背景
压力测试是评估应用性能的一种有效手段。此外,越来越多的应用被拆分为多个微服务而每个微服务的性能不一,有的微服务是计算密集型,有的是IO密集型。
因此,压力测试在基于微服务架构的网络应用中扮演着越来越重要的角色。本文将在Kubernetes集群中使用JMeter 3.2来对Company应用进行性能评估。
在上文《微服务化后的按需精细化资源控制》中已了解到Manager服务的资源需求最大,本次使用JMeter对Company应用进行精细的性能测试。
制定JMeter测试方案
制定的测试方案为:
-
由于登录认证会造成较大时延,故在压力测试主体运行前完成用户认证事宜;
-
对Company应用多个接口持续并发访问,QueryWorker, QueryBeekeeperDrone, QueryBeekeeperQueen分别对Company中的服务发起请求压力。
测试方案文件笔者已托管于github上,可直接获取:
git clone https://github.com/ServiceComb/ServiceComb-Company-WorkShop
cd ServiceComb-Company-WorkShop/stress-tests
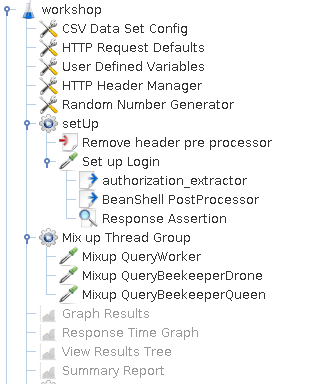
图1 测试计划
在我们测试计划的开始,我们设置了一些在所有线程组都能共享的全局配置。其中,CSV Data Set Config组件从本地csv文件中加载测试服务器的信息。HTTP Request Defaults组件则为每个请求预设了默认的请求服务器信息,如IP和端口。User Defined Variables组件定义了全局共享的变量。HTTP Header Manager组件自动为每个请求添加HTTP的请求头部。
接着就是setUp线程组了。其作用主要是处理用户认证。由于Cookie在网络应用中得到较广泛的应用,因此JMeter中内置的认证方式是通过HTTP Cookie Manager组件来完成的。然而,我们的Company示例采用的是基于Token的认证方式而不是基于Cookie的认证方式。因此,这给我们在JMeter中处理认证添加了一点难度。Remove header pre processor组件使用了以下的脚本来去掉登录时请求中带有默认的请求头部,即登录请求时并不需要带有鉴权的请求头部。
import org.apache.jmeter.protocol.http.control.Header;
sampler.getHeaderManager().removeHeaderNamed("Authorization");
然后我们通过Set up Login组件发起一次登录请求来获取用户登录鉴权信息。之后再通过正则表达式提取组件authorization_extractor来提取响应头部中的Authorization对应的值。由于变量无法在不同的线程组中共享和传递,这时候BeanShell PostProcessor组件就派上用场了,它主要工作就是将当前线程组中的目标变量转换为全局属性。
${__setProperty(Authorization,${Authorization},)}
在测试计划的最后部分就是我们要在Company示例上进行的压力测试。测试所选取的三个接口都是通过经理服务路由至其他两个服务的,即技工服务和养蜂人服务。在我们测试开始之前,我们通过打开StressTest的开关来禁用经理服务提供的缓存能力,从而使得技工服务和养蜂人服务能够处理到用户请求的计算任务。此外,我们通过将请求参数设置为1来简化技工服务和养蜂人服务的计算任务。
启动测试
-
在Kubernetes集群中以无资源限制的方式来运行Company应用。
-
修改hosts.csv文件,使其匹配正在Kubernetes集群中运行的Company应用的服务地址。其中,默认的hosts.csv文件内容为:
127.0.0.1,8083 -
运行测试,启动200个并发线程发起请求压力,并设置测试时常为600秒。
jmeter -n -t workshop.jmx -j workshop.log -l workshop.jtl -Jthreads=200 -Jduration=600
测试结果
在不同并发度下的测试结果如下图所示:
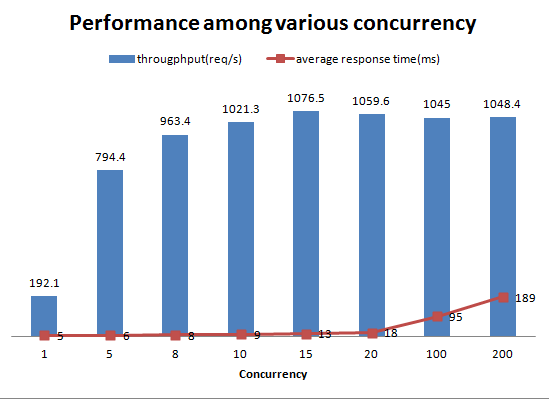 图2 并发不同时的性能比较
图2 并发不同时的性能比较
可以看出,经理服务的性能在到达瓶颈(15并发度)前非常稳定,保持平均响应时间极低的情况下吞吐量快速上升到最大约1000请求每秒的水平。 但随着并发度的进一步提升,平均响应时间开始快速增加。因此,将响应时间统计数据作为评估熔断超时的设置非常合适。
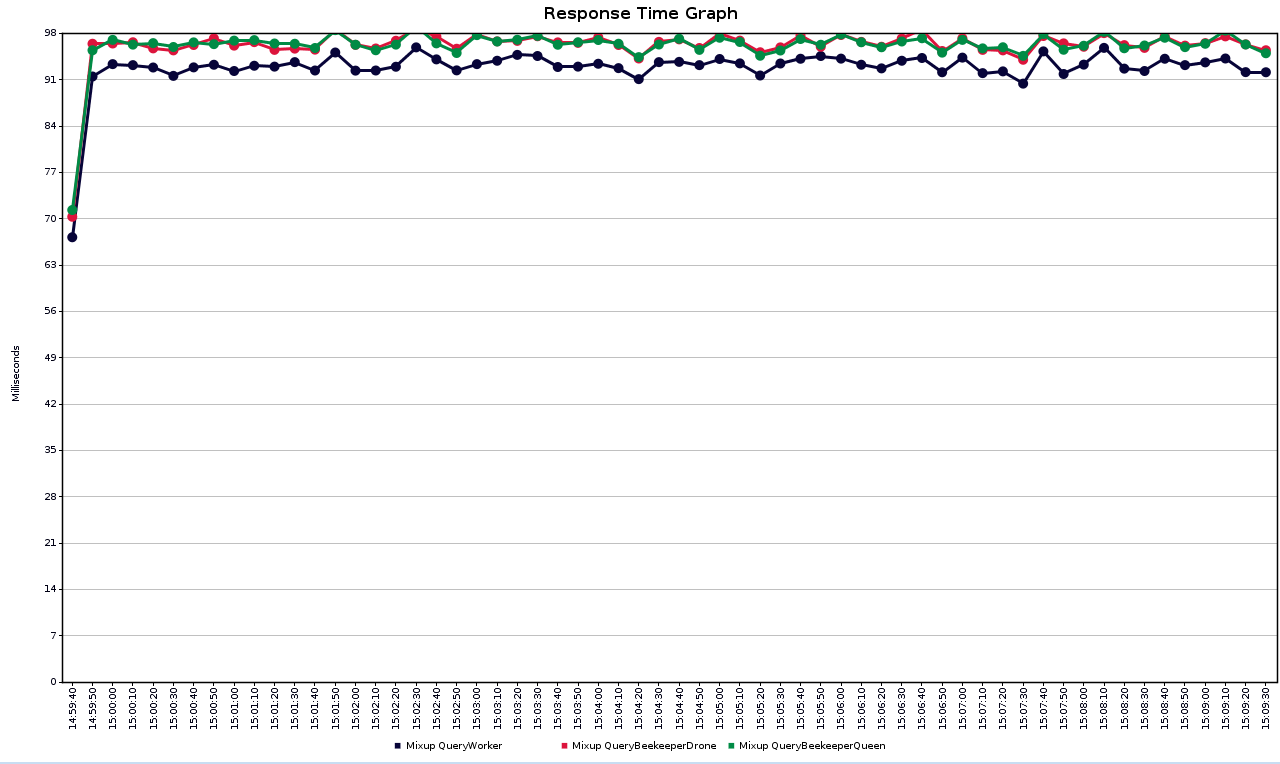 图3 不同服务的平均响应时间
图3 不同服务的平均响应时间
上图显示了不同服务的平均响应时间。由于养蜂人服务需要调用技工服务,因此其响应时间相对于技工服务的响应时间要稍微久一点。
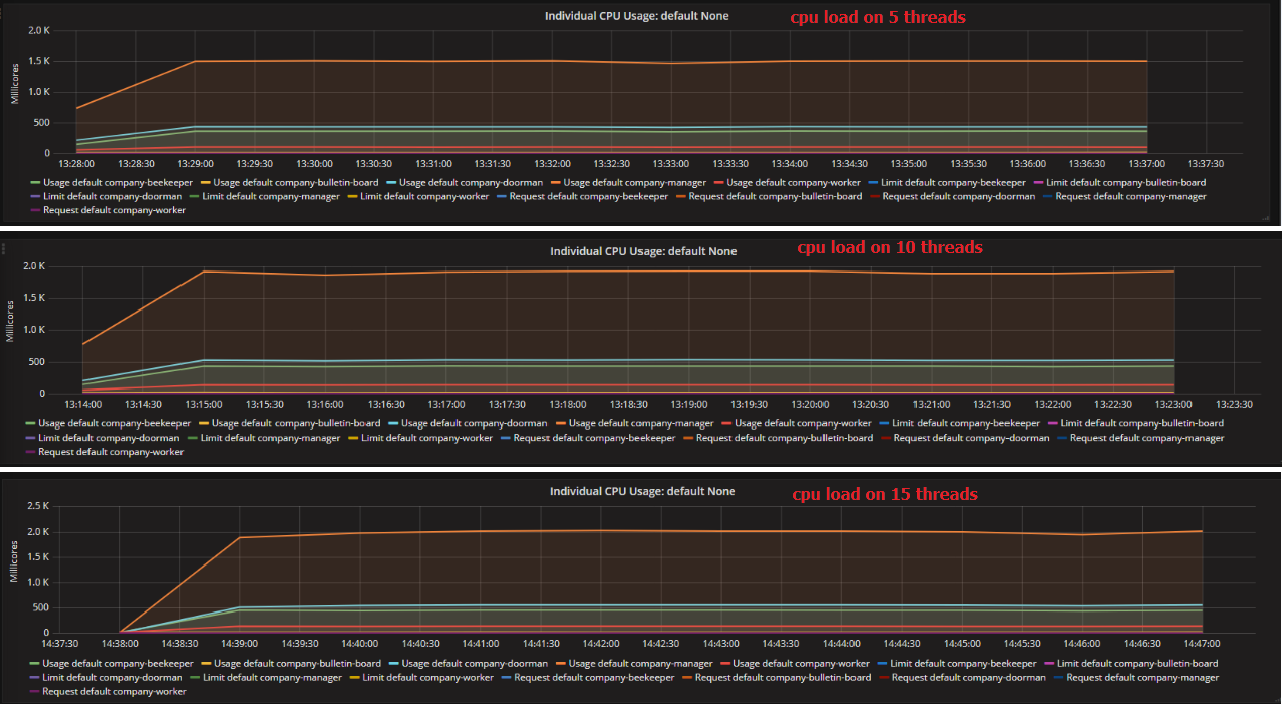 图4 不同并发度下CPU的负载
图4 不同并发度下CPU的负载
为了找出性能卡在了15并发度时的原因,我们回看了Heapster上的监控数据。如下图所示,显然,经理服务是当前系统的瓶颈所在。它在吞吐量为1000 req/s时达到了最大的CPU负载。 相对而言,其它服务对资源的需求的增长速度要慢得多。
由于经理服务的日志是直接输出到stdout上的,且JMeter的测试端以单机模式运行时可能并不能同时模拟出足够的并发量。依此对在同一并发度(200)下不同log的设置(log4j1 stdout, log4j2 stdout,log4j2 异步,无日志输出)进行测试。其中,异步log在log4j2.xml文件中的设置如下所示:
<?xml version="1.0" encoding="UTF-8" ?>
<Configuration status="INFO"> <Appenders> <RandomAccessFile name="RandomAccessFile" fileName="manager.log" immediateFlush="false" append="false"> <PatternLayout pattern="%d [%p] %m %l%n"/> </RandomAccessFile> </Appenders> <Loggers> <asyncRoot level="info"> <AppenderRef ref="RandomAccessFile"/> </asyncRoot> </Loggers> </Configuration> 此外,还需要添加如下disruptor的依赖项使异步的设置生效:
<dependency><groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>3.3.6</version> </dependency> 没有日志输出的设置仅仅是将上述log4j2.xml文件中的日志输出级别从info改为off即可。此外,我们还使用JMeter分布式的模式进行了相关的测试。JMeter中使用分布式的模式来运行主要分两步:
-
在每个测试从节点上运行jmeter-server,其运行指令如下:
jmeter-server -Djava.rmi.server.hostname=$(ifconfig eth0 | grep "inet addr" | awk '{print $2}' | cut -d ":" -f2) -
在测试主节点上运行jmeter,指令如下:
jmeter -n -R host1,host2 -t workshop.jmx -j workshop.log -l workshop.jtl -Gmin=1 -Gmax=2 -Gthreads=200 -Gduration=600注意事项:JMeter属性在分布式模式下并不能生效,需要将其声明为全局的属性。因此,此处我们用的是-G的选项而不是之前的-J的选项。
运行结果如下所示:
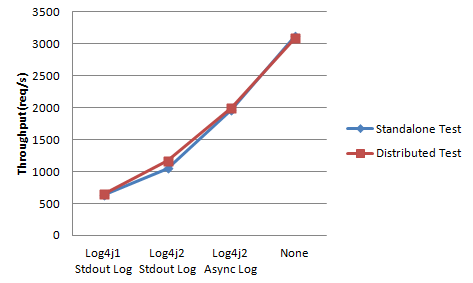
从上图可以看出:
-
JMeter单机测试和分布式测试的性能都非常接近,说明单机模式的JMeter测试暂时来说是足以模拟出足够的并发数来处理当前的测试场景的。
-
日志的输出的确对系统的性能造成了较大的影响,可以看到,异步输出日志的方式能比同步输出的方式提升接近100%的吞吐量。因此,在生产环境下使用完全同步输出日志的方式可能并不会有较理想的性能。
-
log4j2的吞吐量相对于log4j1而言大幅提高了约40%,内存使用量也更少了。因此,推荐使用性能更佳的log4j2替换掉陈旧的log4j1。
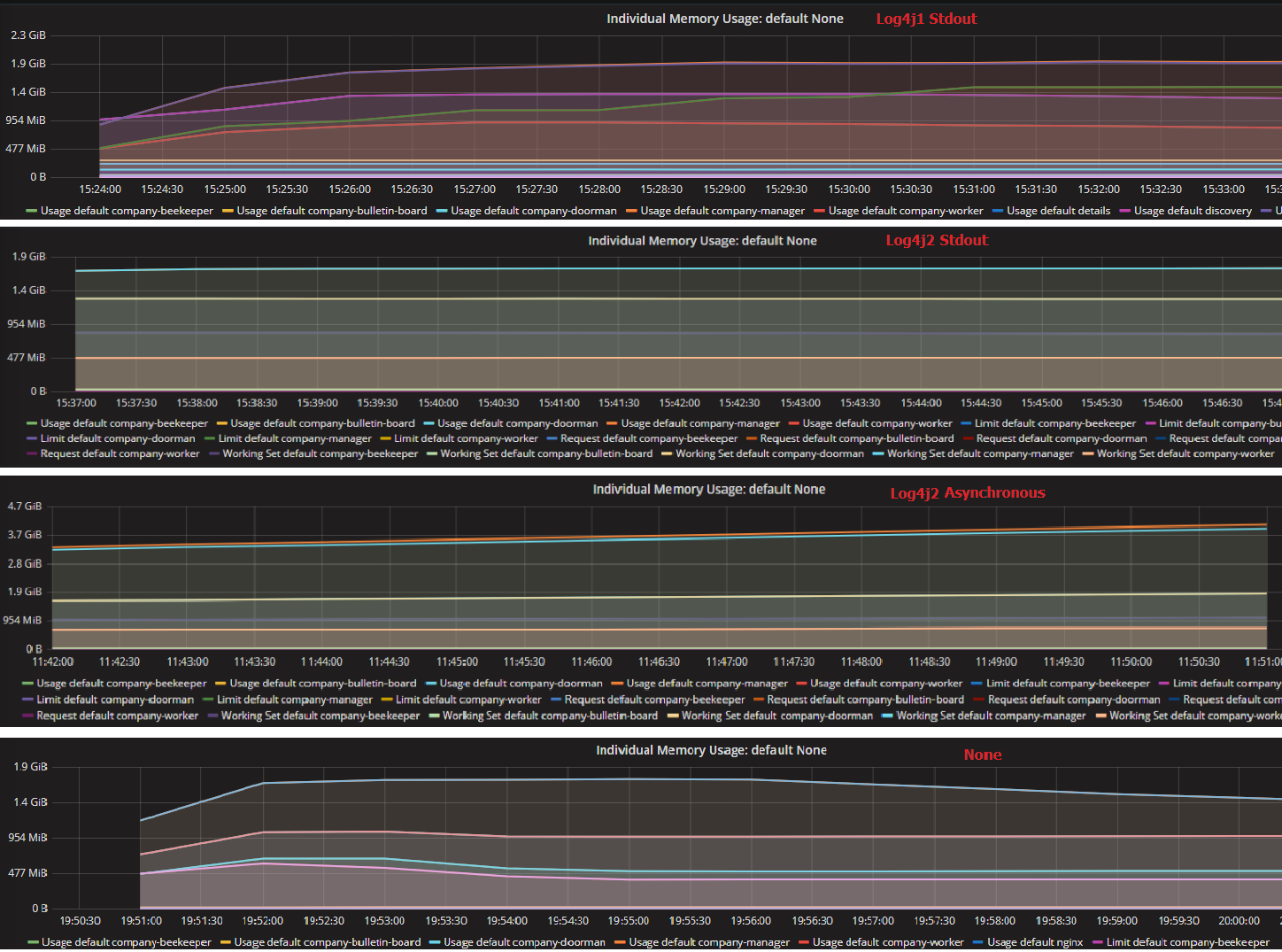 图5 不同日志设置下的内存使用量
图5 不同日志设置下的内存使用量
尽管异步日志的方式能极大地提高系统的吞吐量,但它同时也占用了较多的内存,如图5所示。
 图6 测试过程的内存使用量
图6 测试过程的内存使用量
图6显示了在测试过程中不同服务的内存使用量。由于Company示例只是一个简单的用例,在测试过程中各个服务的内存使用率都相对稳定。然而,相对告示栏服务(使用go语言编写)的内存使用量而言,其它以Java来编写的服务则占用了较多的内存。
总结
对应用进行压力测试往往能在应用投入生产环境前帮助我们找出服务中潜在的问题。压力测试也能模拟生产环境,从而来验证服务是否已达到规定的性能指标。而根据压力测试的结果,我们可以权衡Pod部署时的设置来保证SLA的同时获得最大的系统吞吐能力。
基于微服务架构的应用不仅在设计、编码及测试方面变得更加灵活,同时也使得部署更加方便。基于微服务架构能够保证资源的弹性伸缩极其迅捷,我们可以根据服务的真实可承受压力设置不同的副本数和资源配置来节约资源。此外,在云上也能借助其弹性伸缩能力使得服务能够应对访问风暴。
出处:http://servicecomb.incubator.apache.org/cn/docs/stress-test-on-company-with-jmeter-in-k8s/





