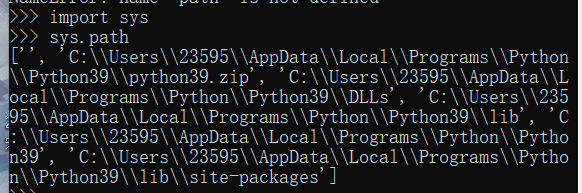
在脚本中修改sys.path来引入一些不在搜索路径中的模块
1、在解释器当前路径创建fibo.py的文件:
斐波那契(fibonacci)数列模块
- fibonacci:从第三项开始,每一项都等于前两项之和。0 1 1 2 3 5 8 13 21 34 55 ······
def fib(n): # 定义到 n 的斐波那契数列a, b = 0, 1while b < n:print(b, end=' ')a, b = b, a+bprint()def fib2(n): # 返回到 n 的斐波那契数列result = []a, b = 0, 1while b < n:result.append(b)a, b = b, a+breturn result
2、在python解释器里,导入fibo模块,使用fibo模块来访问fibo中的函数:
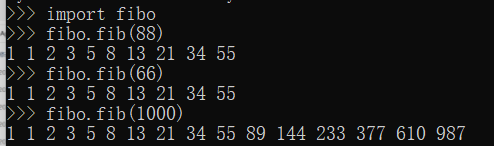
3、若想经常使用某个函数,可以给这个函数赋一个本地的名称:

使用模块的函数方法集合
1、from···import* :把一个模块的所有内容都导入到当前的空间,但是不该被过多的使用。
2、modename.itemname : 访问模块内的函数。
3、from···import itemname,itemname : 直接把模块内(函数、变量)的名称导入到当前操作的模块。
eg:

_name__属性:(当此属性值为main时说明是该模块自身在执行;且下划线是双下划线)一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序不执行,我们可以用_name_属性来世该程序块仅在该模块自身运行时执行。
_name_==main ; 就是说这个itemname仅在该模块自身运行的时候执行吗??别人引用这个模块的时候这个main函数不执行????
#!/usr/bin/python3
# Filename:usingname.py
#每一个模块都有一个__name__属性
if __name__==__main__:print('该模块本身在运行')
else:print('other mode')
#输出
$ python using_name.py
程序自身在运行
#输出
$ python
>>> import using_name
我来自另一模块dir()函数:内置的dir()函数可以找到模块内定义的所有名称。以一个字符串列表的形式返回。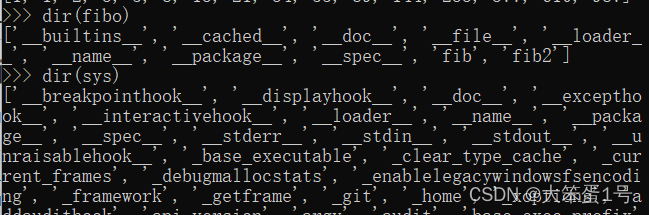
- 若没有给定参数,那么dir()函数就会罗列出当前定义的所有名称。(包括函数,变量,文件)

包:包是一种管理python命名空间的形式,采用“点模块名称”。比如一个模块的名称是A.B,那么他表示一个包A中的子模块B。
eg:
sound/ 顶层包
init.py 初始化 sound 包
formats/ 文件格式转换子包
init.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
…
effects/ 声音效果子包
init.py
echo.py
surround.py
reverse.py
…
filters/ filters 子包
init.py
equalizer.py
vocoder.py
karaoke.py
…
- 目录只有含一个叫_int_.py的文件才会被认作是一个包。
用包的方法:
1、每次只导入一个包里的特定模块:
注意:用这个语法,除了最后一项echo,前边的都必须是包,最后一项可以是包或者模块但是不可以是变量或函数的名字
import sound.efffcts.echo
#导入了子模块echo
以上就导致必须试用全名去访问:
sound.effects.echo.echofilter(input,output,delay=0.7,atten=4)
2、导入子模块:
#导入子模块echo
from sound.effect import echo
以上不会像1、访问时那么多字(少了一点前缀):
echo.echofilter((input,output,delay=0.7,atten=4)
3、直接导入函数或变量:
from sound.effects.echo import echofilter
以上用法相较来说又少了一些前缀
echofilter((input,output,delay=0.7,atten=4)
2、python3 函数
- 函数的定义:函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。函数能提高应用的模块性,和代码的重复利用率。
- 定义一个函数:
- 函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数第一行语句可以选择性地使用文字档字符串—用于存放函数说明。
- 函数内容以冒号:起始,并且缩进
- return[表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的return相当于返回None。
代码示例:
def hello():print("hello world!")
def area(width,height):return width * height
def welcome(name):print("hello",name)
def printstr(str):print(str)return
def max(a,b):if a>b:return aelse:return b
w=5
h=8
welcome("mark")
welcome(888)
welcome("007")
print("width=",w,"height=",h,"area=",area(w,h))
printstr("mark mark mark hihi")
print(max(3,4))
输出结果:
hello mark
hello 888
hello 007
width= 5 height= 8 area= 40
mark mark mark hihi
4
参数传递
- 在python中,类型属于对象,变量是没有类型的。
# [1,2,3]是list类型对象
a=[1,2,3]
# mark是string类型变量
a="mark"
# a是没有类型,它仅仅是一个对象的引用(一个指针)可以指向list、string类型对象。
可更改(mutable)与不可更改(immutable)对象,python中一切都是对象
不可更改的对象:strings,tuples,numbers ,可更改的对象:list,dict
| 不可变类型 | 可变类型 |
|---|---|
| 变量赋值a=5之后在赋值a=10, 实际上是心成城一个int值对象10, 再让a指向它,而不是改变a的值。 | 变量赋值L=[1,2,3,4]后再赋值L[2]=5 则是将list L的第三个元素值更改,本身L没有动, 只是其内部的一部分值被修改了。 |
python的函数参数传递:
| 不可变类型 | 可变类型 |
|---|---|
| 类似c++的值传递,如整数、字符串、元组。 如fun(a),传递的只是a的值,没有影响a对象本身。 如果在fun(a)内部修改a的值,则是新生成一个a 的对象。 | 类似于C++的引用传递,如列表、字典。 如fun(L),则是将L真正的传递过去, 修改f后,un外部的L也会受到影响 |
python传不可变对象实例
a=2
# id()函数可以查看内存地址
print(id(a))
def immutable(a):print(id(a))a=10print(id(a))
immutable(a)
输出结果:在immutable函数中对象a的指向变了,一开始指向值为2,后来指向值为10
1769540315472
1769540315472
1769540315728
python传可变对象实例
可变对象在函数里修改了参数,那么原始参数也会改变。
list=[1,2,3]
def mutable(list1):
# append()在列表末尾追加元素list1.append([1,2,3])print("函数内修改后输出", list1)
mutable(list)
print("修改后函数外输出",list)
输出结果:
函数内修改后输出 [1, 2, 3, [1, 2, 3]]
修改后函数外输出 [1, 2, 3, [1, 2, 3]]
关键字参数
关键字参数在使用时不需要按照指定顺序,因为python解释器能够用参数名匹配参数值。
def keyparameter(name,age):print("我叫",name,",我",age,"岁了")return
keyparameter(age=18,name="mark")
输出结果:
我叫 mark ,我 18 岁了
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,声明时不会命名。
1、加了一个*号的参数会以元组的形式导入,存放所有未命名的变量参数
- 元组内的变量不可以删除或修改,但可以删除整个元组 del tuple ,也可以进行拼接等。
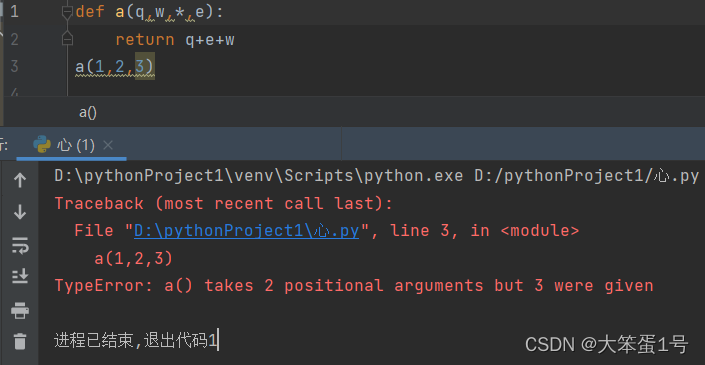
def printtuple(arg,*xtuple):print(arg)#输出元组print(xtuple)#迭代输出元组中的变量for x in xtuple:print(x)
printtuple(10,11,12,13)
输出结果:
10
(11, 12, 13)
11
12
13
声明函数时*可以单独出现,但是其后的参数必须用关键字输入。
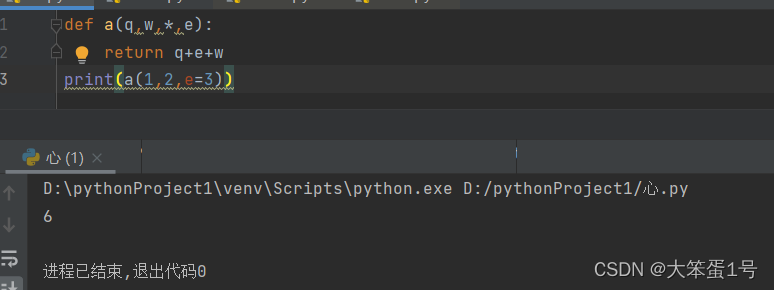
2、加了两个星号**的参数会以字典的形式导入。
def printtuple(arg,**xdict):print(arg)#输出字典print(xdict)
printtuple(10,name="mark",age=18)
ydict={'name':'bob','age':'22'}
print(ydict)
输出结果:
10
{‘name’: ‘mark’, ‘age’: 18}
{‘name’: ‘bob’, ‘age’: ‘22’}
3、python3数据结构
列表
- 列表可变,字符串、元组不可变。
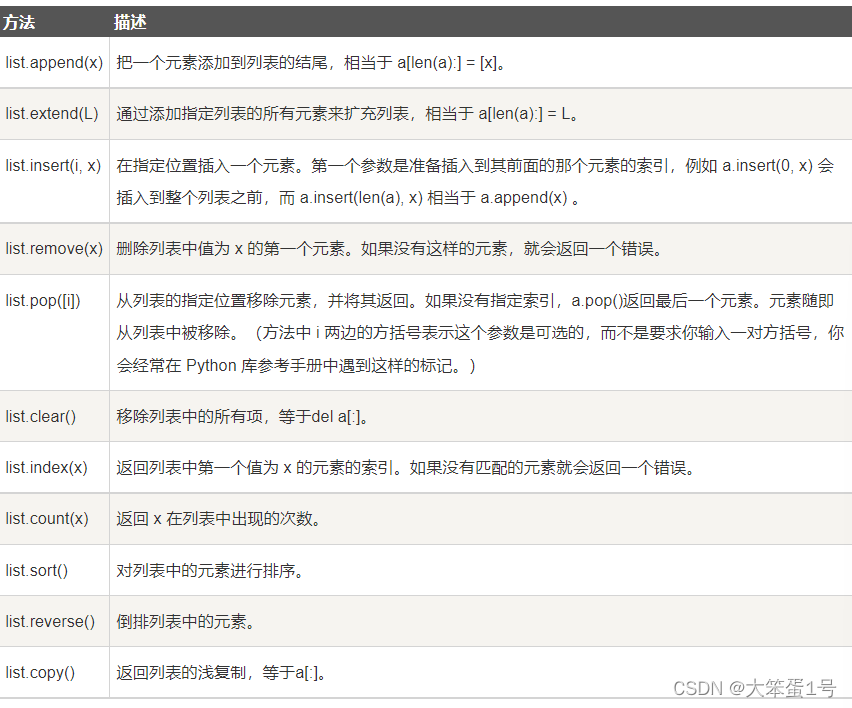
list1=[1,2,3,4]
list2=[5,6,7,8]
list1.append(4)
print(list1)
list1.extend(list2)
print(list1)
list1.insert(0,0)
print(list1)
list1.remove(4)
print(list1)
list1.pop(0)
print(list1)
list1.pop(0)
print(list1)
print(list1.index(6))
list2.insert(0,8)
print(list2)
print(list2.count(8))
list2.sort()
print(list2)
list2.reverse()
print(list2)
print(list2.copy)
list2.clear()
print(list2)
输出结果:
[1, 2, 3, 4, 4]
[1, 2, 3, 4, 4, 5, 6, 7, 8]
[0, 1, 2, 3, 4, 4, 5, 6, 7, 8]
[0, 1, 2, 3, 4, 5, 6, 7, 8]
[1, 2, 3, 4, 5, 6, 7, 8]
[2, 3, 4, 5, 6, 7, 8]
4
[8, 5, 6, 7, 8]
2
[5, 6, 7, 8, 8]
[8, 8, 7, 6, 5]
<built-in method copy of list object at 0x0000013DA32246C0>
[]
将列表当作堆栈使用
- 列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用append()方法可以把一个元素添加到栈顶。用不指定索引的pop()方法可以把一个元素从堆栈顶释放出来。
>>>stack.append(6)
>>>stack
[3, 4, 5, 6]
>>>stack.pop()
6
将列表当作队列使用
- collections是python内建的一个集合模块,里边封装了许多集合类,其中队列相关的集合只有一个:deque。
- deque是双边队列(double-ended queue),具有队列和栈的性质,在list的基础上增加了移动、旋转和增删等。
看这位作者写的相关语法
- deque是双边队列(double-ended queue),具有队列和栈的性质,在list的基础上增加了移动、旋转和增删等。
列表推导式
- 通常应用程序将一些操作应用于某个序列的每个元素,用其作为结果生成新的列表的元素,或者根据判定条件创建子序列。、
例子
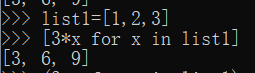
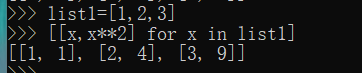
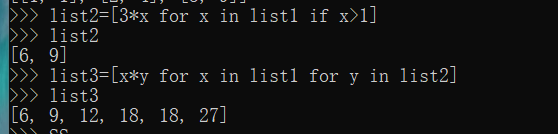
嵌套列表解析
- range()函数的用法:
range(start,stop[,step])
#start是起始位置,stop是结束位置,step是步长
range(4) -> 0,1,2,3
matrix=[[1,2,3],[4,5,6],[7,8,9],[10,11,12],]
matrix1=[[row[i] for row in matrix] for i in range(3)]
print(matrix1)
运行过程:
外层括号是外层循环,即for i in range(3),从0,1,2循环3次,即最后产生三行。
内层括号是内层循环,当外循环i=0时,内循环row=[1,2,3],row[0]=1,row=[4,5,6],row[0]=4,···;外循环i=1时,row=[1,2,3],row[1]=2,···;···。
运行结果为:[[1, 4, 7, 10], [2, 5, 8, 11], [3, 6, 9, 12]]
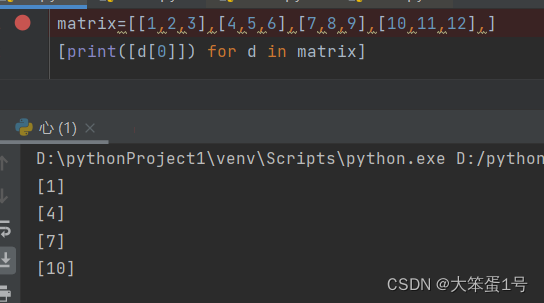

遍历技巧
字典中遍历时,关键字和对应的值可以使用items()方法同时解读出来。
knights={'mark is':'a boy','loving':'apple'}
for q,w in knights.items():print(q,w)
输出结果:
mark is a boy
loving apple
在序列中遍历时,索引位置和对应值可以使用enumerate()函数同时得到:
knights=['mark','is','a','boy','loving','apple']
for q,w in enumerate(knights):print(q,w)
输出结果:
0 mark
1 is
2 a
3 boy
4 loving
5 apple
同时遍历两个或者更多的序列,可以使用zip组合 (zip()···**.format())
gender=['boy','girl']
fruit=['apple','orange']
for q,w in zip(gender,fruit):print('mark is a {0},loving {1}'.format(q,w))
输出结果:
mark is a boy,loving apple
mark is a girl,loving orange
要反向遍历一个序列,首先指定这个序列,然后调用reversed()函数。
gender=['boy','girl']
for i in reversed(gender):print(i)
输出结果:
girl
boy
集合
集合是一个无序不重复的元素的集。基本功能包括关系测试和消除重复元素。
可以用({})创建集合。注意:如果要创建一个空集合,必须要用set()而不是{};后者创建一个空的字典。
basket={'12213','13123','1231321'}
a=set('123xdfwefw')
# set expected at most 1 argument
大佬们的文章
import as
import from
import os
import shutil
import
PIL详解
PIL各模块详解
class类入门
self解释
self.name=name
二、深度学习:
深度学习,不断更正:
这篇关于蔡鸟的pyhon、深度学习、视觉学习笔记 不断更正的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



