本文主要是介绍估值高达380亿美元!大数据独角兽Databricks官宣16亿美元新融资,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群
2021年大数据肌肉猿公众号奖励制度

作者 | 罗燕珊
策划|蔡芳芳
距离上一轮融资才7个月时间,Databricks的估值已经增加了100亿美元。
美国当地时间8月31日,由 Apache Spark 初始成员创立的大数据初创公司 Databricks 宣布获得 16 亿美元 H 轮融资,新一轮融资由摩根士丹利的 Counterpoint Global 领投,Counterpoint Global 还引入了其他新投资者,包括 Baillie Gifford、ClearBridge Investments 和加州大学的 UC Investments。此外,包括BlackRock(贝莱德)、Andreessen Horowitz、Tiger Global Management、T. Rowe Price Associates 和 Fidelity Investments 在内的现有投资者也参与了本轮融资。
本轮融资过后,Databricks的估值已经飙升至380亿美元。也就是说,距离上一轮10亿美元的G轮融资才7个月时间,其估值就已经增加了100亿美元。

Databricks联合创始人兼首席执行官 Ali Ghodsi 表示,这笔资金将主要用于加速Data Lakehouse(湖仓一体)的产品创新和市场开拓。
为了支持 lakehouse 技术的发展,Databricks 还宣布任命前 Salesforce 高管 Andy Kofoid 为全球运营总裁,相信在 Kofoid 的带领下,Databricks Lakehouse平台将可以积极进入新市场、支持和发展其合作伙伴生态系统以及构建广泛的行业解决方案目录。
此外,新闻稿还提到,受开源、上云和机器学习应用不断兴起的趋势所推动,Databricks还打算进一步投资人工智能方向的创新,保留所有主要公共云的选择和灵活性,并将 lakehouse 发展成传统数据仓库的替代品。
抢滩 lakehouse 市场
Ali Ghodsi 认为资本能帮助 Databricks 进一步获得市场领先地位。
自80年代以来,大公司已在数据仓库中存储了大量结构化数据。近些年,像Snowflake 和 Databricks 等公司则为非结构化数据提供了类似的解决方案,称为数据湖。
在 Ghodsi 看来,将结构化和非结构化数据结合到一个地方,让客户能够在不移动底层数据的情况下执行数据科学和商业智能工作,是大数据发展的一个关键变化。
“‘lakehouse’是一个新赛道,我们认为这个赛道中会有很多供应商,所以说这是一场地盘争夺战。我们希望快速构建并完成 lakehouse 赛道的布局。” 在接受媒体采访时,Ghodsi 强调,Databricks 正与资本充足的竞争对手抗衡,这些对手还不是一些小型初创公司,而是各种大型、成熟的供应商,包括 Snowflake、亚马逊、谷歌以及其他希望从 Databricks 所看到的赛道中分一杯羹的公司,他希望新融资带来的资金能够让 Databricks 更好地与对手们抗衡。

Databricks 于 2013 年在旧金山成立,是大型数据分析工具的最大供应商之一,其创始团队也是 Apache Spark 的创始成员。
除了业界熟知的 Spark,Databricks 还有不少产品,包括开发和维护 AI 生命周期管理平台 MLflow、数据分析工具 Koalas 和 Delta Lake。Delta Lake 为Apache Spark 和其他大数据引擎提供可伸缩的 ACID 事务,让用户可以基于 HDFS 和云存储构建可靠的数据湖。
2020 年 6 月,Databricks 还推出了用于实现高性能查询的 Delta Engine 原生执行引擎;同年 11 月,Databricks 推出了 Databricks SQL,它允许客户直接在数据湖上运行商业智能和分析报告。
目前,Databricks 已经与亚马逊、Google、微软以及阿里巴巴等全球领先的公共云服务提供商建立了合作关系,合计已为全球19个国家/地区的5000多个客户提供服务。
未透露上市时间
Ghodsi 在媒体采访中表示,新冠肺炎疫情加速了 Databricks 在三个关键领域的发展势头:云、开源和机器学习。最近,Databricks 与多家医疗保健组织和政府机构合作,通过分析大量数据、预测结果以改善其运营。“现在,这些公司渴望将他们的数据和数据管道流程更快地迁移到云,我们看到了这些原本采用传统本地供应商的传统企业的机会。”他补充道。
目前 Databricks 的年度经常性收入(ARR)为 6 亿美元,高于 2020 财年末录得的 4.25 亿美元,预计到 2022 年公司员工人数将从 2300 人增加到 3000 多人。
以新估值计算,Databricks 的价值是当前其 ARR 的 63 倍,所以 Databricks 并不便宜,但以它目前的增长速度来看,未来的收入也应该可以达到相应的规模。
Ghodsi 这次并未对媒体透露 Databricks 的上市时间安排,但 Ghodsi 在今年夏天接受 The Register 采访时曾表示,Databricks 的目标是今年“准备 IPO”。
那为什么 Databricks 还不上市呢?
或许是因为 Ghodsi 发现 Databricks 在创投市场中也可以获得无限的资本。因为太过于受欢迎,Databricks 在最新一轮融资中“不得不”多融1 亿美元,而该轮融资原本设定的募资额为15亿美元,这些钱也让 Databricks 能够对一些较小的公司展开并购,以填补产品路线图中的空白或不足。Ghodsi 亦曾在接受 VentureBeat 的采访时表示,未来融资资金将用于推动并购战略,重点是机器学习和数据初创公司,以及扩大与云公司的合作伙伴关系。
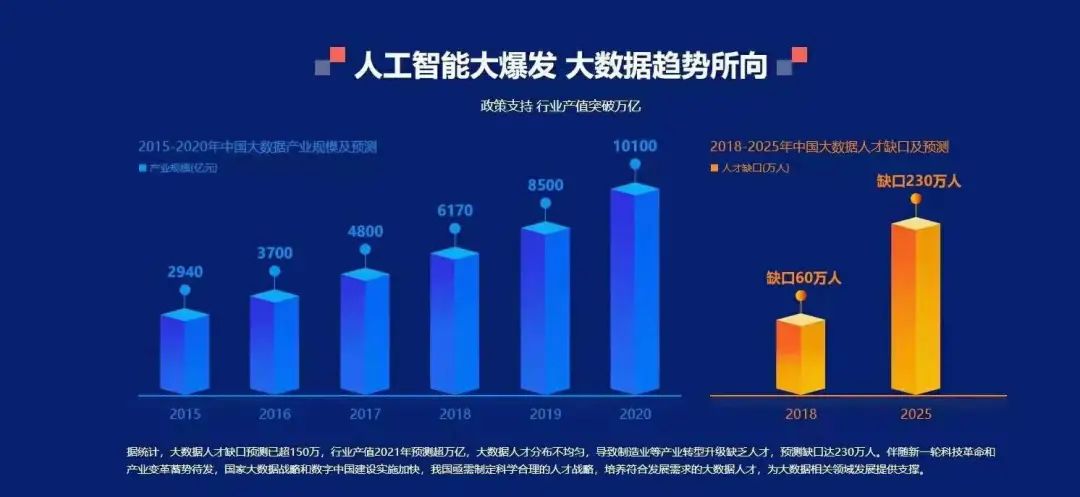
据统计,大数据人才缺口2025年将高达230万人!!!想搭上这一波风口的同学可以捉紧时间入局!
--end--
扫描下方二维码添加好友,备注【交流】
可私聊交流,也可进资源丰富学习群更文不易,点个“在看”支持一下????
这篇关于估值高达380亿美元!大数据独角兽Databricks官宣16亿美元新融资的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







