本文主要是介绍下一代模型:Gemini 1.5,正如它的名字一样闪亮登场,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

上周,Google推出了其迄今为止最强大的模型——Gemini 1.0 Ultra,标志着其产品,尤其是Gemini Advanced变得更加有用的重要一步。从今天起,开发者和云客户也可以开始使用1.0 Ultra——通过AI Studio和Vertex AI中的Gemini API进行构建。
Google的团队继续推动最新模型的前沿,将安全性放在核心位置,并取得了迅速的进展。事实上,他们已准备好介绍下一代模型:Gemini 1.5。它在多个维度上展现出显著的改进,1.5 Pro在使用更少的计算资源的同时,达到了与1.0 Ultra相当的质量。
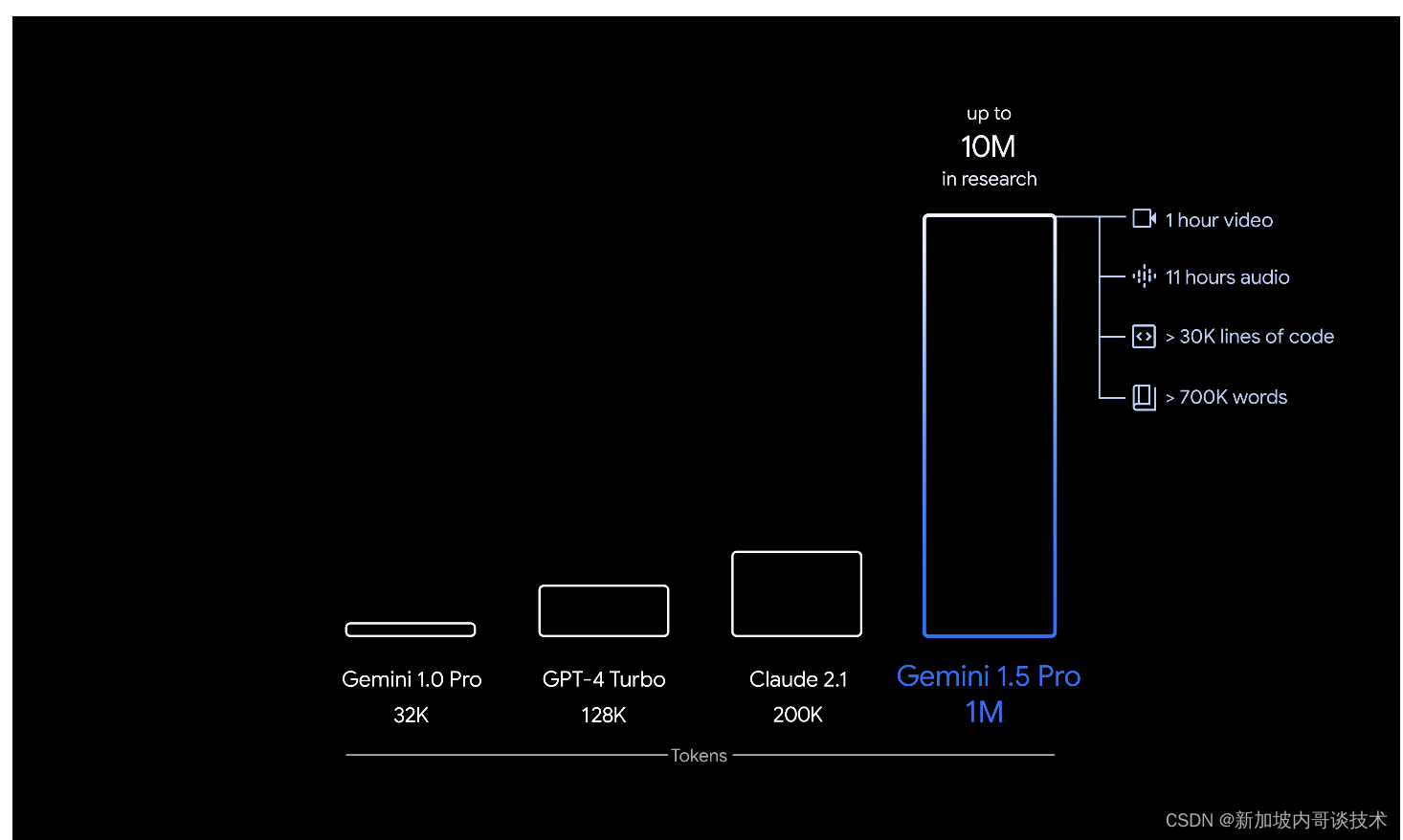
这一新一代还实现了在长文本理解上的突破。Google已经显著增加了其模型可以处理的信息量——稳定运行高达100万个令牌,实现了迄今为止任何大规模基础模型中最长的上下文窗口。更长的上下文窗口展示了可能性的承诺,将使得全新的能力成为可能,并帮助开发者构建更多有用的模型和应用程序。Google对开发者和企业客户提供这一实验功能的有限预览感到兴奋。Demis分享了更多关于能力、安全性和可用性的信息。
由Google DeepMind的CEO Demis Hassabis代表双子团队介绍Gemini 1.5:这是人工智能领域令人激动的时刻。领域内的新进展有潜力在未来几年为数十亿人提供更多帮助。自从引入Gemini 1.0以来,Google一直在测试、完善和增强其能力。今天,Google宣布了下一代模型:Gemini 1.5。Gemini 1.5带来了显著提升的性能。它代表了Google方法的一个重大变化,建立在几乎每一个部分的研究和工程创新之上,这包括使Gemini 1.5更加高效的训练和服务,采用了新的专家混合(MoE)架构。
Google正在为早期测试发布的第一个Gemini 1.5模型是Gemini 1.5 Pro。这是一个中等大小的多模态模型,为跨广泛任务的扩展进行了优化,并且与迄今为止最大的模型1.0 Ultra表现在相似的水平。它还引入了在长文本理解上的实验性突破特性。Gemini 1.5 Pro配备了标准的128,000令牌上下文窗口。但从今天起,一小部分开发者和企业客户可以通过AI Studio和Vertex AI在私密预览中尝试高达100万令牌的上下文窗口。
随着Google全面推出100万令牌上下文窗口,他们正在积极工作以改善延迟、降低计算需求并增强用户体验。Google对人们尝试这一突破性能力感到兴奋,并在下方分享了更多关于未来可用性的详细信息。这些在下一代模型中的持续进步将为人们、开发者和企业开启使用人工智能创建、发现和构建的新可能性。
Gemini 1.5基于Google在Transformer和MoE架构上的领先研究。而传统的Transformer作为一个大型神经网络运行,MoE模型被划分为较小的“专家”神经网络。根据给定的输入类型,MoE模型学会只激活其神经网络中最相关的专家路径。这种专业化大大提高了模型的效率。Google是通过诸如Sparsely-Gated MoE、GShard-Transformer、Switch-Transformer、M4等研究,成为深度学习中MoE技术的早期采用者和先锋。
Google的最新模型架构创新使Gemini 1.5能够更快地学习复杂任务并保持质量,同时训练和服务更加高效。这些效率帮助Google的团队比以往任何时候都更快地迭代、训练和交付更高级的Gemini版本,并且他们正在进行进一步的优化。作为大规模模型中首创的长上下文窗口,Google正在不断开发新的评估和基准测试来测试其新颖能力。遵循AI原则和严格的安全政策,Google确保其模型经过广泛的伦理和安全测试。然后,将这些研究成果整合到其治理过程、模型开发和评估中,以持续改进其AI系统。
自从去年12月引入1.0 Ultra以来,Google的团队继续对模型进行精炼,使其对更广泛的发布更安全。他们还进行了关于安全风险的新研究,并开发了红队技术来测试一系列潜在的危害。在发布1.5 Pro之前,Google采取了与其Gemini 1.0模型相同的负责任部署方式,进行了包括内容安全和代表性伤害在内的广泛评估,并将继续扩大这种测试。此外,Google正在开发进一步的测试,以考虑1.5 Pro的新长上下文能力。Google致力于负责任地将每一代Gemini模型带给全球数十亿人、开发者和企业。
从今天开始,Google通过AI Studio和Vertex AI向开发者和企业客户提供1.5 Pro的有限预览。更多信息请参阅Google开发者博客和Google Cloud博客。当模型准备好进行更广泛发布时,Google将引入标准的128,000令牌上下文窗口的1.5 Pro。不久,Google计划引入从标准的128,000上下文窗口开始并扩展到100万令牌的定价等级,随着模型的改进。在测试期间,早期测试者可以免费尝试100万令牌上下文窗口,尽管他们应该预期这一实验性功能会有较长的延迟时间。速度的显著改进也即将到来。
有兴趣测试1.5 Pro的开发者现在可以在AI Studio注册 (https://aistudio.google.com/app/waitlist/97445851),而企业客户可以联系他们的Vertex AI账户团队。
这篇关于下一代模型:Gemini 1.5,正如它的名字一样闪亮登场的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









