本文主要是介绍睿治数据治理管理平台白皮书_天冕大数据|研发SQL自动化审核与治理平台的经验分享...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着互联网、大数据、云计算和人工智能等技术在国内的跳跃式发展,金融科技已成为金融机构角逐的新赛道。而金融与科技的有效结合,涉及应用水平、服务能力以及监管效能等方方面面,在这种大背景下,金融企业数据的内部安全管控、跨界融合风险防护、云环境外围系统攻击防御,显得尤为重要。

1、为什么要研发SQL自动化审核与治理平台
根据近年来发布的数据泄密成本研究,发现除涉及外部恶意违法攻击,如漏洞攻击、SQL注入等手段窃取敏感数据外,近半成是由于内部或第三方承包商权限等管控缺失或IT业务流程故障导致的数据泄密。
因此除个人信息隐私识别、数据加密、传输行为审计、数据脱敏等手段外,用于数据库账号权限管制、SQL审核及注入风险防御、自动化运维、SQL洞察、高危行为基准、权责行为追踪、流程合规化的SQL自动化审核与治理平台的研发刻不容缓。
2、当前存在哪些问题
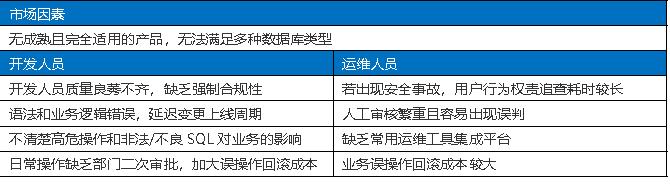
3、自研产品解决了哪些问题

4、如何具体落地
SQL自动化审核与治理这个概念早在前几年就是比较热门的概念,业内也不乏有优秀的平台。目前MySQL数据库相关的审核平台已较为成熟。而如何从自身实际出发,做好安全防护的同时,创新性的融入PostgreSQL、MongoDB、Redis等开源数据库成为一个不小的挑战。
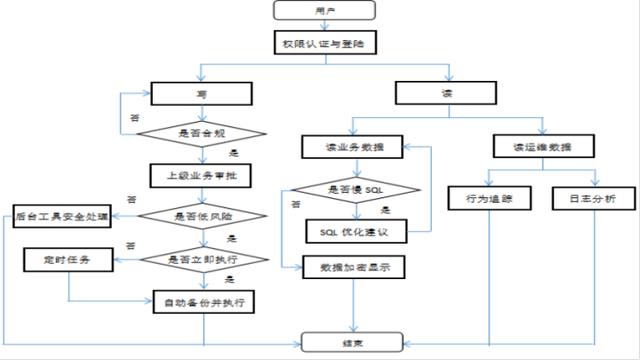
平台的构建离不开需求的分析与设计。在平台设计之初,我们通过读、写两种行为划分用户操作,加入权限认证管理严格把控账号信息安全,且对用户行为进行审计。
针对写操作,会通过繁杂的正则表达式和python脚本对用户行为进行语法正确性核查;利用执行计划或者表信息对更新/插入语句进行影响范围和风险等级估算;利用自定义的高位特征检测对高危操作进行禁止或警告;利用gh-ost或python脚本将修改语句转入后台工具自动处理;利用虚拟索引、SQL执行计划、表/视图信息等对新增索引在线评估。其中,有事务概念的数据库可利用事务进行回滚操作,无事务概念的利用脚本解决。
针对读操作,加入SQL成本判断并禁止部分非法/不良SQL查询方式。另外加入sql延时执行功能、添加pgbadger、redis-benchmark、mtools进行日志分析外,也新增了mongo-shake、shemasync、binlog2sql进行同步或反解析。
自动化固然是好的,但我们仍然觉得有些判断和操作是自动化不能代替的。因此平台中增设了上级业务审批的人为确认操作,目的是做二次确认。即开发运维人员等在有权限且合规的情况下,同部门上级人员从业务层面做二次检验,从而减少误操作的风险和业务逻辑判断失误的情况。
实际设计流程图可参照如下:
5、结束语
工欲善其事,必先利其器。SQL审核与治理平台的研发一定程度上优化了DBA的审核工作、提高了SQL的质量、也减少了开发运维人员的沟通成本。最重要的是在安全管制、风险防护、数据泄露等层面提供安全保证和安全事故的权责追查。但SQL审核与治理应当是个长久且需日益完善的环节,这样才能更好为业务和技术服务。
自动化的背后应当是判断谨慎化、流程合规化、功能全面化、产品智能化和系统健壮化的。只有日常做好做精,提前发现和解决潜在的性能和安全问题,做好防御工作,才能防患于未然。
这篇关于睿治数据治理管理平台白皮书_天冕大数据|研发SQL自动化审核与治理平台的经验分享...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





