本文主要是介绍从11g到19c,Oracle列转行函数listagg的增强史,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 构造测试表
本文中的示例依赖于以下测试表
CREATE TABLE emp (empno NUMBER(4) PRIMARY KEY,ename VARCHAR2(10),job VARCHAR2(9),mgr NUMBER(4),hiredate DATE,sal NUMBER(7,2),comm NUMBER(7,2),deptno NUMBER(2)
);INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO emp VALUES (7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO emp VALUES (7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO emp VALUES (7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
INSERT INTO emp VALUES (7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30);
INSERT INTO emp VALUES (7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30);
INSERT INTO emp VALUES (7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10);
INSERT INTO emp VALUES (7788,'SCOTT','ANALYST',7566,to_date('13-JUL-87','dd-mm-rr')-85,3000,NULL,20);
INSERT INTO emp VALUES (7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO emp VALUES (7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30);
INSERT INTO emp VALUES (7876,'ADAMS','CLERK',7788,to_date('13-JUL-87', 'dd-mm-rr')-51,1100,NULL,20);
INSERT INTO emp VALUES (7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30);
INSERT INTO emp VALUES (7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO emp VALUES (7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10);commit;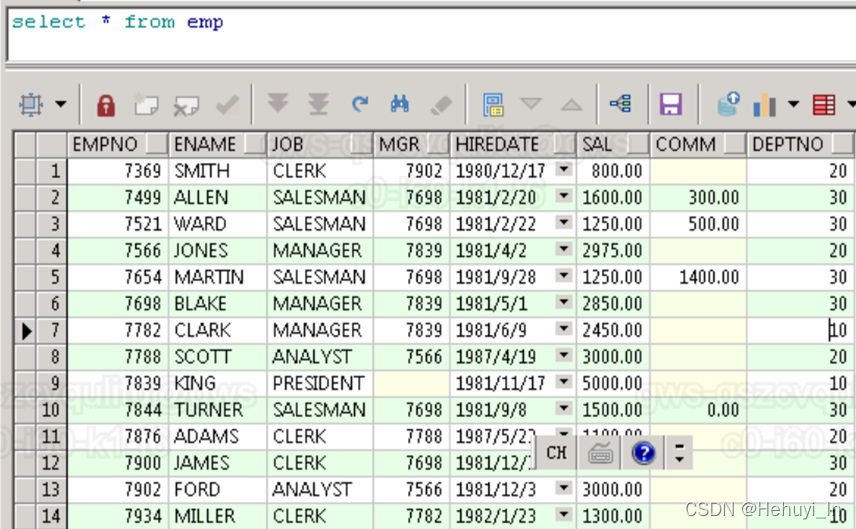
二、12.1以前
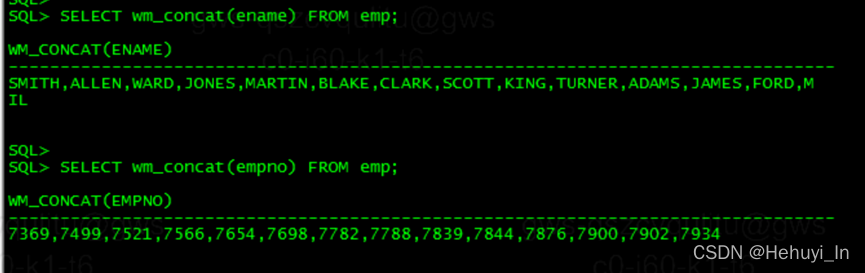
Oracle 12c之前有一个内部函数wm_concat,用法超级简单
SELECT wm_concat(ename) FROM emp;
用途是把原本应该按列显示的ename,合并到一行显示并且用逗号分隔开
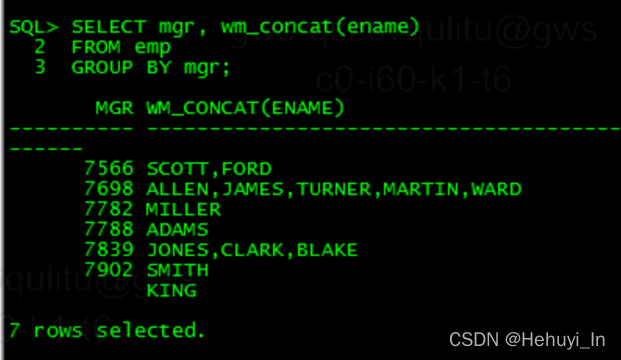
也可以分组合并,例如
SELECT mgr, wm_concat(ename)
FROM emp
GROUP BY mgr;
三、 12.1版本
1. 简单用法
从12.1开始,Oracle取消了wm_concat内部函数。其实11gR2开始,oracle就引入了listagg函数,固定语法如下:
LISTAGG(col_name, ',') WITHIN GROUP (ORDER BY col_name) 可以看到,它可以自己设置分隔符,还可以对分隔字段排序了。
我们也先来看一个最简单的用法
SELECT LISTAGG(ename, ',') WITHIN GROUP (ORDER BY ename) employees FROM emp;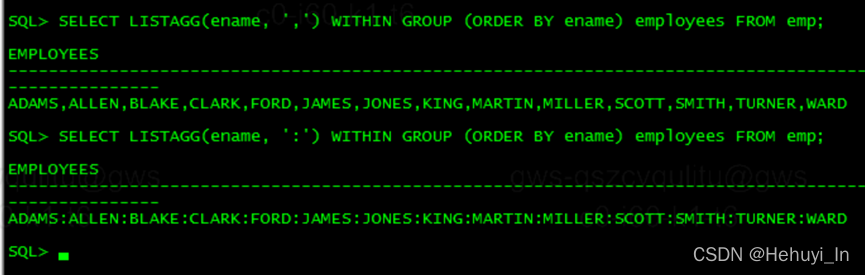
再试试前面的按分组合并
COLUMN employees FORMAT A40SELECT mgr, LISTAGG(ename, ',') WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
GROUP BY mgr;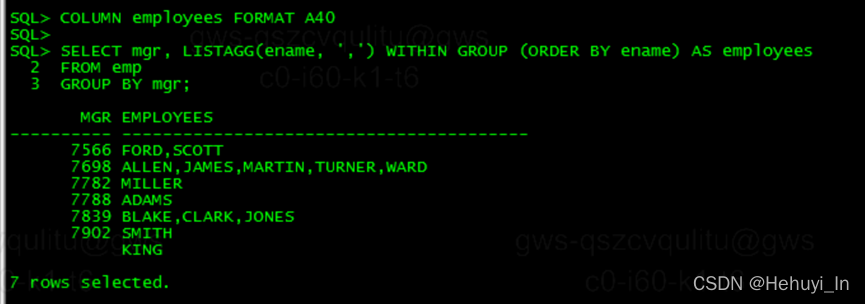
2. 字符串超长
不过listagg函数输出是有长度限制的(varchar2(4000)),超过该长度会收到报错 ORA-01489: result of string concatenation is too long
在以下示例中,我们使用CROSS JOIN来强制进行大型聚合。
COLUMN employees FORMAT A40
SELECT LISTAGG(ename, ',') WITHIN GROUP (ORDER BY ename) AS employees
FROM empCROSS JOIN (SELECT level FROM dual CONNECT BY level <= 100); -- emp 14行*100行=1400个ename合并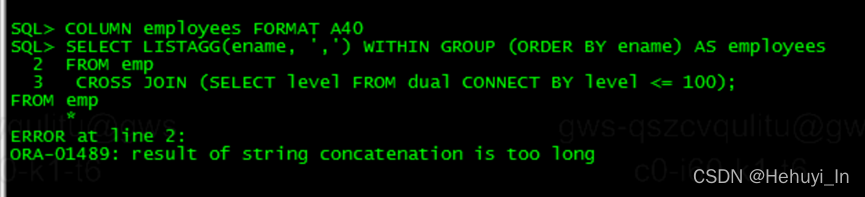
如果转换后的长度确实超过4000应该怎么办,网上找到了几种解决方法:
- 使用 xmlagg 函数
- 使用 stragg 函数
- 自己创建 PL/SQL 连接函数,并 returns type CLOB
3. 测试 xmlagg 函数
用法是:
rtrim(xmlagg(xmlelement(e,to_char(col_name),',').extract('//text()')
SELECT rtrim(xmlagg(xmlelement(e,ename,',').extract('//text()')))
FROM emp
CROSS JOIN (SELECT level FROM dual CONNECT BY level <= 100);这里遇到另一个问题,虽然合并后的字段可以超过4000长度了,但又遇到另一个报错,解决方法后面补充

三、 12.2版本
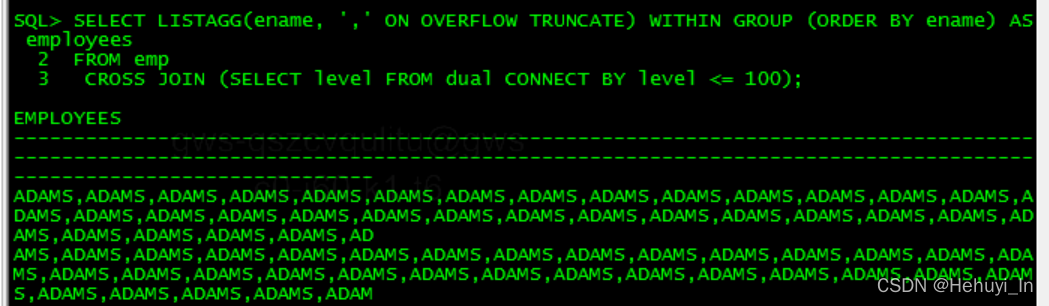
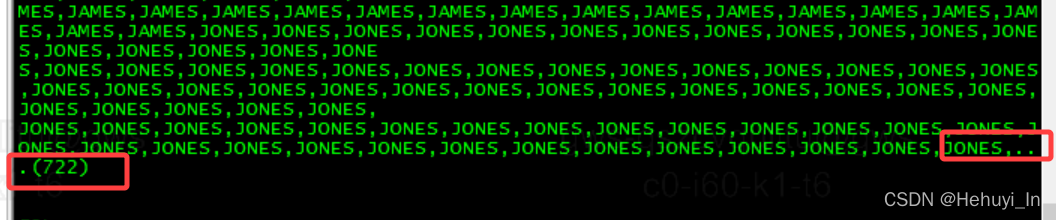
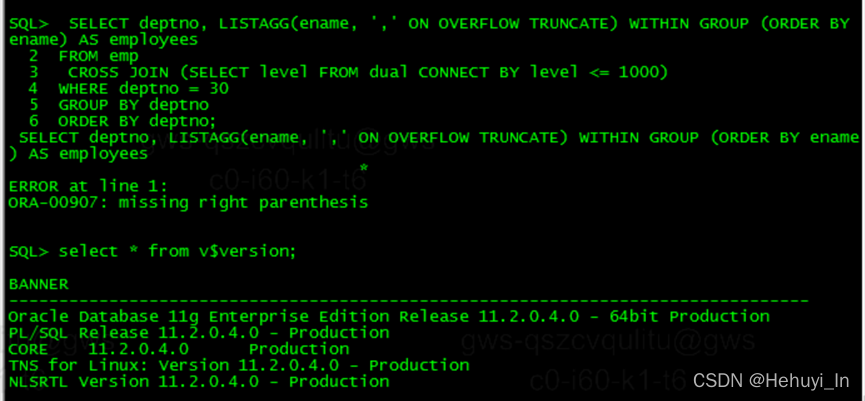
在12.2中,可以添加ON OVERFLOW TRUNCATE子句来优雅地处理溢出错误。默认情况下,truncate文字是省略号('...'),并包含溢出字符的计数。
COLUMN employees FORMAT A40
SELECT LISTAGG(ename, ',' ON OVERFLOW TRUNCATE) WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
CROSS JOIN (SELECT level FROM dual CONNECT BY level <= 100);
如果遇到缺少右括号的报错,说明数据库版本太低,识别不了这个语法
如果不想使用省略号,也可以指定自己的truncate文字。在下面的示例中,我们使用了 ~~~。
COLUMN employees FORMAT A40
SELECT LISTAGG(ename, ',' ON OVERFLOW TRUNCATE '~~~') WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
CROSS JOIN (SELECT level FROM dual CONNECT BY level <= 100);

也可以通过添加WITHOUT COUNT来省略计数,默认值相当于显式使用WITH COUNT。
COLUMN employees FORMAT A40
SELECT LISTAGG(ename, ',' ON OVERFLOW TRUNCATE '~~~' WITHOUT COUNT) WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
CROSS JOIN (SELECT level FROM dual CONNECT BY level <= 100);

四、 19c版本
1. LISTAGG DISTINCT
19c中,LISTAGG 增加了通过 distinct 关键字从结果中删除重复项的功能。
还是用上面那个示例表,我们在部门10中添加一些名为“MILLER”的额外人员,以便在聚合列表中为我们提供重复项。
INSERT INTO emp VALUES (9998,'MILLER','ANALYST',7782,to_date('23-1-1982','dd-mm-yyyy'),1600,NULL,10);
INSERT INTO emp VALUES (9999,'MILLER','MANADER',7782,to_date('23-1-1982','dd-mm-yyyy'),1500,NULL,10);
COMMIT;正如预期的那样,我们现在在部门10中看到多个名为“MILLER”的条目
COLUMN employees FORMAT A40
SELECT deptno, LISTAGG(ename, ',') WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
GROUP BY deptno
ORDER BY deptno;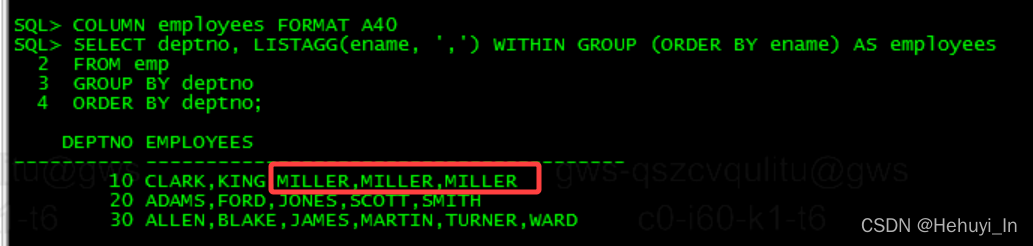
如果想删除重复项,我们该怎么办?
2. 解决方案:19c之前
需要我们手动去重,可以用分析函数或者distinct
法1:用ROW_NUMBER分析函数删除重复项,然后使用常规LISTAGG函数。
COLUMN employees FORMAT A40
SELECT e2.deptno, LISTAGG(e2.ename, ',') WITHIN GROUP (ORDER BY e2.ename) AS employees
FROM (SELECT e.*,ROW_NUMBER() OVER (PARTITION BY e.ename ORDER BY e.empno) AS myrank FROM emp e) e2
WHERE e2.myrank = 1
GROUP BY e2.deptno
ORDER BY e2.deptno;

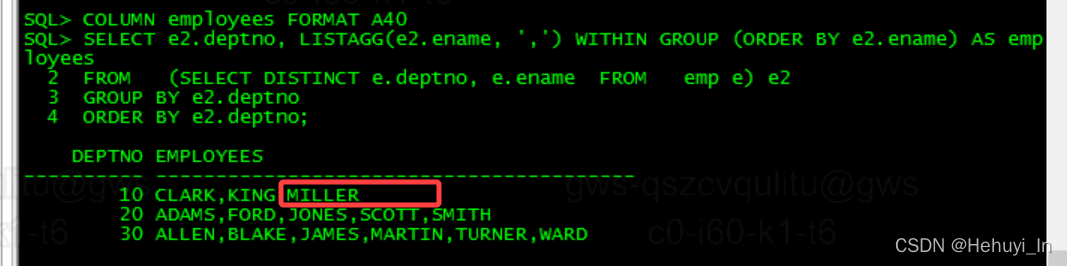
法2:用distinct在内联视图中去重,然后使用常规LISTAGG函数。
COLUMN employees FORMAT A40
SELECT e2.deptno, LISTAGG(e2.ename, ',') WITHIN GROUP (ORDER BY e2.ename) AS employees
FROM (SELECT DISTINCT e.deptno, e.ename FROM emp e) e2
GROUP BY e2.deptno
ORDER BY e2.deptno;
3. 解决方案:19c及之后
19c引入了一种更简单的解决方案,可以直接在listagg函数中包含distinct关键字。
SELECT deptno, LISTAGG(DISTINCT ename, ',') WITHIN GROUP (ORDER BY ename) AS employees
FROM emp
GROUP BY deptno
ORDER BY deptno;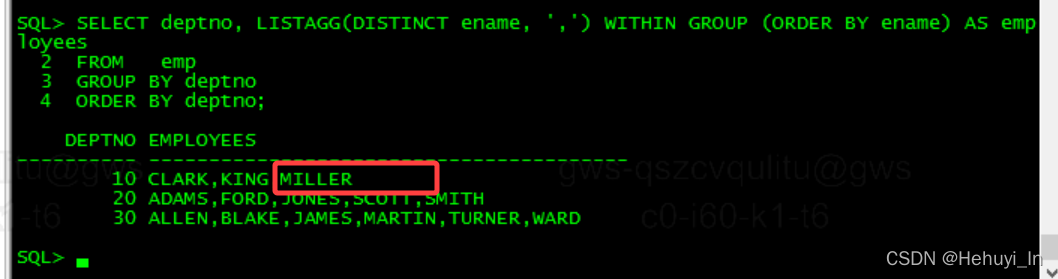
参考
ORACLE-BASE - LISTAGG Function Enhancements in Oracle Database 12c Release 2 (12.2)
ORACLE-BASE - LISTAGG DISTINCT in Oracle Database 19c
这篇关于从11g到19c,Oracle列转行函数listagg的增强史的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






