本文主要是介绍通过写代码学习AWS DynamoDB (3)- 一致性hash,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
在本文中,我们将简单介绍一致性hash(consistent hash)的概念,以及一致性hash可以解决的问题。然后我们将在模拟的DDB实现中实现一个简单版本的基于一致性harsh实现的partition。
问题
在《通过写代码学习AWS DynamoDB (2)》中我们的DDB使用了最朴素的hash算法来分配一个key/value存储的partition。也就是使用
key % <partition count>的方法。当我们需要改变partition的数量来达到scale out和scale in的目的时,我们发现使用这种方法算出来的新的partition会和之前的partition有很大的区别。例如,如果我们把partition的数量从10增加到11时,新分配的partition和以前分配的partition会如下表所示:
| Key | Existing Partition | New Partition |
| 1567 | 7 | 5 |
| 2354 | 4 | 0 |
| 2888 | 8 | 6 |
| 8971 | 1 | 6 |
Key所对应的partition的改变意味着我们需要把该partition的数据转移到新的partition上。这是一种很大的开销。而在partition数量改变时,一致性hash可以帮助我们减少数据所对应的partition发生改变的次数。
一致性hash介绍
一致性hash的介绍文章在网上很多,大家可以自行参看。这里仅仅做一个简单的介绍。首先,我们介绍下面几个和hash有关的概念:
Hash空间:Hash空间是指全部可能的hash key组成的空间。比如说,我的hash key是用“x % 1000”产生的,那么我的hash空间就是0到999,因为所有可能的hash key都处在这个范围内,并且这个空间的每一个值也都可能是一个hash key。
Hash key:Hash key是用hash函数产生的key。对于每一个需要映射到hash空间的对象都需要使用hash函数产生出一个hash key。
Hash server:这里Hash server是指将一个server或者host通过某种方法映射到Hash空间。比如,使用IP地址来进行映射。
下面的图描述了一个一致性hash的实现原理。

图中的A,B,C是3个hash server,它们已经被映射到了hash 空间上。Kate,John,Steve,Bill,和Jane是5个element,它们也被映射到了hash空间上。现在我们规定每一个element将被保存到与它相邻的前面的hash server中。这样,John,Steve被保存到C中,Bill被保存到B中,Kate和Jane被保存到A中。通过这种方式,我们可以看到如果需要增加或者减少Hash server,理论上只会有1/N的元素被移动到新的hash server里,N是全部hash server的数量。而一般性的hash实现方法几乎是全部数据需要被移动,所以这是一个很大的改进。
这种普通的consistent hash的实现仍然具有一些缺点。例如当我们分配element给hash server时,可能会出现非常不均匀的情况。某些hash server可能会保存比其它hash server多很多的element。这是我们试图避免的。所以,又产生了Virtual node的概念。如下图所示:

现在映射到hash空间的都是每一个hash server的virtual node。每一个hash server可以有很多的virtual node。比如图中每一个hash server有3个virtual node。现在每一个hash空间里的element是被分配到邻近的virtual node上,而通过virtual node又可以找到实际的hash server。通过将每一个hash server映射出多个virtual node的方式,我们可以大大减小element分配不均匀的问题。
实现一致性hash
我们在这里实现的是最基础的一致性hash,但是基于virtual node的实现本身也不复杂很多,只是多了一层virtual node到hash server的mapping。首先,我们将partition的管理从DDB.Table里移出来,并且定义了一个类Consistent_hash_manager,由它管理partition。这个类不仅提供了对key/value的增删改操作,同时提供了scale_out_partition()和scale_in_partition()两个操作。通过这两个操作我们可以增加和删除partition。这样DDB.Table就不再需要知道partition的细节,而仅仅需要通过Consistent_hash_manager的接口直接对数据和partition进行操作。修改之后的DDB和Consistent_hash_manager如下所示:
DDB 类的实现:
from consistent_hash_manager import Consistent_hash_manager# class to provide DDB public APIs
# - support partitions based on hash value of key;
class DDB:def __init__(self):self.tables = {}def create_table(self, table_name):self.tables[table_name] = self.Table(table_name)def list_table(self):for table in self.tables.values():table.describe()def delete_table(self, table_name):self.tables.pop(table_name)def get_table(self, table_name):return self.tables[table_name]class Table:def __init__(self, name, partition_count=1):self.name = nameself.consistent_hash_manager = Consistent_hash_manager(partition_count)def put_item(self, key, value):self.consistent_hash_manager.put_item(key, value)def update_item(self, key, value):self.consistent_hash_manager.put_item(key, value)def get_item(self, key):return self.consistent_hash_manager.get_item(key)def delete_item(self, key):self.consistent_hash_manager.delete_item(key)def describe(self):item_count = self.consistent_hash_manager.get_item_count()print("Table name: {}, item size: {}".format(self.name, item_count))def scale_out(self):self.consistent_hash_manager.scale_out_partition()def scale_in(self):self.consistent_hash_manager.scale_in_partition()Consistent_hash_manager的实现:
from random import randrange
import functoolsfrom partition import Partitionclass Consistent_hash_manager:def __init__(self, partition_count=3):self.hash_space = 10self.available_hash_keys = list(range(self.hash_space))self.partitions = list()for _ in range(partition_count):self.partitions.append(Partition(self.available_hash_keys[randrange(len(self.available_hash_keys))]));self.available_hash_keys.remove(self.partitions[-1].get_id())# sort by id so partitions build a consistent hash ringself.partitions.sort(key=lambda x : x.get_id())# add one partitiondef scale_out_partition(self):if len(self.available_hash_keys) == 0:print("No available hash space for scale out")returnself.partitions.append(Partition(self.available_hash_keys[randrange(len(self.available_hash_keys))]))self.available_hash_keys.remove(self.partitions[-1].get_id())print("scale out one new partition with ID {}".format(self.partitions[-1].get_id()))partition_key = self.partitions[-1].get_id()self.partitions.sort(key=lambda x : x.get_id())for i in range(len(self.partitions)):if self.partitions[i].get_id() == partition_key:new_partition = self.partitions[i]if i + 1 < len(self.partitions):next_partition = self.partitions[i+1]else:next_partition = self.partitions[0]breakprint("move elements from the next partition to the new partition")for key in next_partition.get_items():partition = self.get_partition(key)if partition == new_partition:print("move {} from partition {} to {}".format(key, next_partition.get_id(), new_partition.get_id()))new_partition.put_item(key, next_partition.get_items()[key])for key in new_partition.get_items():next_partition.delete_item(key)# remove one partitiondef scale_in_partition(self):if len(self.partitions) == 1:print("Only one partition now. Cannot delete")returndeleted_partition_index = randrange(len(self.partitions))deleted_partition = self.partitions[deleted_partition_index]if deleted_partition_index == len(self.partitions) - 1:next_partition = self.partitions[0]else:next_partition = self.partitions[deleted_partition_index + 1]print("Delete partition with ID {}. Move elements from the deleted partition to the next partition.".format(deleted_partition.get_id()))for key,value in deleted_partition.get_items().items():print("move {} from partition {} to {}".format(key, deleted_partition.get_id(), next_partition.get_id()))next_partition.put_item(key, value)self.available_hash_keys.append(deleted_partition.get_id())del(self.partitions[deleted_partition_index])def put_item(self, key, value):partition = self.get_partition(key)print("save {} to partition {}".format(key, partition.get_id()))partition.put_item(key, value)def get_item(self, key):partition = self.get_partition(key)print("get {} from partition {}".format(key, partition.get_id()))return partition.get_item(key)def delete_item(self, key):partition = self.get_partition(key)print("delete {} from partition {}".format(key, partition.get_id()))partition.delete_item(key)def get_item_count(self):return functools.reduce(lambda x, y : x + y.get_item_count(), self.partitions, 0) def get_hash_key(self, key):return self.my_hash(key) % self.hash_spacedef my_hash(self, text:str):hash=0for ch in text:hash = ( hash*281 ^ ord(ch)*997) & 0xFFFFFFFFreturn hashdef get_partition(self, key):hash_key = self.get_hash_key(key)if len(self.partitions) == 1 or hash_key <= self.partitions[0].get_id() or hash_key > self.partitions[-1].get_id() :return self.partitions[0]left = self.partitions[0].get_id()for partition in self.partitions[1:]:if hash_key <= partition.get_id() and hash_key > left:return partitionleft = partition.get_id()return None
现在我们使用下面的代码对我们的DDB和Consistent_hash_manager进行测试:
from ddb import DDBddb = DDB()table_name = "test_table"ddb.create_table(table_name)
ddb.list_table()
ddb_table = ddb.get_table(table_name)
ddb_table.put_item("a", "value_of_a")
ddb_table.put_item("b", "value_of_b")
ddb_table.put_item("c", "value_of_c")
ddb_table.put_item("d", "value_of_d")ddb_table.scale_out()print(ddb_table.get_item("a"))
print(ddb_table.get_item("b"))
print(ddb_table.get_item("c"))
print(ddb_table.get_item("d"))ddb_table.scale_in()ddb_table.delete_item("a")ddb_table.describe()我们首先创建了一个DDB表,表的默认partition只有一个。然后向其中插入了4个key/value,key分别是"a", "b", "c", "d"。然后我们给该表增加一个partition,此时我们应该会看到某些key/value被移动到新的partition里。然后我们查询key,观察它们是否是从正确的partition里查询的。然后我们删除掉一个partition,并且删除掉一个key,此时我们会发现有些数据会从被删除的partition移动到其它的partition里。最后我们查询一下目前表中key/value的数量。
我们测试结果如下:
# 创建表
Table name: test_table, item size: 0# 添加key/value到partition 9中
save a to partition 9
save b to partition 9
save c to partition 9
save d to partition 9# scale out一个partition 7
scale out one new partition with ID 7# 三条数据被移动到新的partition里
move elements from the next partition to the new partition
move b from partition 9 to 7
move c from partition 9 to 7
move d from partition 9 to 7# 读取key并且验证它们是从正确的partition中读取的
get a from partition 9
value_of_a
get b from partition 7
value_of_b
get c from partition 7
value_of_c
get d from partition 7
value_of_d# scale in一个partition 9. partition 9里的数据被移动到partition 7里.
Delete partition with ID 9. Move elements from the deleted partition to the next partition.
move a from partition 9 to 7# 删除一个key.并且查询目前表中key的数量.
delete a from partition 7
Table name: test_table, item size: 3
问题扩展
首先大家可以尝试在现在的实现基础上实现virtual node。我们在这里讨论另一个问题。如果我们有很多的partition,现在我们有一个key,我们如何快速的找到它对应的hash server(或者virtual node)呢?在我们目前的实现里我们是线性查找的,时间复杂度是O(n)。我们可以考虑使用二叉搜索树(binary search tree)来改善时间复杂度。二叉搜索树是一种二叉树,每一个node的左孩子节点的value都小于它,右孩子节点的value都大于它。这样我们搜索的效率就可以改善为O(lg(n))。
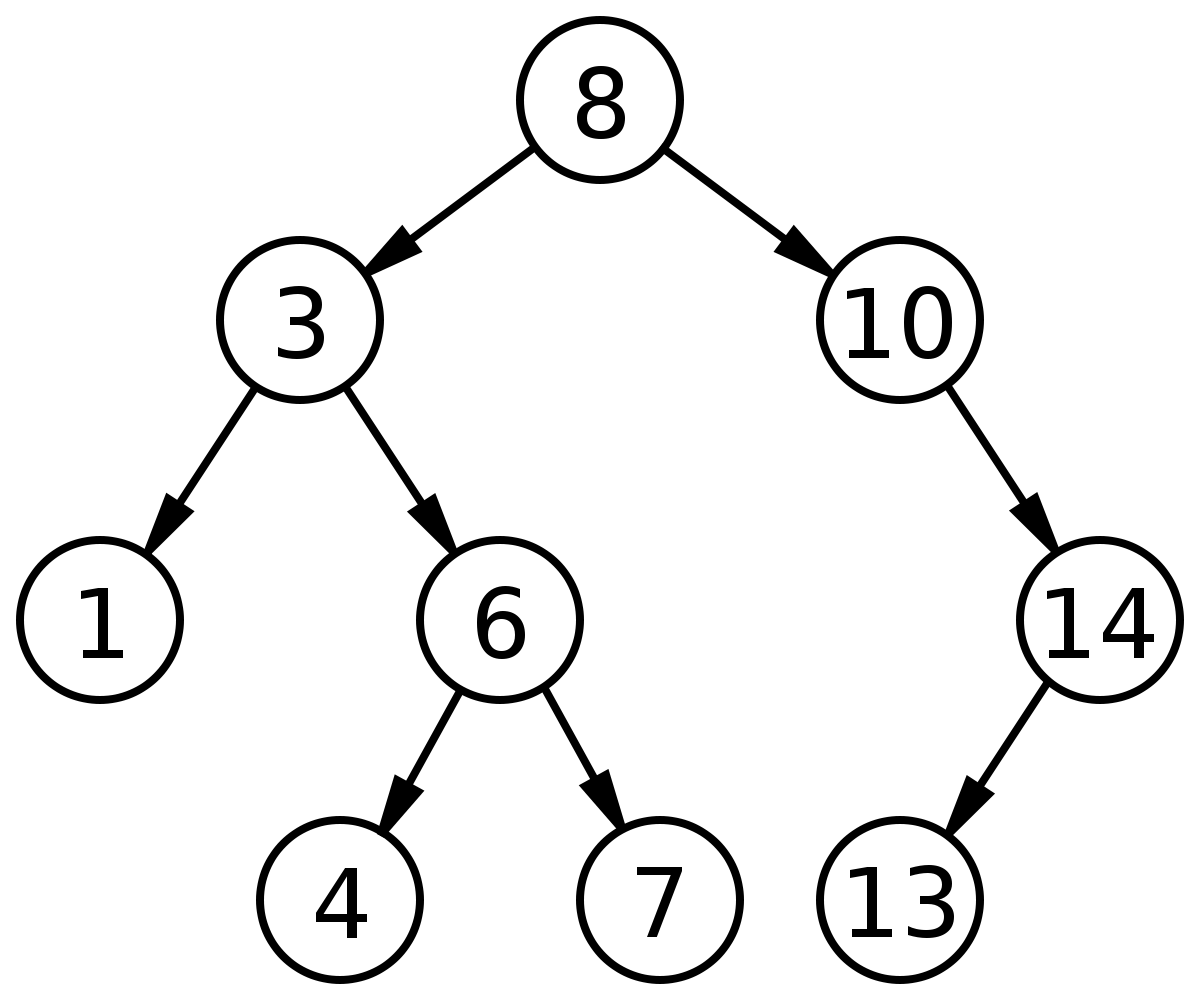
其次,我们还应该想到真正的产品实现会比我们的实现复杂的多。每一次scale out和scale in的操作都需要同步来保证数据的增删改读的可用性和正确性。
这篇关于通过写代码学习AWS DynamoDB (3)- 一致性hash的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





