本文主要是介绍HN 千赞热贴|创业 4 年,那些狠狠打我脸的技术选型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hacker News 帖子
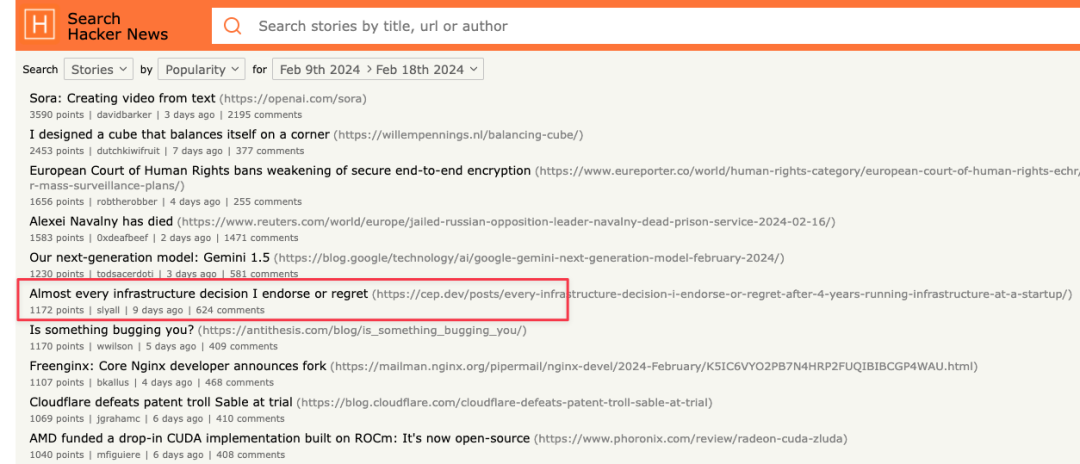
过年这段时间,Hacker News 上也涌现了不少好帖子,除了霸榜的 Sora 外,技术贴最靠前的就是这篇 (Almost) Every infrastructure decision I endorse or regret after 4 years running infrastructure at a startup。作者根据过去 4 年在一家创业公司里负责基础设施的经历,复盘了几乎每一个基础设施选型的得失。作者所在的公司叫 Cresta,其实是硅谷一家规模不小的公司了,还是由国人创立的,做客户联络中心 (Contact Center) 的解决方案。

AWS
选择 AWS 而不是谷歌云 ✅ 点赞
早期,我们同时使用 GCP 和 AWS。在那段时间里,我不知道我的谷歌云「客户经理」是谁,与此同时,我定期与我们的 AWS 客户经理开会。有一种感觉是谷歌依赖机器人和自动化,而亚马逊则专注于客户。这种支持在评估新的AWS 服务时对我们很有帮助。除了支持外,AWS 在稳定性方面做得非常好,并且尽量减少向后不兼容的 API 更改。
曾经有一段时间,Google Cloud 是 Kubernetes 集群的选择,特别是当 AWS 还没有决定是否要投入 EKS 时。然而现在,在 AWS 服务周围增加了许多额外的 Kubernetes 集成(如 external-dns、external-secrets 等),这个问题已经不再重要了。
EKS (AWS 容器托管服务 Elastic Kubernetes Service) ✅ 点赞
除非你很节俭(而且你认为自己的时间是免费的),否则没有理由自己运行控制平面,而不是使用 EKS。在 AWS 中使用 ECS 等替代方案的主要优势是与 AWS 服务的深度集成。幸运的是,Kubernetes 在许多方面已经赶上:例如,使用 external-dns 与 Route53 集成。
EKS managed addons (EKS 托管插件) ❌ 打脸
我们最初选择了 EKS 托管的插件,因为我认为这是使用 EKS 的「正确」方式。不幸的是,我们总是遇到需要自定义安装本身的情况。也许是 CPU 请求、镜像标签或某些配置映射。后来我们转而使用 Helm Chart 来替代插件,现在一切都运行得更好了,并且与我们现有的 GitOps 流水线相匹配。
RDS (AWS 关系数据库服务) ✅ 点赞
数据是您基础设施中最关键的部分。如果网络挂了,那就停机。如果丢失了数据,那公司就挂了。使用 RDS(或任何托管数据库)的额外成本是值得的。
Redis ElastiCache ✅ 点赞
Redis 作为缓存和通用产品表现非常出色。它速度快,API 简单且文档完善,实现经过了大量测试。与其他缓存选项(如 Memcached)不同,Redis 具有许多功能,使其不仅适用于缓存。它是一个「做快速数据处理」的绝佳瑞士军刀。我对云服务提供商中 Redis 的前景感到不确定,但我觉得由于 AWS 客户广泛使用它,AWS 将会继续很好地支持它。
ECR (AWS 容器镜像服务) ✅ 点赞
我们最初托管在 quay.io 上。那里的稳定性问题一团糟。自从迁移到 ECR 后,情况变得更加稳定。与 EKS 节点或开发服务器进行更深入的权限集成也是一个重大优势。
AWS VPN ✅ 点赞
CloudFlare 等公司也有 Zero Trust VPN 的替代方案。我相信这些产品运作良好,但 VPN 只是如此简单易懂(「简单就好」是我的座右铭)。我们使用 Okta 来管理我们的 VPN 访问,这是一次很棒的体验。
AWS 高级支持 ❌ 打脸
这太贵了:几乎(如果不是更多的话)比另一位工程师的成本还要高。我认为,如果我们对 AWS 知之甚少,那么这个费用就是值得的。
Control Tower Account Factory for Terraform ✅ 点赞
在集成 AFT 之前,使用控制塔很痛苦,主要是因为很难自动化。自从我们将 AFT 整合到我们的技术栈中后,启动账户工作就很顺利。AFT 让另一件事变得更容易,那就是为我们的账户标准化标签。例如,我们的生产账户有一个标签,然后我们可以用它来做 peering 决策。对于我们来说,标签比组织更有效,因为「哪些属性描述这个账户」并不总是一个树形结构。
流程
通过 Slack 机器人自动化复盘流程 ✅ 点赞
每个人都很忙。提醒别人填写复盘报告可能让你感觉自己是「坏人」。让机器扮演坏人的角色效果很好。它通过促使人们遵循 SEV 和复盘程序来简化流程。
开始时不必太复杂。只需基本的「已经一个小时没有消息了,有人更新一下」或者「已经一天没有日历邀请了,有人安排一下事后总结会议」,就可以走得更远。
使用 PagerDuty 的故障模版 ✅ 点赞
为什么要重复造轮子呢?PagerDuty 发布了一份关于事故期间该做什么的模板。我们稍作定制,这就是 Notion 灵活性派上用场的地方,但它确实是一个很好的起点。
定期回顾 PagerDuty 上的工单 ✅ 点赞
公司的警报情况如下:
- 根本没有任何警报。我们需要警报。
- 我们有警报。有太多的警报,所以我们忽略它们。
- 我们已经对这些警报进行了优先级排序。现在只有关键的那些才会叫醒我。
- 我们忽略非关键的警报。
我们设置了两个层次的告警系统:关键和非关键。关键告警会立刻通知到人。非关键告警将通过值班异步(电子邮件)通知值班人员。问题是,非关键告警经常被忽视。为解决这个问题,我们定期(通常每 2 周一次)举行 PagerDuty 审查会议,在会上审核所有的告警情况。对于重要告警,我们讨论是否应该保持其重要性不变。然后,针对非重要性告警(通常每次选取几个),讨论如何清除它们(通常调整阈值或创建一些自动化)。
开支追踪月会 ✅ 点赞 早些时候,我设立了一个每月会议,审查我们所有的 SaaS 成本(AWS、DataDog 等)。以前,这只是从财务角度进行审查的事情,但他们很难回答关于「这个成本数字是否正确」的一般性问题。在这些会议上,通常有财务和工程人员参加,我们会检查我们收到的每份与软件相关的账单,并对「这个成本是否合理」进行直觉检验。我们深入研究高额账单中的各项数字,并尝试将其分解。 例如,在处理 AWS 时,我们按标签对项目进行分组,并按帐户进行区分。这两个维度结合一般服务名称(EC2、RDS 等)让我们大致了解主要成本驱动因素所在。利用此数据做出的一些操作包括更深入地研究 spot 实例使用情况或哪些帐户占了网络费用的大头。但不要仅限于AWS:应该介入公司所有主要支出点所涉及的全部重要开支领域。
在 DataDog 或者 PagerDuty 里管理复盘报告 ❌ 打脸 每个人都应该进行复盘报告。DataDog 和 PagerDuty 都有集成来管理编写复盘报告,我们尝试过每一种。不幸的是,它们都很难定制化复盘报告流程。考虑到像 Notion 这样功能强大的 wiki 工具,我认为最好使用类似的工具来管理复盘报告。
没有尽可能多地使用函数即服务 (FaaS) ❌ 打脸
没有很好的用于运行 GPU 工作负载的 FaaS 选项,这就是为什么我们永远无法完全采用 FaaS。然而,许多 CPU 工作负载可以使用 FaaS(lambda 等)。人们提出的最大反对意见是成本问题。他们会说类似于「这种 EC2 实例类型在满负荷下运行 24/7 比 Lambda 便宜得多」。这是事实,但也是一个错误的比较。没有人会以 100% 的 CPU 利用率来运行服务。通常都有一些规模器在那里说「永远不要达到100%。当达到70%时再扩展」。何时缩减规模总是不明确,而更像一种启发式方法,「如果我们已经保持在 10% 上 10 分钟了,请缩减规模」。此外,人们总会假设 spot 实例是一直有的。
Lambda 的另一个隐藏优势是非常容易以高精度跟踪成本。在 Kubernetes 中部署服务时,成本可能被其他每个节点对象或同一节点上运行的其他服务所掩盖。
GitOps ✅ 点赞
GitOps 目前在很大程度上扩展得相当好,我们将其用于基础设施的许多部分:服务、Terraform 和配置等。主要缺点是流水线导向的工作流提供了一个清晰的图像:「这里是代表您提交的框,这些箭头从该框指向管道末端」。使用GitOps 后,我们不得不投资于工具来帮助人们回答类似「我提交了代码:为什么还没有部署」的问题。 即便如此,GitOps 的灵活性已经取得了巨大成功,我强烈推荐您公司采用它。
优先解决内部效率而不是外部需求 ✅ 点赞
很可能,您的公司并不是在销售基础设施本身,而是另一种产品。这给团队带来了压力,要求交付功能而不是扩展自己的工作量。但就像飞机告诉你先戴上自己的氧气面罩一样,您需要确保您的团队高效运转。除了极少数例外情况外,我从未后悔优先考虑花时间编写一些自动化或文档。
多个应用共享一个数据库 ❌ 打脸
像大多数技术债务一样,我们并没有做出这个决定,只是没有不做出这个决定。最终,有人希望产品加上一个新功能,并创建了一个新表。这感觉很好,因为现在两个表之间有外键。但由于所有东西都属于某人,并且那个某人是表中的一行,你的整个技术栈的所有对象之间都有外键。
由于数据库被每个人使用,却没有任何人关心它。初创公司没有雇佣 DBA 的奢侈条件,而所有无主物件最终将归基础设施团队所有。
共享数据库的最大问题包括:
- CRUD 在数据库中累积,并不清楚是否可以删除。
- 当存在性能问题时,基础设施(缺乏深入产品知识)必须调试数据库并找出应该重定向到谁。
- 数据库用户可能会推送破坏性代码到数据库中。这些破坏性操作可能会通过 PagerDuty 警报基础设施团队(因为他们拥有该数据库)。让一个团队为另一个团队的问题而醒来感觉很糟糕。对于应用程序所拥有的数据库来说,在发生问题时应用程序团队是第一响应者。
尽管如此,我并不反对想要共享单一数据库的堆栈。只需意识到上述权衡,并确保您有管理它们的良好策略即可。
SaaS
没有尽早引入身份平台 ❌ 打脸
我一开始使用 Google Workspace,用它来创建员工群组以分配权限。但它并不够灵活。回想起来,我希望我们早点选择 Okta。它运行得非常好,几乎与所有东西集成,并解决了许多合规性/安全方面的问题。尽早采用身份解决方案,并只接受与之集成的 SaaS 供应商。
Notion ✅ 点赞
每家公司都需要一个放置文档的地方。Notion 一直是一个很好的选择,比我过去使用过的东西(维基、谷歌文档、Confluence 等)要容易得多。他们用于页面组织的数据库概念也让我能够创建相当复杂的页面组织结构。
Slack ✅ 点赞
感谢上帝,我不再需要使用 HipChat 了。Slack 作为默认沟通工具非常棒,但为了减少压力和噪音,我建议:
- 使用 Thread 来压缩沟通
- 告知人们可能不会迅速回复消息的期望
- 不鼓励私信,并鼓励使用公共频道
从 JIRA 迁移到 Linear ✅ 点赞
天壤之别。JIRA 如此臃肿,我担心在人工智能公司运行它会让它完全变得有意识。当我使用 Linear 时,我经常会想「我是否可以做X」,然后尝试了之后发现果然可以!
没有使用 Terraform Cloud ✅ 点赞
早些时候,我尝试将我们的 terraform 迁移到 Terraform Cloud。最大的缺点是我无法证明成本合理。后来我把我们迁移到了 Atlantis,并且效果还不错。在 Atlantis 表现不佳的地方,我们在 CI/CD 流水线中编写了一些自动化脚本来弥补它。
使用 GitHub Actions 来做 CI/CD ✅ ❓微微点赞
我们和大多数公司一样,在 GitHub 上托管我们的代码。最初使用 CircleCI,但现在已经转向 GitHub Actions 进行持续集成/持续部署。GitHub Actions 的主要缺点是对自托管工作流程的支持非常有限。我们正在使用 EKS 和 actions-runner-controller 来托管在 EKS 中的自托管运行程序,但集成通常存在错误(不过这些都可以解决)。希望 GitHub将来更加重视 Kubernetes 的自我托管功能。
DataDog ❌ 打脸
Datadog 是一个很棒的产品,但价格昂贵。不仅仅是昂贵,我担心他们的成本模型对 Kubernetes 集群和 AI 公司特别不利。当您可以快速启动和关闭多个节点,并使用 spot 实例时,Kubernetes 集群是最具成本效益的。Datadog 的定价模型基于您拥有的实例数量,这意味着即使我们一次最多只有 10 个实例运行,如果在那个小时内启动并关闭了 20 个实例,我们将支付 20 个实例的费用。同样地,AI 公司倾向于大量使用 GPU。虽然 CPU 节点可能同时运行数十种服务,在许多用例之间分摊每个节点 Datadog 成本,而 GPU 节点可能只有一个服务在使用它,导致每项服务 Datadog 成本更高。
PagerDuty ✅ 点赞
PagerDuty 是一个很棒的产品,价格也合理。我们从未后悔选择它。
软件
Schema migration 数据库变更 ✅ ❓微微点赞
Schema 变更很难,无论你如何做,主要是因为它就是相当可怕。数据很重要,一个糟糕的 Schema 变更可能会删除数据。在解决这个困难问题的所有可怕方法中,我对将整个 schema 存入 git 并使用工具生成 SQL 以将数据库与 schema 同步的想法非常满意。
用 Ubuntu 作为开发服务器 ✅ 点赞
最初我尝试让开发服务器与我们的 Kubernetes 节点运行在相同的基本操作系统上,认为这样会使开发环境更接近生产环境。回想起来,这种努力并不值得。我很高兴我们决定继续使用 Ubuntu 作为开发服务器的操作系统。它是一个受到良好支持的操作系统,并且拥有大部分我们需要的软件包。
AppSmith ✅ 点赞
我们经常需要为内部工程师自动化一些流程:重新启动/升级/诊断等。对于我们来说,制作 API 来解决这些问题很容易,但调试某人特定的CLI/os/依赖安装等有点烦人。能够为工程师制作一个简单的UI与我们的脚本进行交互非常有用。 我们自行托管 AppSmith。它运行得…足够好。当然有一些事情我们想要改变,但对于「免费」价格而言已经足够了。最初我探索了与 retool 更深入集成,但当时无法证明那个值得付钱。
Helm ✅ 点赞
Helm v2 声誉不佳(有充分理由),但 helm v3 已经运行得足够好。在部署 CRDs 和教育开发人员为何他们的 Helm Chart 未能正确部署方面仍存在问题。然而总体来说,helm 作为打包和部署版本化 Kubernetes 对象的方式还算不错,Go 模板语言难以调试,但功能强大。
Helm Charts in ECR (oci) ✅ 点赞
最初我们的 helm charts 存储在 S3 中,并通过插件下载。主要的缺点是需要安装自定义 helm 插件并手动管理生命周期。我们后来转而使用 OCI 存储的 helm charts,这种设置没有出现任何问题。
Bazel ❓ 不确定
公平地说,很多聪明人喜欢 Bazel,所以我相信选择它并不是一个坏主意。 在部署 Go 服务时,个人认为使用 Bazel 有点过头。如果你上一家公司用的是 bazel,并且你有点怀旧,那么 Bazel 是一个很好的选择。否则,我们就引入了一个构建系统,只有少数工程师能深入了解;而与 GitHub Actions 相比,在那里似乎每个人都知道如何动手。
没有尽早使用 telemetry ❌ 打脸
我们最初直接使用 DataDog 的 API 将指标发送到 DataDog。这使得很难将它们移除。
四年前,Open telemetry 并不那么成熟,但现在已经好多了。我认为 metrics telemetry 仍然有点不够成熟,但 tracing 非常出色。我建议任何公司从一开始就使用它。
使用 renovatebot 而不是 dependabot ✅ 点赞
我真诚地希望我们早点考虑「保持依赖项更新」。当你等待太久时,最终会得到非常陈旧的版本,升级过程漫长且不可避免地存在错误。Renovatebot 在灵活性方面表现良好,可以根据您的需求进行定制。最大的缺点是它非常复杂且难以设置和调试。我想这可能是所有糟糕选择中最好的一个。
Kubernetes ✅ 点赞
您需要一个托管长时间运行服务的东西。Kubernetes 是一个受欢迎的选择,对我们来说效果很好。Kubernetes 社区在将 AWS 服务(如负载均衡器、DNS 等)整合到 Kubernetes 生态系统中方面做得非常出色。
「任何具有许多使用方式的系统都存在许多错误使用的方式」 - Jack Lindamood
购买自己的 IP ✅ 点赞
如果您与外部合作伙伴合作,您经常需要为他们发布一个 IP 白名单。不幸的是,您可能会后来开发更多需要自己 IP的系统。购买自己的 IP 地址块是一个很好的方法,可以通过给外部合作伙伴提供更大的 CIDR 块来避免这种情况。
使用 Flux 做 K8s GitOps ✅ 点赞
在 Kubernetes 的早期 GitOps 选择中,需要在 ArgoCD 和 Flux 之间做出决定:我选择了 Flux(当时是 v1)。它运行得非常好。我们目前正在使用 Flux 2。唯一的缺点是我们不得不开发自己的工具来帮助人们理解其部署状态。 我听说 ArgoCD 很棒,所以如果你选择了它,我相信也不错。
使用 Karpenter 做节点管理 ✅ 点赞
如果您正在使用EKS(而不是完全在 Fargate上),您应该使用 Karpenter。100%毫无疑问。我们曾经使用过其他自动缩放器,包括默认的 Kubernetes 自动缩放器和 SpotInst。在所有这些中,Karpenter 一直是最可靠且成本效益最高的选择。
使用 SealedSecrets 管理 K8s 密钥 ❌ 打脸
我的最初想法是将秘密管理推进到类似 GitOps 的东西。使用 sealed-secrets 的两个主要缺点是:
- 对于基础设施知识较少的开发人员来说,创建/更新机密更加复杂
- 我们 失去了AWS围绕轮换机密进行的所有现有自动化功能
使用 ExternalDNS 管理 DNS ✅ 点赞
ExternalDNS 是一个很棒的产品。它同步我们的 Kubernetes -> Route53 DNS 记录,在过去的 4 年里几乎没有给我们带来任何问题。
使用 cert-manager 管理 SSL 证书 ✅ 点赞
非常直观易配置,一切运行良好没有问题。强烈推荐使用它来为您的 Kubernetes 创建 Let's Encrypt 证书。唯一的缺点是我们有时会遇到古老(SaaS 问题对吧?)技术栈里客户不信任 Let's Encrypt,您需要为他们获取付费证书。
使用 Bottlerocket for EKS ❌ 打脸
我们的 EKS 集群以前在 Bottlerocket 上运行。主要问题是我们经常遇到网络 CSI 问题,调试 bottlerocket 镜像比调试标准的 EKS AMI 要困难得多。使用 EKS 优化的 AMI 来作为我们节点没有出现任何问题,当出现奇怪的网络问题时,我们仍然有一个后门来调试节点本身。 使用 Terraform 而不是 CloudFormation ✅ 点赞
使用基础设施即代码对于任何公司来说都是必不可少的。在 AWS 中,两个主要选择是 CloudFormation 和Terraform。我已经使用过两者,并且没有后悔选择 Terraform。它很容易扩展到其他 SaaS 提供商(比如Pagerduty),语法比 CloudFormation 更容易阅读,并且对我们来说既不是障碍也不会减速。
没有使用更多代码化方案(Pulumi, CDK 等) ✅ 点赞
虽然 Terraform 和 CloudFormation 是描述基础架构的数据文件(HCL和YAML/JSON),而像 Pulumi 或 CDK 这样的解决方案允许您编写执行相同功能的代码。代码当然很强大,但我发现 Terraform 的 HCL 具有一定限制性质对于减少复杂性是有益处的。并不是说无法编写复杂的 Terraform:只是在进行时更容易明显。
其中一些解决方案,比如 Pulumi,在很多年前就被发明出来了,而当时 Terraform 缺乏今天拥有的许多功能。新版本的 Terraform 已经集成了许多我们可以使用以减少复杂性的功能。我们反而使用一个中间地带为我们想要抽象化处理掉部分内容生成基本框架结构化 Terraform 代码。
没有使用 Network Mesh (istio, linkerd 等) ✅ 点赞
Network Mesh 非常酷,许多聪明人倾向于支持它们,所以我相信它们是好主意。不幸的是,我认为公司低估了事情的复杂性。我的一般基础设施建议是「少即是多」。
Nginx 作为 EKS 网关的负载均衡 ✅ 点赞
Nginx 老牌、稳定且经过实战检验。
Homebrew 来统一管理公司的脚本 ✅ 点赞
您的公司可能需要一种分发脚本和二进制文件供工程师使用的方法。Homebrew 已经足够好地为 Linux 和 Mac 用户提供了分发脚本和二进制文件的方式。
使用 Go 实现服务 ✅ 点赞
Go 对新工程师来说很容易上手,总体而言是一个很好的选择。对于大多数受网络 IO 限制的非 GPU 服务来说,Go 应该是您默认的语言选择。
部分观点肯定会引发争议,真理越辩越明,作者根据自己的实践分享了那么多,也确实引发了大家热烈的讨论。也欢迎大家在评论区留言。
💡 更多资讯,请关注 Bytebase 公号:Bytebase
这篇关于HN 千赞热贴|创业 4 年,那些狠狠打我脸的技术选型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





