本文主要是介绍dgl 的cuda 版本 环境配置(dgl cuda 版本库无法使用问题解决),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 如果你同时有dgl dglcu-XX.XX 那么,应该只会运行dgl (DGL的CPU版本),因此,你需要把dgl(CPU)版本给卸载了
但是我只卸载CPU版本还不够,我GPU 版本的dglcu依旧不好使,因此吧GPU版本的也得卸载了重新安装
最新版的dgl我的cuda版本已经不配了,因此,找老的版本:Linux 64 :: Anaconda.org
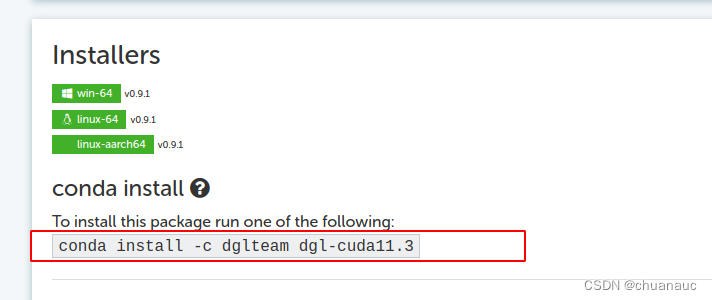
我下载的是这个:Dgl Cuda11.3 :: Anaconda.org
含义是 GPU版本的cuda版本为11.3,安装的命令行语句如下(记得关闭魔法梯子,否则会下载不成功)
然后运行demo发现torch也被卸载掉了,那就继续重装:
进入torch找老版本,我的cuda 版本11.4 ,这个版本比较特殊,直接看作11.3即可
因此,torch 可以下载

建议使用pip版本的,因为conda版本的命令我试过,没下载成功,因为开不开魔法梯子我都无法在命令行访问到anaconda官网,离谱,,明明刚还用conda下载了dglcu
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113下载完成后再重新运行一下 ,运行下dgl的示例demo :
import dgl
import torch as th
u, v = th.tensor([0, 1, 2]), th.tensor([2, 3, 4])
g = dgl.graph((u, v))
g.ndata['x'] = th.randn(5, 3) # 原始特征在CPU上
print(g.device)
cuda_g = g.to('cuda:0') # 接受来自后端框架的任何设备对象
cuda_g.device
cuda_g.ndata['x'].device # 特征数据也拷贝到了GPU上
# 由GPU张量构造的图也在GPU上
u, v = u.to('cuda:0'), v.to('cuda:0')
g = dgl.graph((u, v))
print(g.device)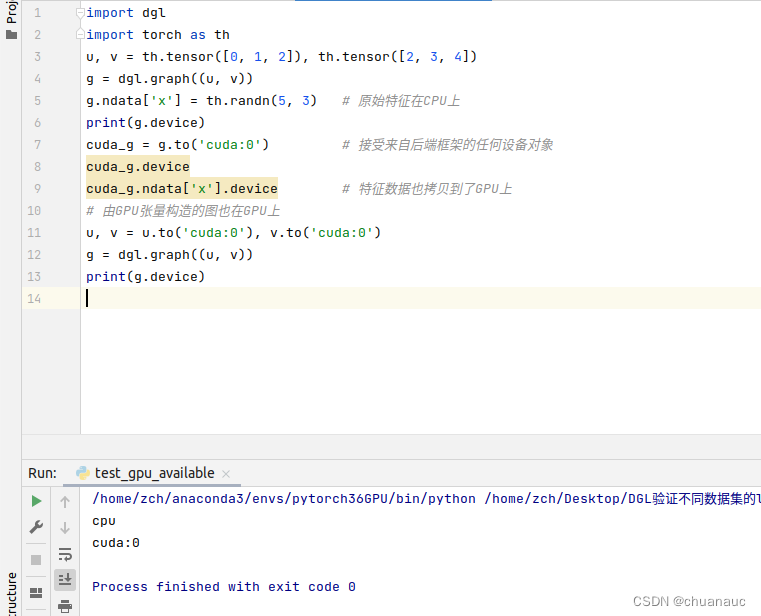 然后就ok
然后就ok
win上重新安装 :anaconda + python + pytorch + CUDA也不知道需不需要安装 ,,,
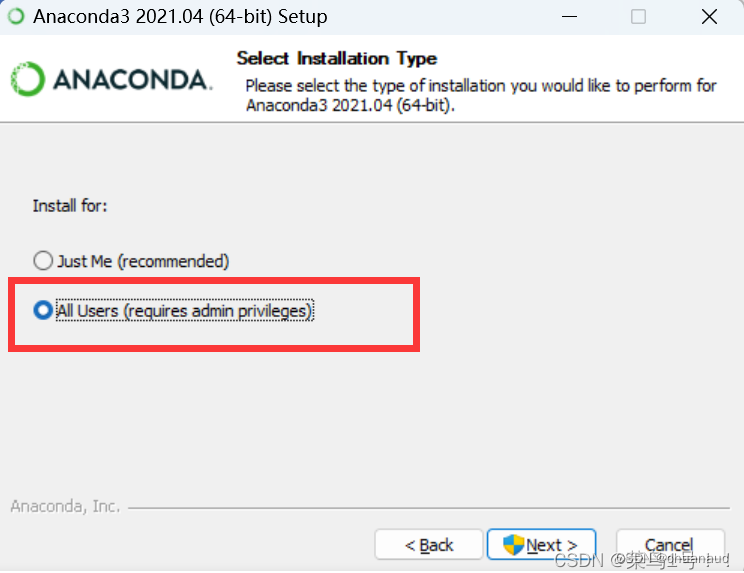
anaconda的安装有两个重要的点:
一个是选择使用人的时候选择:all user :
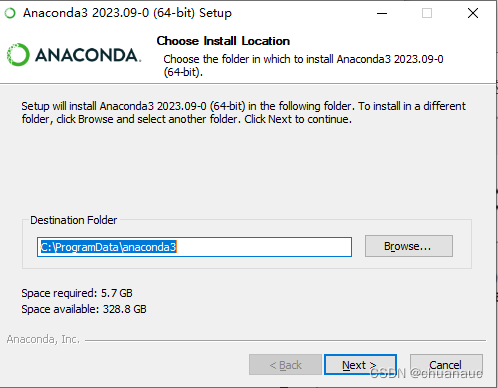
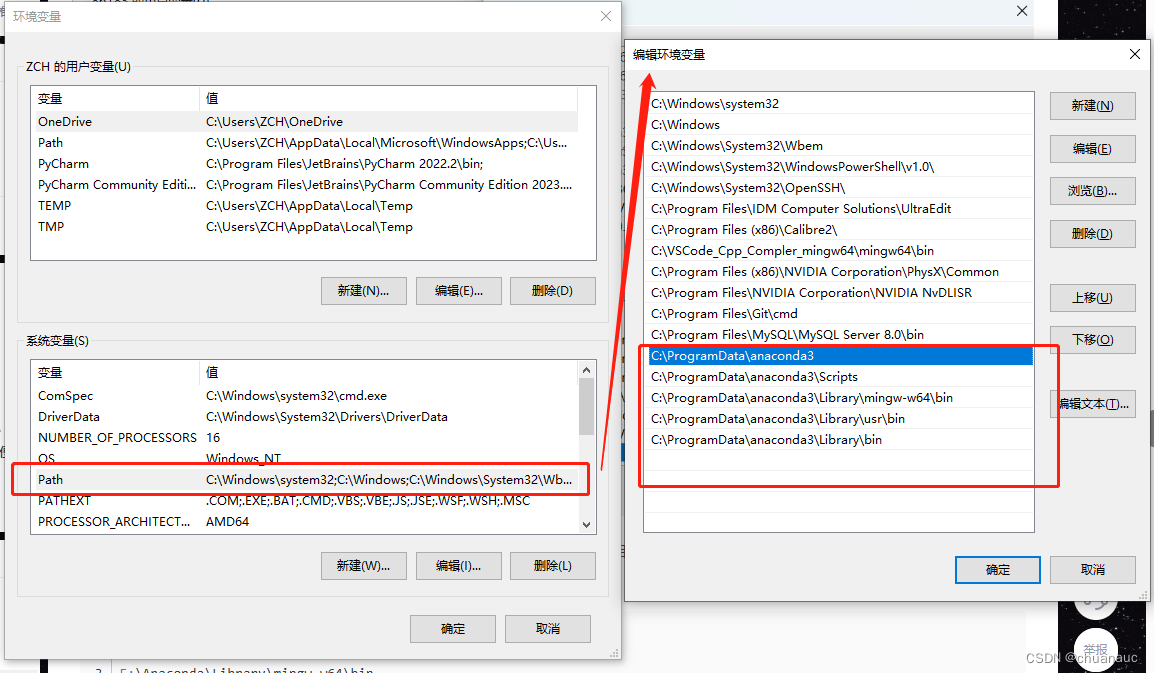
其次是记得检查一下环境变量,如果anaconda没有个你自动添加上,记得anaconda安装完添加在系统变量的path路径里面:
==》因此,在下载anaconda的时候,截图保存下,到底吧anaconda下载到哪里了,如下图所示,别到时候找不到anaconda的一些Bin啊,Script啊,啥的 环境变量的位置
下载anaconda的参考:Anaconda超详细安装教程(Windows环境下)_conda安装-CSDN博客
由于我们的安装顺序是 :安装pycharm,此时pycharm中没有python环境,
然后我们安装anaconda,anaconda一般会给你创建一个 root 的环境
现在我们需要将pycharm使用anaconda创建的环境,就是那个初始的 root 环境 :方法是
右键选中Interpreter 设置,然后就可以在 add new interpreter 中选择 anaconda环境了:
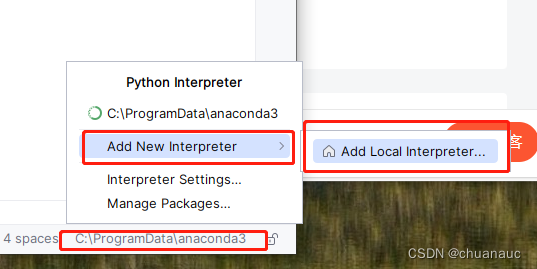

选择使用现存的anaconda环境,anaconda一般就可以自己在你的电脑上匹配出来对应的位置了
点击OK,就可以使用这个anaconda环境了,加载这个环境中包含的库需一段时间耐心等待一下吧
下载 torch :如果有GPU记得下载GPU版本的torch,CPU和GPU版本的torch好像不兼容,所以注意下
pytorch下载地址:https://pytorch.org/
按照自己的电脑环境,获得下载的命令行语句:
然后在pycharm这个IDLE里面直接使用terminal,把这条语句打进去:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121之所以使用pycharm自己的terminal是为了确保在我们想要安装的anaconda环境中(现在的anaconda的环境只有最初始的Base环境一个,以后多了容易安装错,所以在pycharm的terminal中方便)
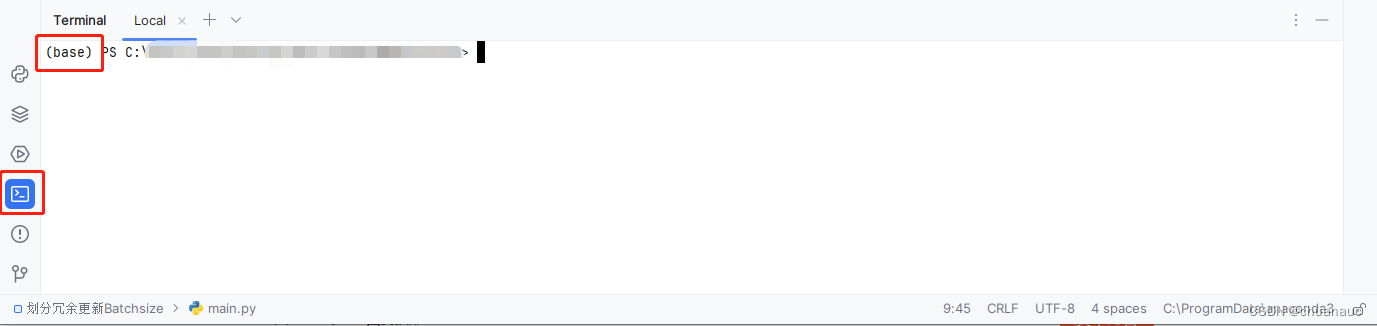
确保安装的位置没错
 安装完了就完事啦
安装完了就完事啦
最后运行下述代码,确保GPU版本的Torch安装成功:
import torch# 检查是否有可用的GPU
if torch.cuda.is_available():device = torch.device("cuda") # 使用GPUprint("GPU is available")
else:device = torch.device("cpu") # 使用CPUprint("GPU is not available, using CPU")# 创建一个随机张量并将其移动到设备上
x = torch.rand(3, 3).to(device)# 打印设备类型和张量
print("Device:", device)
print("Tensor:", x)
然后可能出现 “import torch” 语句的 torch 部分红色波浪线,报错显示没找到这个库
没关系,是因为虽然下载成功Torch库,IDLE也需要花一段时间加载告知IDLE,你直接运行他是会报错的,重启一遍pycharm就没事了
终于,安装DGL:
这篇关于dgl 的cuda 版本 环境配置(dgl cuda 版本库无法使用问题解决)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




