本文主要是介绍图数据库 之 Neo4j - Cypher语法基础(5),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
节点(Nodes)
Cypher使用()来表示一个节点。
() # 最简单的节点形式,表示一个任意无特征的节点,其实就是一个空节点(movie) # 如果想指向一个节点在其他地方,我们可以给节点添加一个变量名(如movie),表示一个变量名为 movie的节点。(:Movie) # 表示一个标签为 Movie 的匿名节点(movie:Movie) # 表示一个变量名为 movie,标签为 Movie 的节点(movie:Movie {title: "hello"}) # 花括号里定义节点的属性,属性都是键值对(movie:Movie {title: "hello", released: 1999}) # 多个属性(movie:Movie:User) # 多个标签,表示一个变量名为 movie,标签为 Movie 和 User 的节点(movie:Movie), (user:User) // 表示一个变量名为 movie,标签为 Movie 的节点和一个变量名为 user,标签为 User 的节点属性可以用来存储信息或者来条件匹配(查找)
创建节点
创建如下节点
CREATE (movie:Movie {title:"功夫熊猫",act:"杰克",release_time:"2024-01-01"});
CREATE (movie:Movie {title:"战狼2",act:"吴京",release_time:"2024-01-01"});
CREATE (user:User {name:"吴京",sex:"男"});
CREATE (user:User {name:"杰克",sex:"男"});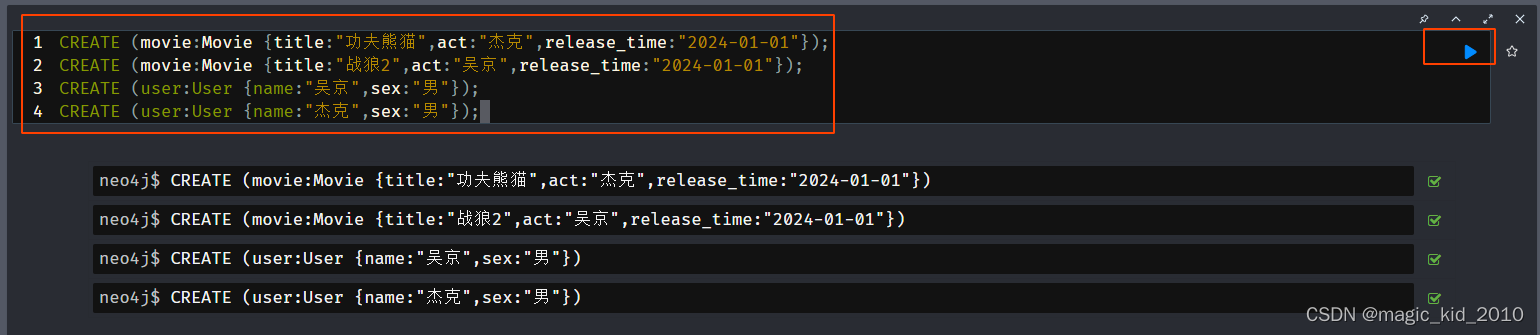
创建完成后,可以看到 Node labels 一共有4个节点,节点类型有 Movie、User。
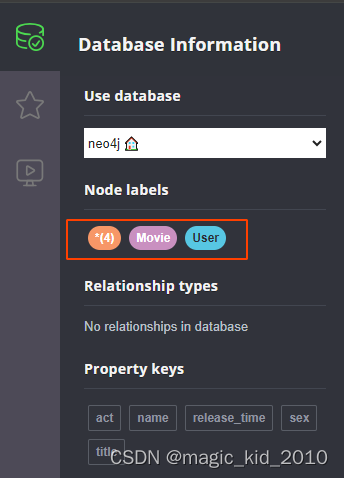
查看节点
可以分别点击节点进行查看,对应的语法也会显示出来
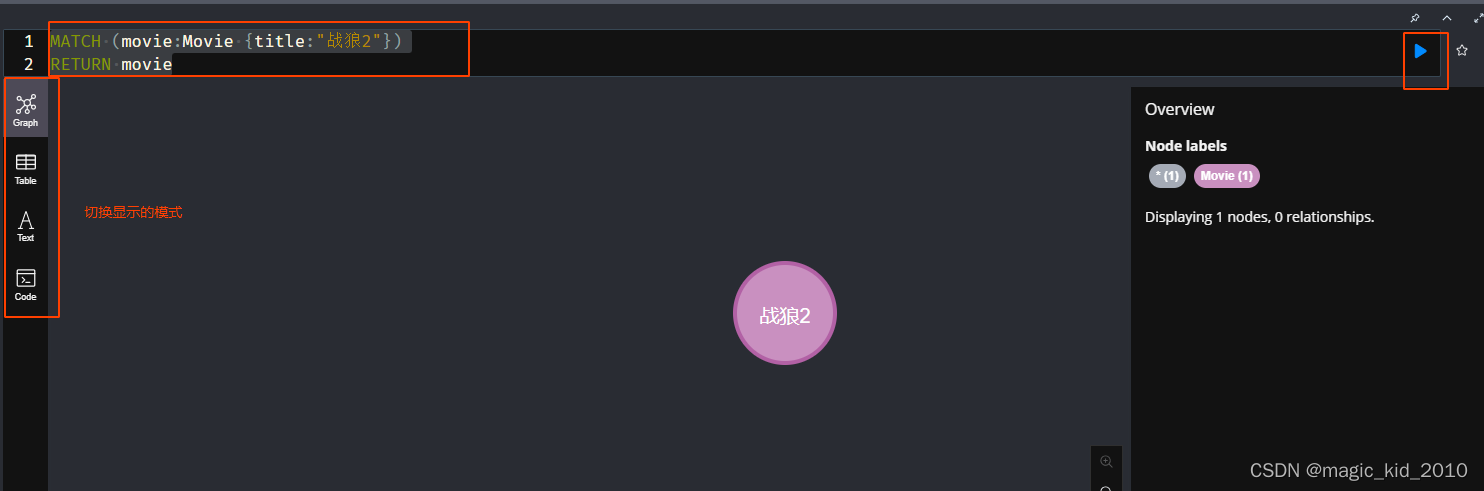
根据条件查找节点
MATCH (movie:Movie {title:"战狼2"})
RETURN movie
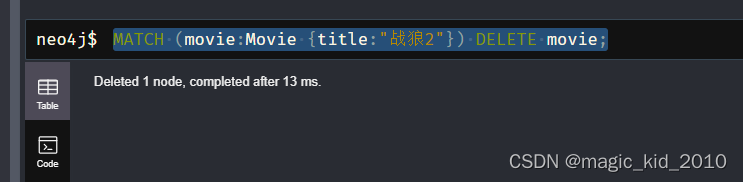
删除节点
MATCH (movie:Movie {title:"战狼2"}) DELETE movie;

更新节点属性
CREATE (movie:Movie {title:"战狼2",act:"吴京",release_time:"2024-01-01"});
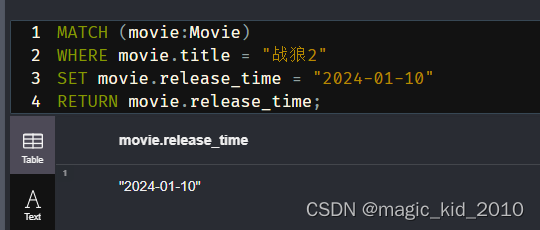
返回指定属性
MATCH (movie:Movie)
WHERE movie.title = "战狼2"
SET movie.release_time = "2024-01-10"
RETURN movie.title AS title;
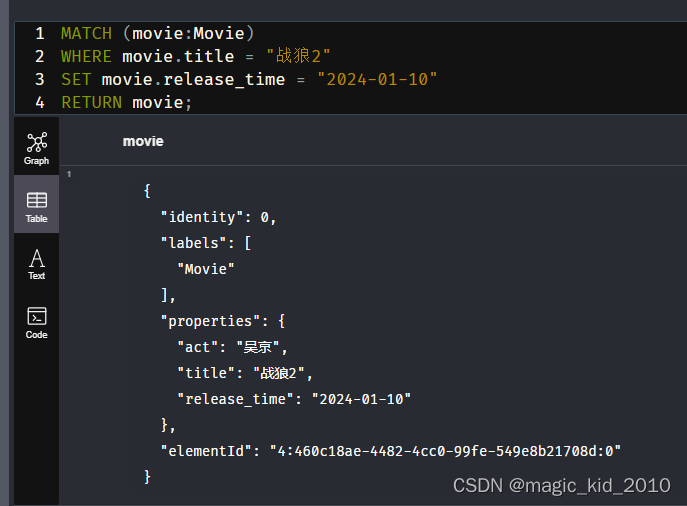
返回全部属性
MATCH (movie:Movie)
WHERE movie.title = "战狼2"
SET movie.release_time = "2024-01-10"
RETURN movie;
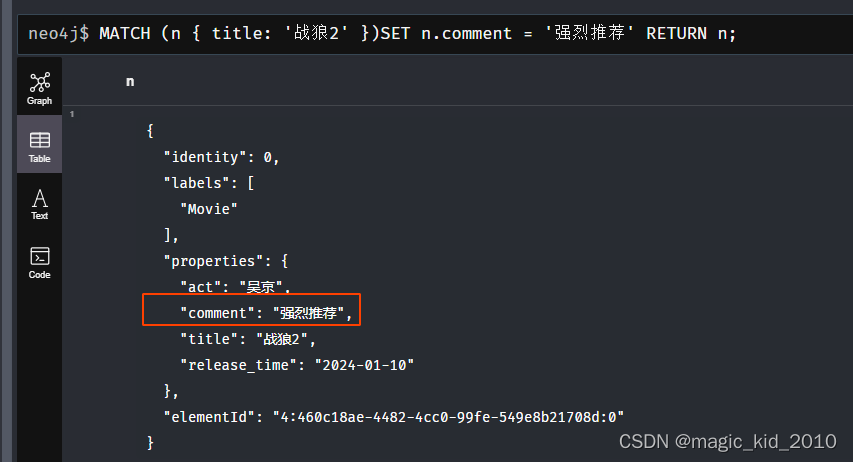
节点增加属性
MATCH (n { title: '战狼2' })SET n.comment = '强烈推荐' RETURN n;
节点删除属性
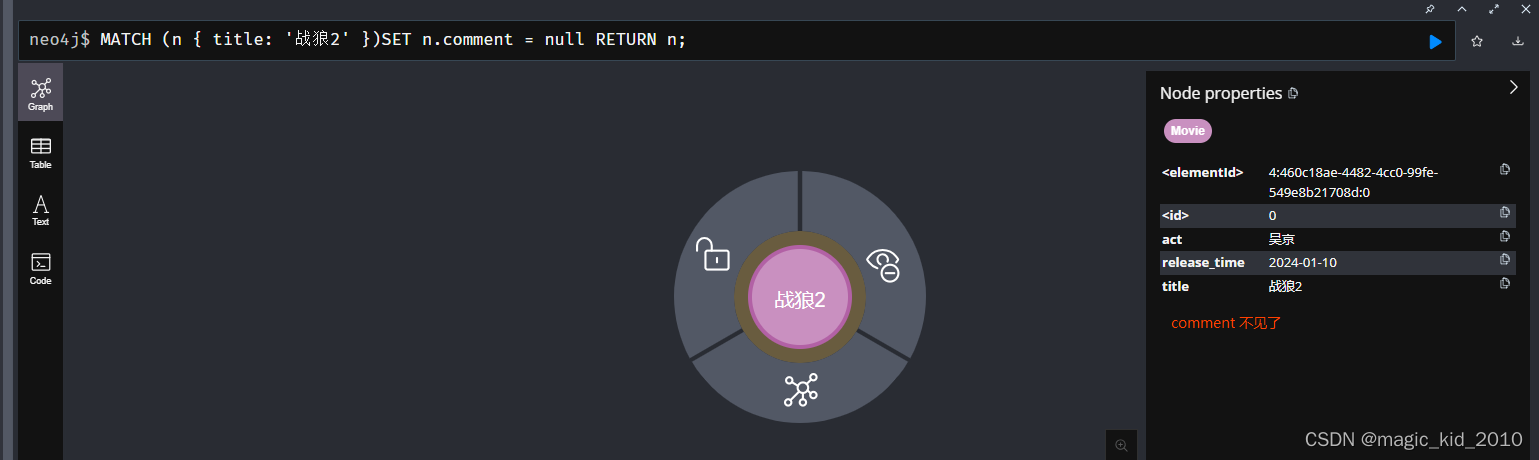
如果设置属性的值是NULL,相当于把该属性从节点或关系中移除
MATCH (n { title: '战狼2' })SET n.comment = null RETURN n;
标签(Labels)
标签用于对节点进行分类,可以将节点进行分组,如吴京和杰克都是演员。一个节点可以没有标签,也可以有多个标签,如吴京可以是演员,也可以是导演、出品人。可以根据标签类型对特定节点进行查询。
创建标签
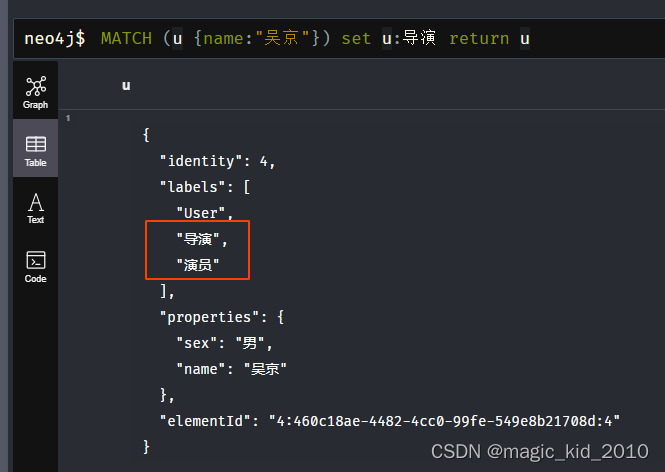
MATCH (u {name:"吴京"}) set u:演员 return u
MATCH (u {name:"吴京"}) set u:导演 return u
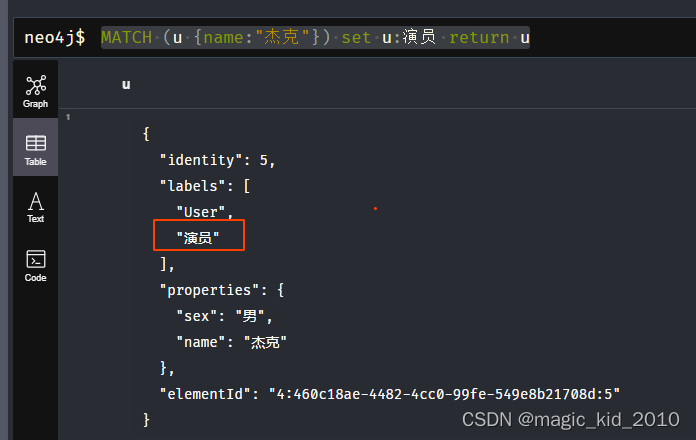
MATCH (u {name:"杰克"}) set u:演员 return u

查找标签
match (n:演员) return n;
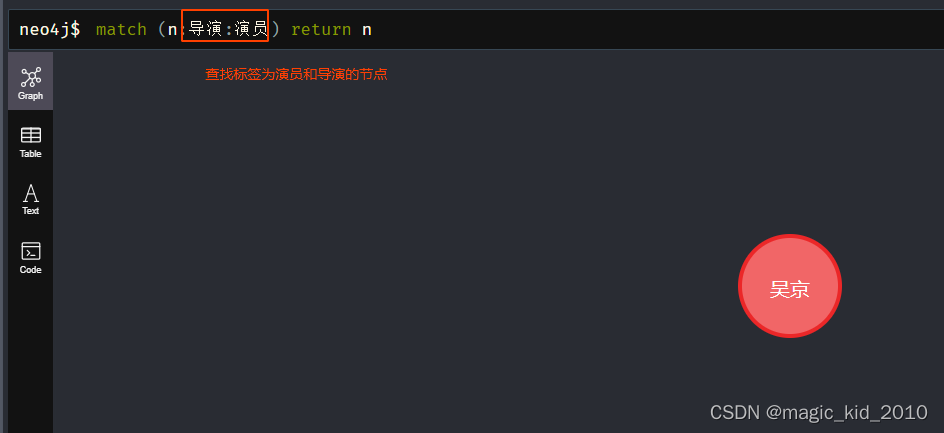
match (n:导演:演员) return n;

删除标签
MATCH (u:User {name: '吴京'}) REMOVE u:演员
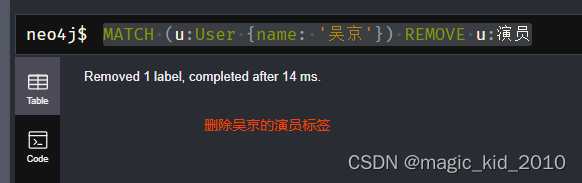
修改标签
MATCH (n:User {name: '吴京'}) SET n:出品人 REMOVE n:导演
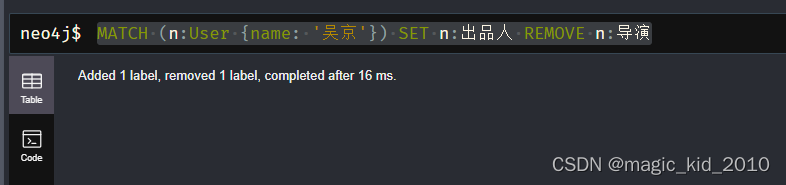
关系(Relationships)
两个节点之间会有关系,添加前后相关信息在数据中。
两个节点之间存在关系,则使用双横杠 -- 和箭头 >, < 的组合来表示。
(a)-->(b) # 表示节点 a 到节点 b 的关系(a)<--(b) # 表示节点 b 到节点 a 的关系(a)--(b) # 允许不使用箭头,表示节点 a,b 之间存在关系,不考虑方向性(a)-->(c)<--(b) # 表示节点 a,b 到节点 c 的关系同时,Cypher 使用方括号 [] 和冒号 : 为关系赋予变量名与设置标签,使用管道符 | 隔开多个关系标签。
(a)-[r:REL_TYPE]->(b) # 表示一个节点 a 到节点 b 的关系 r,标签为 WRITE(a)-[r:REL_TYPE1|REL_TYPE2]->(b) # 表示一个节点 a 到节点 b 的关系 r,标签为 WRITE 或者 PARTICIPATE创建关系
MATCH (u:User {name: '吴京'}), (m:Movie {title: '战狼2'}) CREATE (u)-[:出品]->(m)

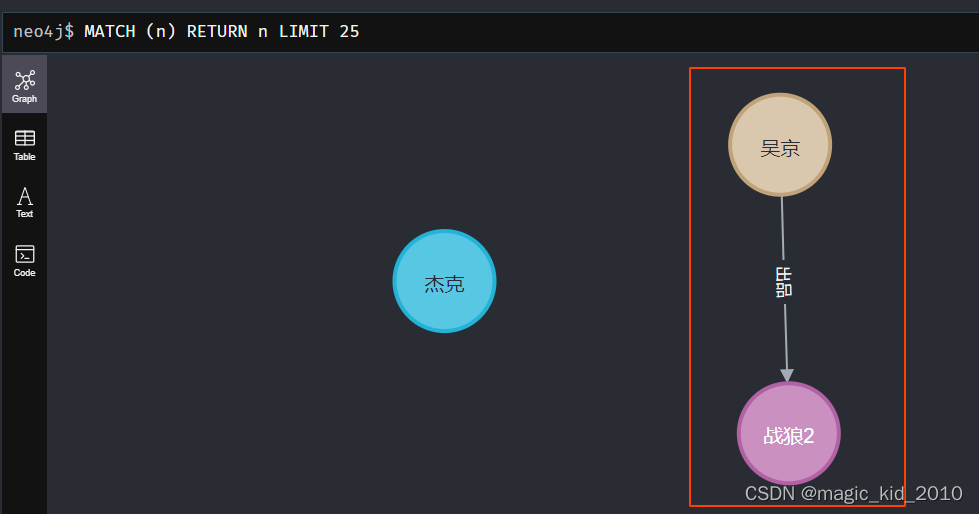
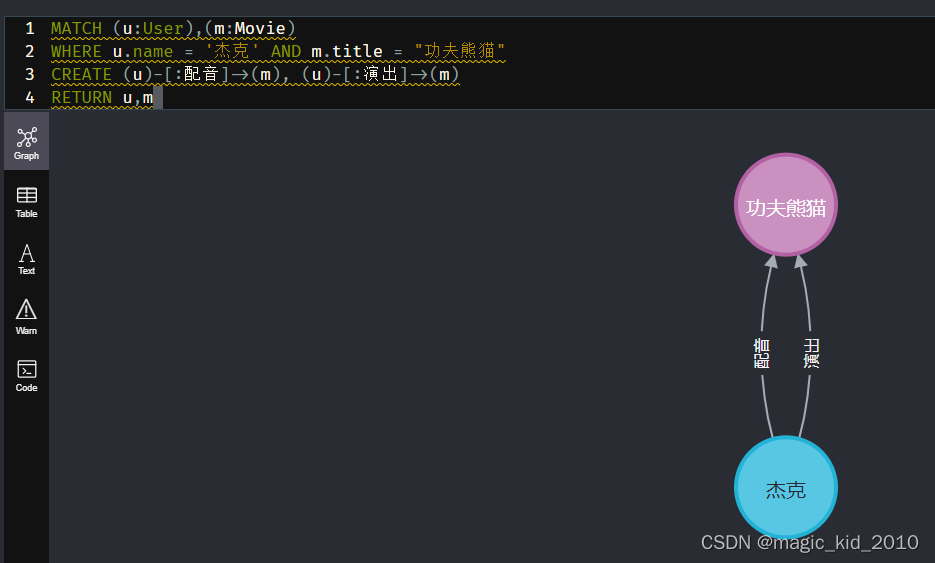
MATCH (u:User),(m:Movie)
WHERE u.name = '杰克' AND m.title = "功夫熊猫"
CREATE (u)-[:配音]->(m), (u)-[:演出]->(m)
RETURN u,m
 删除关系
删除关系
match (u:User {name: '杰克'}) - [r:配音] -> (m:Movie {title: '功夫熊猫'}) delete r return u,m
# r 表示 关系 的变量
修改关系
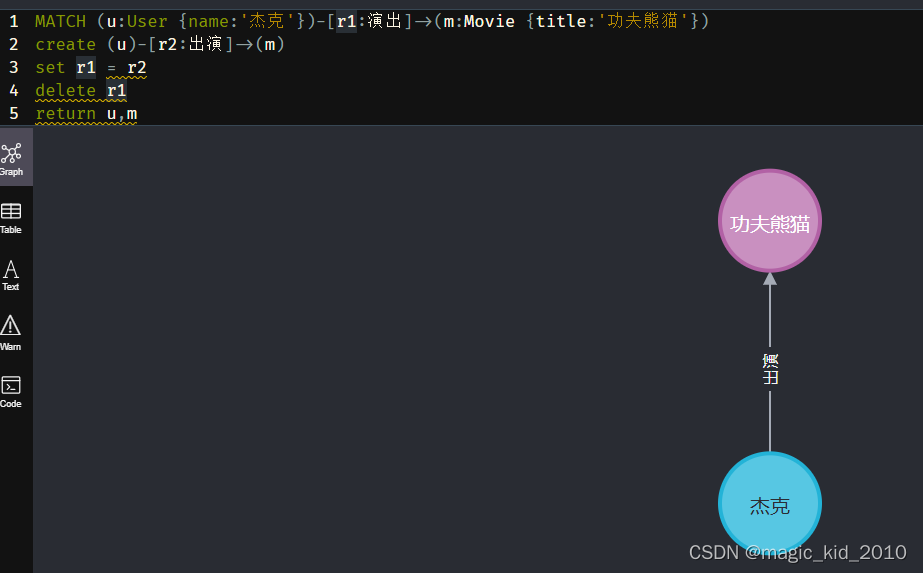
MATCH (u:User {name:'杰克'})-[r1:演出]->(m:Movie {title:'功夫熊猫'})
create (u)-[r2:出演]->(m)
set r1 = r2
delete r1
return u,m
# r1、r2 表示关系的变量
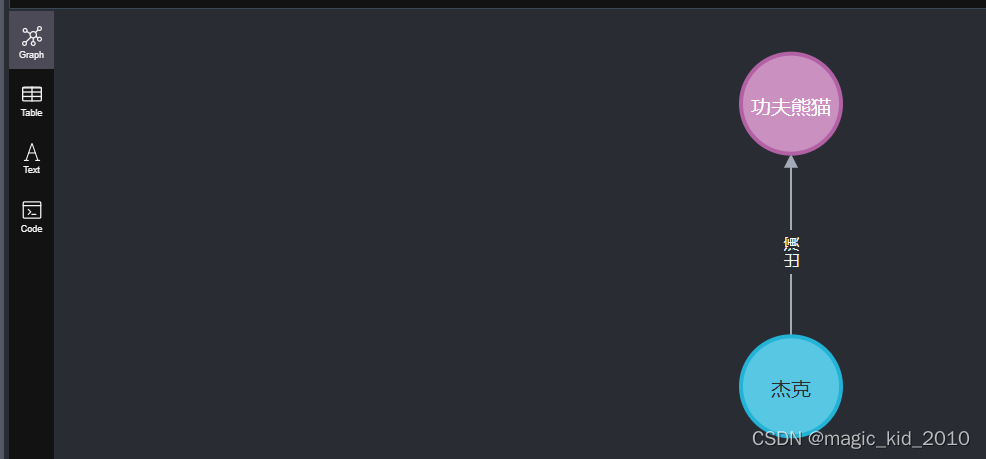
查询关系
MATCH (u:User {name:'杰克'})-[r1:出演]->(m:Movie {title:'功夫熊猫'}) return u,r1,m

模式(Patterns)
模式是用于定义节点和关系的结构和约束的规则集合。它描述了节点和关系的类型、属性以及它们之间的连接方式。
MATCH (u:User {name:'杰克'})-[r1:出演]->(m:Movie {title:'功夫熊猫'}) return u,r1,m图展示
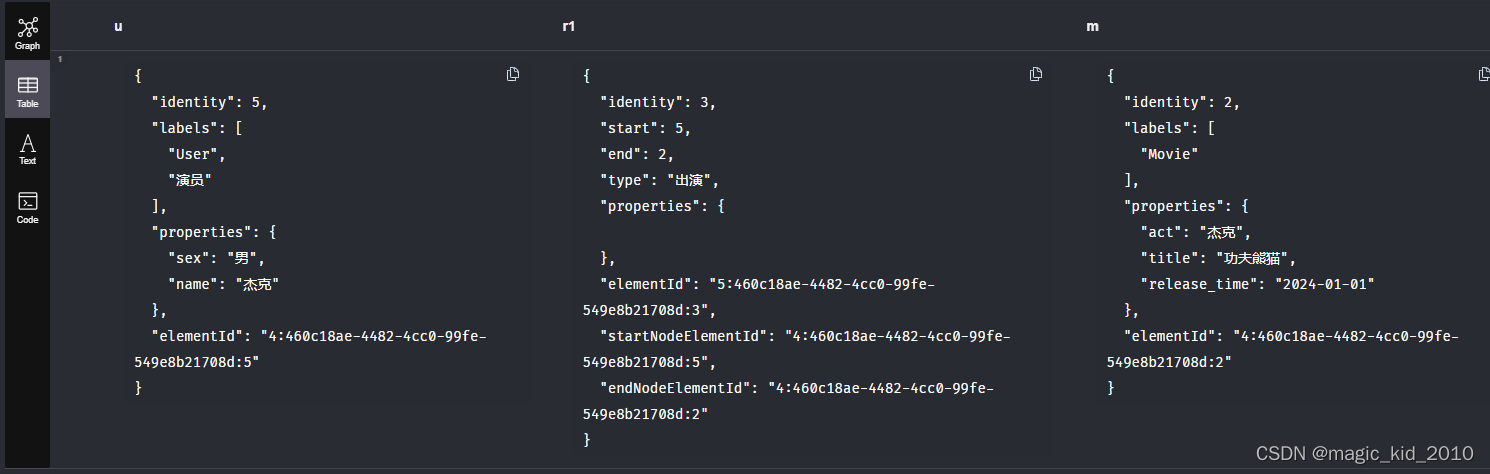
表格展示
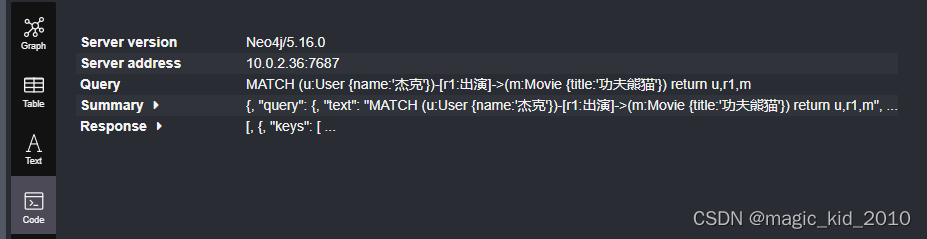
文本展示

代码展示
路径的表示
Cypher 中 节点-关系-节点 是最基础的路径,可以用()--()表示, 对于较长的路径,Cypher 中使用星号 *,数字和点号 . 来进行表示。
(a)-[*2]->(b) # 表示节点 a,节点 b 之间的路径长度为 2,等价于 (a)-->()-->(b)(a)-[*3..5]->(b) # 表示节点 a,节点 b 之间的最小路径长度为 3,最大为 5(a)-[*3..]->(b) # 表示节点 a,节点 b 之间的路径长度至少为 3(a)-[*..5]->(b) # 表示节点 a,节点 b 之间的路径长度至多为 5(a)-[*]->(b) # 表示节点 a,节点 b 之间的路径长度为任意这篇关于图数据库 之 Neo4j - Cypher语法基础(5)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





