本文主要是介绍【图神经网络】使用DGL框架实现简单图分类任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用DGL框架实现简单图分类任务
- 简单图分类任务
- 实现过程
- 打包一个图的小批量
- 定义图分类器
- 图卷积
- 读出和分类
- 准备和训练
- 核心代码
- 参考资料
图分类(预测图的标签)是图结构数据里一类重要的问题。它的应用广泛,可见于生物信息学、化学信息学、社交网络分析、城市计算以及网络安全。随着近来学界对于图神经网络的热情持续高涨,出现了一批用图神经网络做图分类的工作。比如 训练图神经网络来预测蛋白质结构的性质,根据社交网络结构来预测用户的所属社区等(Ying et al., 2018, Cangea et al., 2018, Knyazev et al., 2018, Bianchi et al., 2019, Liao et al., 2019, Gao et al., 2019)。
本文使用DGL框架实现简单的图分类任务,任务目标有两个:
- 如何使用DGL批量化处理大小各异的图数据
- 训练图神经网络完成一个简单的图分类任务
简单图分类任务
这里设计了一个简单的图分类任务。在DGL里已经实现了一个迷你图分类数据集(MiniGCDataset)。它由以下8类图结构数据组成。每一类图包含同样数量的随机样本。任务目标是训练图神经网络模型对这些样本进行分类。

实现过程
以下是使用 MiniGCDataset 的示例代码。
首先,创建了一个拥有 100 个样本的数据集。数据集中每张图随机有 16 到 32 个节点。DGL 中所有的数据集类都符合 Sequence 的抽象结构——既可以使用 dataset[i] 来访问第 i 个样本。这里每个样本包含图结构以及它对应的标签。
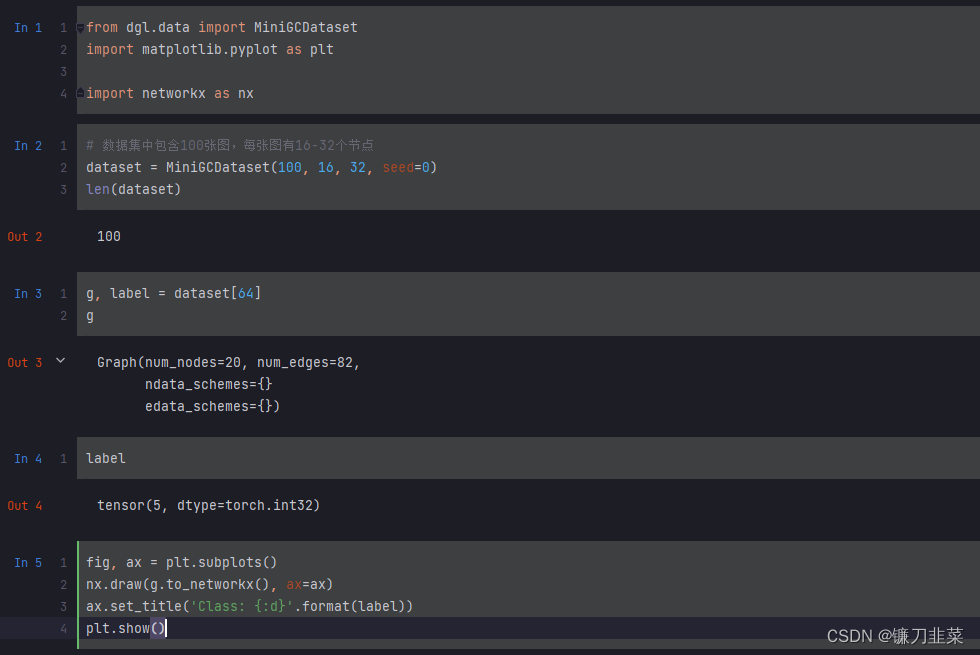
运行以上代码,可以画出数据集中第64个样本的图结果及其对应的标签:

打包一个图的小批量
为了更高效地训练神经网络,一个常见的做法是将多个样本打包成小批量(mini-batch)。打包尺寸相同的张量样本非常简单。比如说打包两个尺寸为 2828 的图片会得到一个 22828 的张量。相较之下,打包图面临两个挑战:
(1)图的边比较稀疏
(2)图的大小、形状各不相同
DGL 提供了名为 dgl.batch 的接口来实现打包一个图批量的功能。其核心思路非常简单**。将 n 张小图打包在一起的操作可以看成是生成一张含 n 个不相连小图的大图**。下图的可视化从直觉上解释了 dgl.batch 的功能。
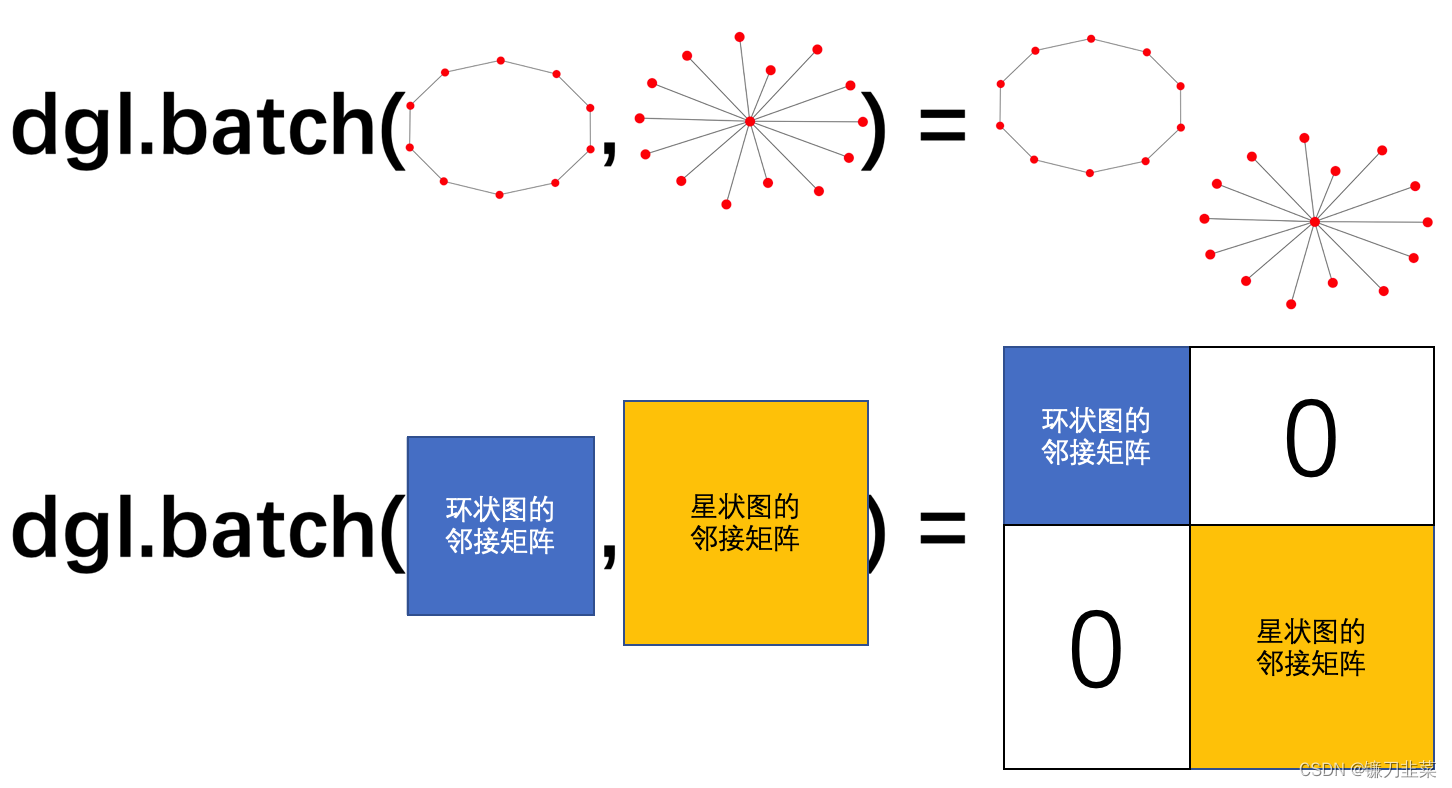
可以看到通过 dgl.batch 操作,生成了一张大图,其中包含了一个环状和一个星状的连通分量。其邻接矩阵表示则对应为在对角线上把两张小图的邻接矩阵拼接在一起(其余部分都为 0)。
以下是使用 dgl.batch 的一个实际例子。这里,定义了一个 collate 函数来将 MiniGCDataset 里多个样本打包成一个小批量。
import dgldef collate(samples):# 输入“samples”是一个列表# 每个元素都是一个二元组(图,标签)graphs, labels = map(list, zip(*samples))batched_graph = dgl.batch(graphs)return batched_graph, torch.tensor(labels)
正如打包 N 个张量得到的还是张量,dgl.batch 返回的也是一张图。这样的设计有两点好处。首先,任何用于操作一张小图的代码可以被直接使用在一个图批量上。其次,由于 DGL 能够并行处理图中节点和边上的计算,因此同一批量内的图样本都可以被并行计算。
定义图分类器
这里使用的图分类器和应用在图像或者语音上的分类器类似——先通过多层神经网络计算每个样本的表示(representation),再通过表示计算出每个类别的概率,最后通过向后传播计算梯度。一个常见的图分类器由以下几个步骤构成:
- 通过图卷积(Graph Convolution)层获得图中每个节点的表示。
- 使用「读出」操作(Readout)获得每张图的表示。
- 使用 Softmax 计算每个类别的概率,使用向后传播更新参数。
下图展示了整个流程:
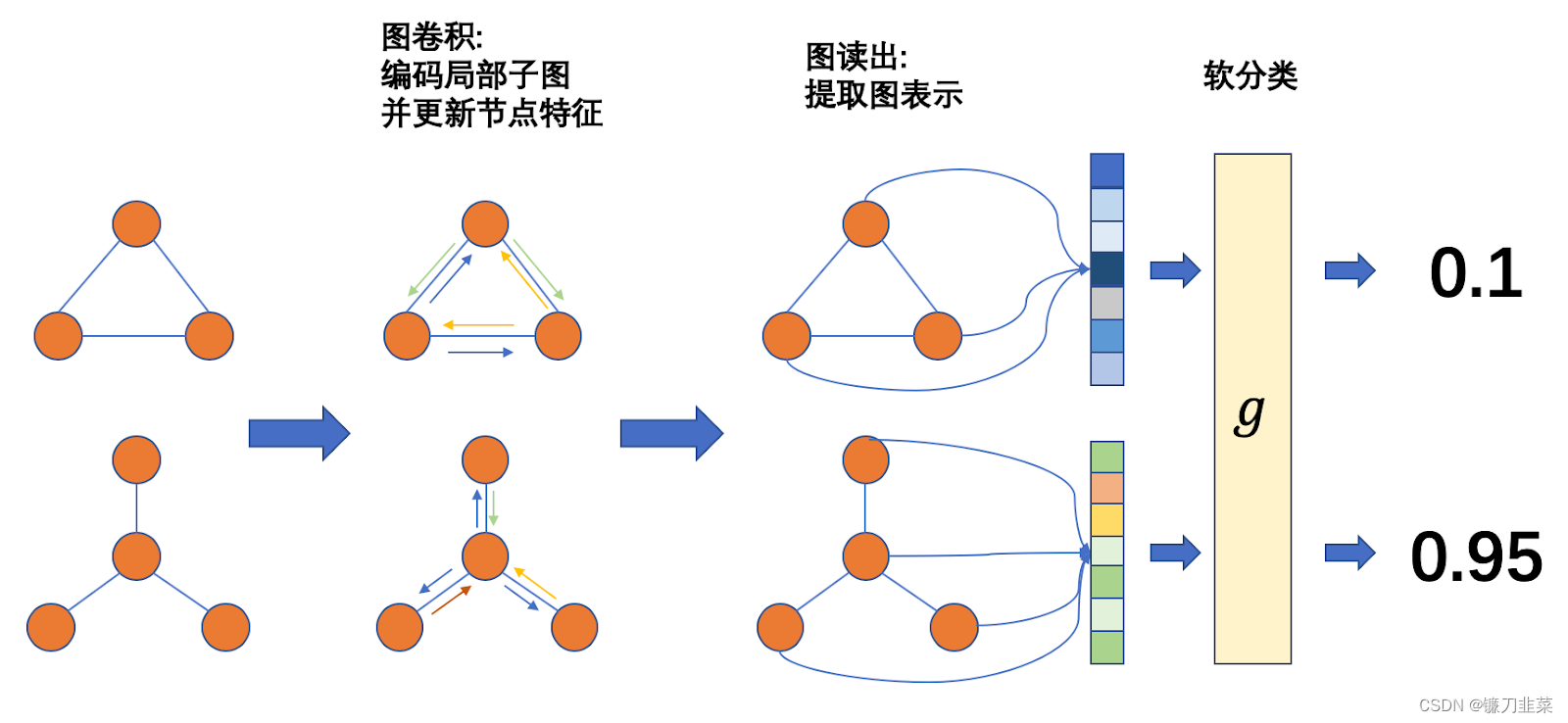 之后我们将分步讲解每一个步骤。
之后我们将分步讲解每一个步骤。
图卷积
我们的图卷积操作基本类似图卷积网络 GCN(具体可以参见我们的关于 GCN 的教程)。图卷积模型可以用以下公式表示:
h v l + 1 = R e L U ( b ( l ) + ∑ u ∈ N ( v ) h u ( l ) W ( l ) ) h_v^{l+1}=ReLU(b^{(l)}+\sum_{u\in N(v)}h_{u}^{(l)}W^{(l)}) hvl+1=ReLU(b(l)+u∈N(v)∑hu(l)W(l))
在这个例子中,对这个公式进行了微调:
h v l + 1 = R e L U ( b ( l ) + 1 ∣ N ( v ) ∣ ∑ u ∈ N ( v ) h u ( l ) W ( l ) ) h_v^{l+1}=ReLU(b^{(l)}+\frac{1}{|N(v)|} \sum_{u\in N(v)}h_{u}^{(l)}W^{(l)}) hvl+1=ReLU(b(l)+∣N(v)∣1u∈N(v)∑hu(l)W(l))
我们将求和替换成求平均可用来平衡度数不同的节点,在实验中这也带来了模型表现的提升。
此外,在构建数据集时,给每个图里所有的节点都加上了和自己的边(自环)。这保证节点在收集邻居节点表示进行更新时也能考虑到自己原有的表示。以下是定义图卷积模型的代码。这里使用 PyTorch 作为 DGL 的后端引擎(DGL 也支持 MXNet 作为后端)。
首先,使用 DGL 的内置函数定义消息传递:
import dgl.function as fn
import torch
import torch.nn as nn# 将节点表示h作为信息发出
msg = fn.copy_src(src='h',out='m')
其次,定义消息累和函数。这里我们对收到的消息进行平均。
def reduce(nodes):"""对所有邻接点节点特征求平均并覆盖原本的节点特征"""accum = torch.mean(nodes.mailbox['m'],1)return {'h':accum}
之后,对收到的消息应用线性变换和激活函数。
class NodeApplyModule(nn.Module):"""将节点特征hv更新为ReLU(Whv+b)"""def __init__(self, in_feats, out_feats, activation):super(NodeApplyModule, self).__init__()self.linear = nn.Linear(in_feats, out_feats)self.activation = activationdef forward(self, node):h = self.linear(node.data['h'])h = self.activation(h)return {'h': h}
最后,把所有的小模块串联起来成为 GCNLayer。
class GCNLayer(nn.Module):def __init__(self, in_feats, out_feats, activation):super(GCNLayer, self).__init__()self.apply_mod = NodeApplyModule(in_feats, out_feats, activation)def forward(self, g, feature):# 使用 h 初始化节点特征g.ndata['h'] = feature# 使用 update_all 接口和自定义的消息传递及累和函数更新节点表示g.update_all(msg, reduce)g.apply_nodes(func=self.apply_mod)return g.ndata.pop('h')
读出和分类
读出(Readout)操作的输入是图中所有节点的表示,输出则是整张图的表示。在 Google 的 Neural Message Passing for Quantum Chemistry(Gilmer et al. 2017) 论文中总结过许多不同种类的读出函数。在这个示例里,我们对图中所有节点表示取平均以作为图的表示:
h g = 1 ∣ V ∣ ∑ v ∈ V h v h_g=\frac{1}{|V|}\sum_{v\in V}h_v hg=∣V∣1v∈V∑hv
DGL 提供了许多读出函数接口,以上公式可以很方便地用 dgl.mean(g) 完成。最后将图的表示输入分类器。分类器对图表示先做了一个线性变换,然后得到每一类在 softmax 之前的 logits。具体代码如下:
import torch.nn.functional as Fclass Classifier(nn.Module):def __init__(self, in_dim, hidden_dim, n_classes):super(Classifier, self).__init__()# 两层图卷积层self.layers = nn.ModuleList([GCNLayer(in_dim, hidden_dim, F.relu),GCNLayer(hidden_dim, hidden_dim, F.relu)])# 分类层self.classify = nn.Linear(hidden_dim, n_classes)def forward(self, g):# 使用节点度数作为初始节点表示h = g.in_degrees().view(-1, 1).float()# 图卷积层for conv in self.layers:h = conv(g, h)g.ndata['h'] = h# 读出函数graph_repr = dgl.mean_nodes(g, 'h')# 分类层return self.classify(graph_repr)
准备和训练
阅读到这边的读者可以长舒一口气了。因为之后的训练过程和其他经典的图像,语音分类问题基本一致。首先创建了一个包含 400 张节点数量为 16~32的合成数据集。其中 320 张图作为训练数据集,80 张图作为测试集。
import torch.optim as optim
from torch.utils.data import DataLoader# 创建一个训练数据集和测试数据集
trainset = MiniGCDataset(320, 16, 32)
testset = MiniGCDataset(80, 16, 32)# 使用PyTorch的DataLoader和之前定义的collate函数
data_loader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate)
其次,创建一个刚刚定义的图神经网络模型对象。
# 其次创建一个图神经网络模型对象
model = Classifier(1, 256, trainset.num_classes)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
训练过程则是经典的反向传播和梯度下降。
# 训练过程是经典的反向传播和梯度下降
epoch_losses = []
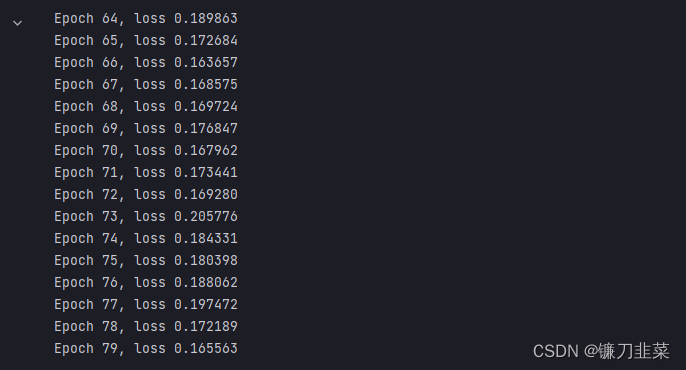
for epoch in range(80):epoch_loss = 0for iter, (bg, label) in enumerate(data_loader):prediction = model(bg)label = torch.tensor(label, dtype=torch.long)loss = loss_func(prediction, label)optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss += loss.detach().item()epoch_loss /= (iter + 1)print('Epoch {}, loss {:4f}'.format(epoch, epoch_loss))epoch_losses.append(epoch_loss)
运行结果:
下图是以上模型训练的学习曲线:
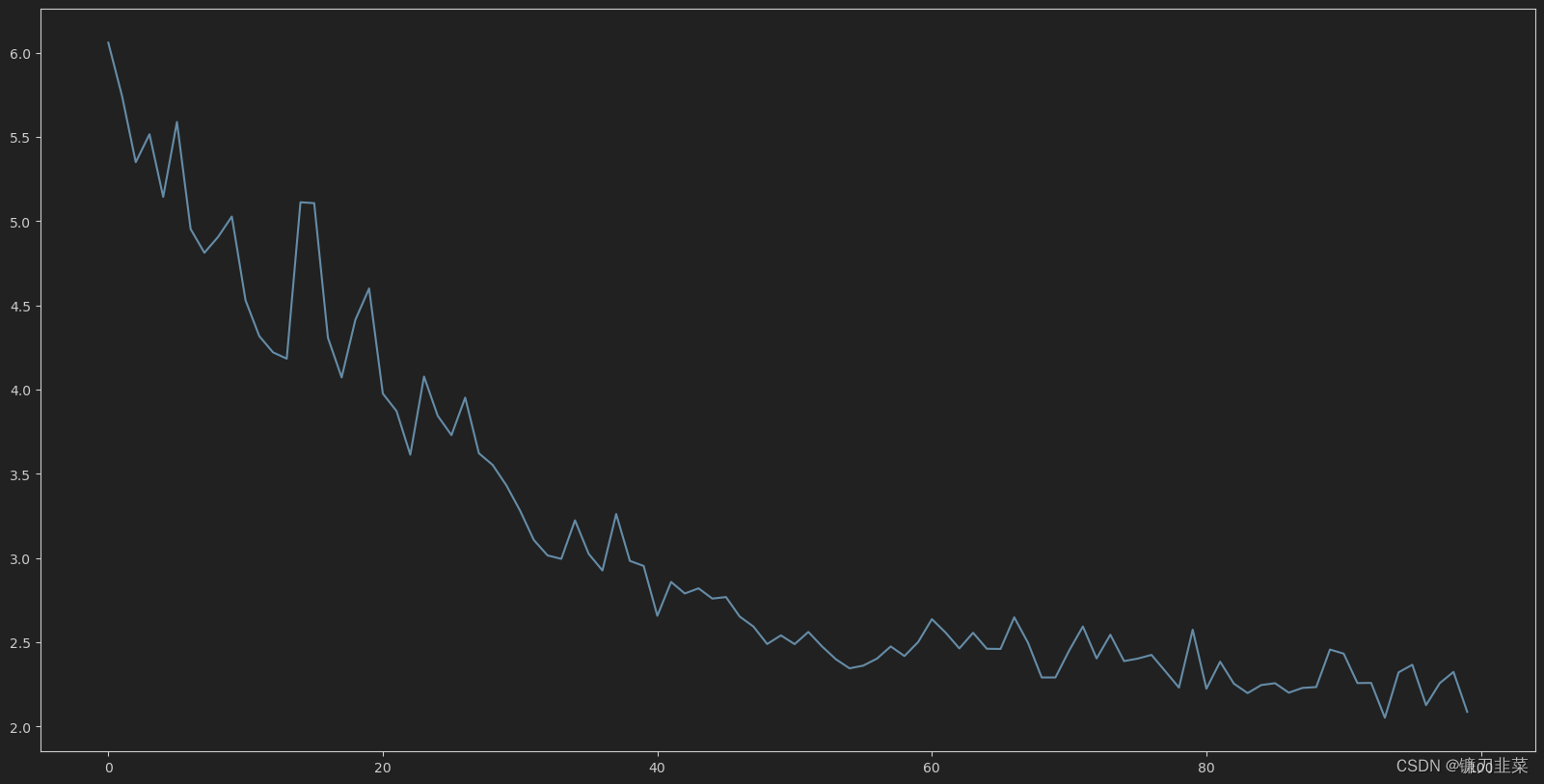
在训练完成后,在测试集上验证模型的表现。出于部署教程的考量,我们限制了模型训练的时间。如果你花更多时间训练模型,应该能得到更好的表现(80%-90%)。
为了更好地理解模型学到的节点和图的表示,我们使用了 t-SNE 来进行降维和可视化。

两张小图分别可视化了做完 1 层和 2 层图卷积后的节点表示。不同颜色代表属于不同类别的图的节点。可以看到,经过训练后,属于同一类别的节点表示更加接近。并且,经过两层图卷积后这一聚类效果更明显。其原因是因为两层卷积后每个节点能接收到 2 度范围内的邻居信息。
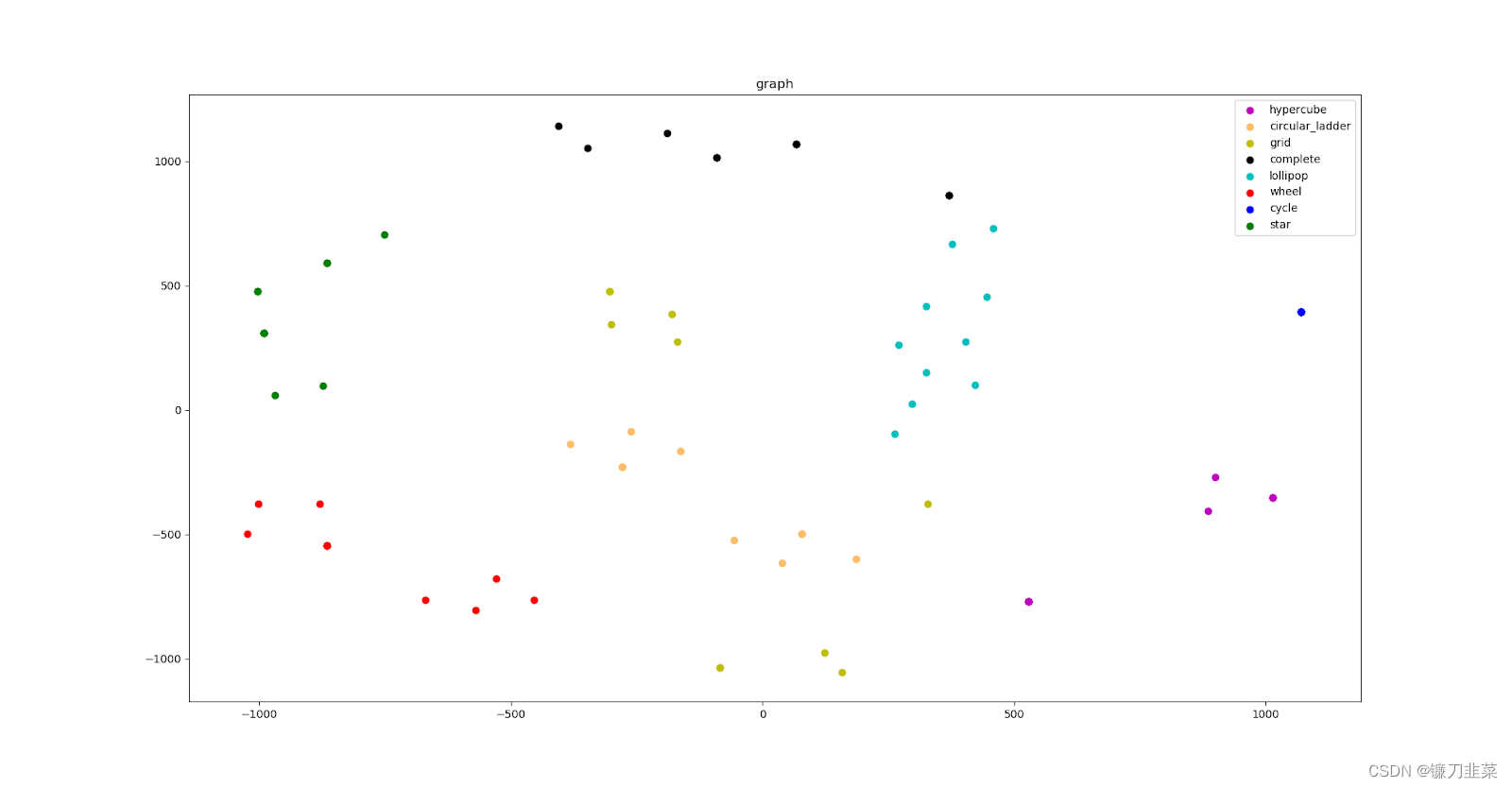
底部的大图可视化了每张图在做 softmax 前的 logits,也就是图表示。可以看到通过读出函数后,图表示能非常好地各自区分开来。这一区分度比节点表示更加明显。
核心代码
import datetime
import pandas as pdepochs = 100
log_step_freq = 10dfhistory = pd.DataFrame(columns=['epoch', 'loss', metric_name, 'val_loss', 'val' + metric_name])
print("Start Training........")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
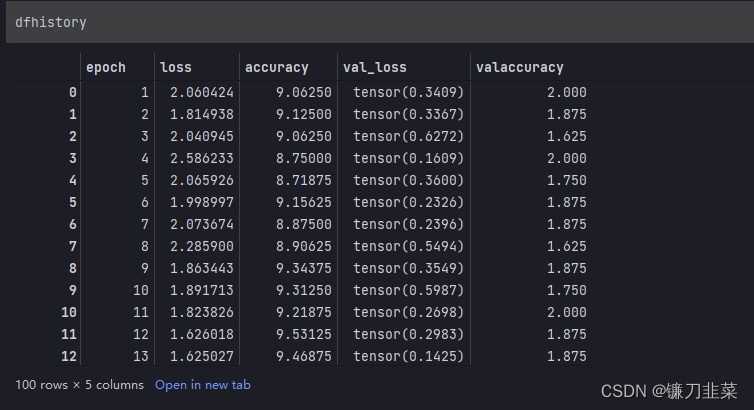
print("==========" * 8 + "%s" % nowtime)for epoch in range(1, epochs + 1):# 训练过程model.train()epoch_loss = 0.0metric_sum = 0.0step = 1for iter, (bg, label) in enumerate(data_loader, 1):# 梯度清零optimizer.zero_grad()# 正向传播损失prediction = model(bg)metric, _ = metric_func(prediction, label)label = label.to(torch.long)loss = loss_func(prediction, label)# 反向传播求梯度loss.backward()optimizer.step()# 打印batch级别日志epoch_loss += loss.detach().item()metric_sum += metric.item()if step % log_step_freq == 0:print(("[step = %d] loss: %.3f, " + metric_name + ": %.3f") % (step, epoch_loss / step, metric_sum / step))# 验证循环model.eval()val_loss = 0.0val_metric = 0.0val_step = 1for val_iter, (bg, label) in enumerate(val_loader, 1):with torch.no_grad():prediction = model(bg)val_metric, y_pred_cls = metric_func(prediction, label)label = label.to(torch.long)val_loss = loss_func(prediction, label)val_loss += val_loss.detach().item()val_metric += val_metric.item()# 记录日志info = (epoch, epoch_loss / step, metric_sum / step,val_loss / val_step, val_metric / val_step)dfhistory.loc[epoch - 1] = infoprint(("\nEPOCH = %d, loss = %.3f," + metric_name +" = %.3f, val_loss = %.3f, " + "val_" + metric_name + " = %.3f")% info)nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("\n" + "==========" * 8 + "%s" % nowtime)print("Finished Training...")
参考资料
[1] https://www.jiqizhixin.com/articles/2019-01-29-2
[2] Task4:Pytorch实现模型训练与验证
[3] Pytorch实战总结篇之模型训练、评估与使用
[4] t-SNE及pytorch实现
这篇关于【图神经网络】使用DGL框架实现简单图分类任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




