本文主要是介绍【知识整理】产研中心岗位评定标准之大数据岗位,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为贯彻执行集团数字化转型的需要,该知识库将公示集团组织内各产研团队不同角色成员的职务“职级”岗位的评定标准;

一、定级定档目的
通过对公司现有岗位及相应岗位员工的工作能力、工作水平进行客观公正评定,确定各岗位的等级及同等级岗位员工对应的档级,从而为员工以后的晋升、奖励、收入等提供目标、依据和标准,实现人力资源的优化配置。
二、定级定档说明
定级定档是体现岗位及员工价值的有效途径。不同岗位角色所需专业知识、技能不同对实现公司目标的影响也不同。而不同员工的工作经验、能力和创造的价值也不同;因此,通过不同角色对应不同档级,以体现不同员工的价值。本次面向人群集团产研团队,以及外包成员。

三、序列说明
1.集团职级体系按照职能性质分为产品序列和技术序列
2.根据个人能力进行P序列划分,具体范围为P4-P9
3.技术序列细分为
服务端、前端研发、产品经理、基础技术(运维部)、产研测试
四、能力模型
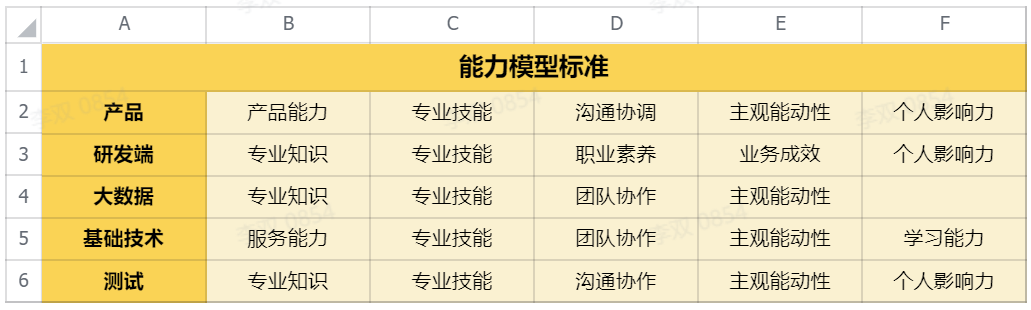
下面针对技术研发端进行详细说明:
1. 模型概要
目标:
- 技术评级的标准,构建技术成员发展路径,能够对照标准,不断审视自身成长,重点突破自身瓶颈。
基本原则:
- 技术评级,既是科学工作,也是艺术
- 尽最大可能地客观评价技术人员的能力,认可他们的能力,同时,也要为其所处的发展阶段,给出诚恳的建议和引导
- 评定工作,要尽可能的客观,但,不可否认,无法做到百分百的绝对客观,可能会有小概率的偏差
- 出现小概率偏差,被评审人员,可以提起重新评审申请
- 关键岗位:需要组织现场答辩、宁缺勿滥
2. 技术评级的标准(草稿)
专业知识
基础知识
P4(了解)
1、掌握Java/Scala/Python编程语言的一种
2、能使用hadoop、spark、flink、hive、Impala、hbase等大数据生态组件中的1种及以上
3、了解Linux系统,具备shell脚本,ETL调度等开发
大数据仓库方向:
1、sql脚本基础知识扎实,至少熟悉mysql,oracle,hive其中一种数据库
2、具有一定基本数据处理能力
3、了解数据仓库知识
大数据分析挖掘方向:
了解各类机器学习算法或了解深度学习算法。
P5(掌握)
1、熟练掌握Java/Scala/Python编程语言的一种
2、能使用hadoop、spark、flink、hive、Impala、hbase等大数据生态组件中的2种及以上熟练掌握2种及以上组件
3、熟悉Linux系统,熟悉shell脚本,ETL调度等开发
大数据仓库方向:
1、sql脚本基础知识扎实,至少熟悉mysql,oracle,hive其中一种数据库,熟悉大数据处理流程
2、能够完成基本数据处理,独立完成非复杂型任务
3、熟悉数据仓库的基础知识,并能够简单应用
大数据分析挖掘方向:
1、至少熟悉机器学习、深度学习、算机视觉算法中的一类或多类
2、理解机器学习或深度学习的基础理论;
3、编码基础扎实,会使用python、R或C++编程语言。
P6(熟练)
1、熟练掌握Java/Scala/Python编程语言的一种,了解一门其它语言
2、能使用hadoop、spark、flink、hive、Impala、hbase等大数据生态组件中的3种及以上熟练掌握3种及以上组件
3、熟悉Linux系统,熟悉shell脚本,ETL调度等开发
大数据仓库方向:
1、sql脚本基础知识扎实,至少熟悉mysql,oracle,hive其中一种数据库,掌握大数据处理能力
2、熟悉数据仓库理论,数据清洗、数仓建模、业务数据分析与探索
3、具备复杂业务需求梳理能力,完成数据指标统计和多维分析,并落地实现
4、具备shell、python等脚本开发能力(加分项)
大数据分析挖掘方向:
1、理解机器学习或深度学习等相关知识;
2、了解模型量化、模型压缩、模型转换的方法和理论;
3、熟悉各类算法的相对优缺点;
4、编码基础扎实,会使用R、C++、Python等2种以上的编程语言。
5、能利用相关算法解决项目问题
P7(精通)
1、精通掌握Java/Scala/Python编程语言的一种,熟悉一门其它语言
2、熟悉hadoop、spark、flink、hive、Impala、hbase等大数据生态组件中的4种及以上,熟练掌握4种及以上组件
3、精通Linux系统,熟悉shell脚本,ETL调度等开发
4、承担解决部分突发疑难问题
大数据仓库方向:
1、sql脚本基础知识扎实,至少熟悉mysql,oracle,hive其中一种数据库,精通大数据处理
2、熟悉数据仓库理论,掌握数据仓库分层设计以及开发模式,维度建模;熟悉模型建模,能进行维度建模开发以及部署
3、具备复杂业务需求梳理能力,完成数据指标统计和多维分析,能够快速落地实现
4、具备shell、python等脚本开发能力(加分项)
5、参与构建海量数据下围绕质量、安全、效率等方向的数据仓库建设和数据管理
大数据分析挖掘方向:
1、熟练掌握机器学习、深度学习的基础理论和方法;
2、熟悉模型量化、模型压缩、模型转换、模型部署等;
3、具有实时跟进与机器学习相关领域的研究趋势的学习能力;
4、精通掌握C++、python等2种以上的编程语言。
5、能用算法解决复杂的问题,熟练模型部署、维护;
P8(全局)
1、精通掌握Java/Scala/Python编程语言的三种
2、精通hadoop、spark、flink、hive、Impala、hbase等大数据生态组件中的4种及以上,熟练掌握4种及以上组件
3、精通Linux系统,熟悉shell脚本,ETL调度等开发
4、主要承担解决突发疑难问题,并做好规划方案
大数据仓库方向:
1、sql脚本基础知识扎实,至少熟悉mysql,oracle,hive其中一种数据库,精通大数据处理
2、精通数据仓库理论,精通数据仓库分层设计以及开发模式,维度建模;熟悉模型建模,能进行维度建模开发以及部署
3、精通复杂业务需求分解及设计,能够带领团队快速实现
4、具备shell、python等脚本开发能力
5、具备独立构建海量数据下围绕质量、安全、效率等方向的数据仓库建设和数据管理能力
大数据分析挖掘方向:
1、对深度学习有深刻的理解,进行过检测、分割、深度评估等相关算法研究;数据结构等专业基础扎实
2、掌握深度学习模型量化、模型压缩等算法实施技巧;
3、编码基础扎实,熟悉Python、C++等至少一门编程语言;
4、对网络结构设计、训练、大规模数据处理有丰富的实践经验;
5、能用算法解决复杂的问题,跟进该领域新技术。
6、丰富的模型部署、维护等相关经验。
服务器知识
P4(了解)
操作系统基础扎实
P5(掌握)
熟悉并使用过基本的Linux命令
P6(熟练)
1、熟悉并使用过基本的linux命令;
2、熟悉Liinux上基本服务的安装和配置;
P7(精通)
1、熟悉并使用过基本的linux命令;
2、熟悉Linux服务的安装和配置以及优化
P8(全局)
1、熟悉并使用过基本的linux命令;
2、熟悉Linux服务的安装和配置以及优化
3、熟悉Linux集群服务的安装和配置及优化
数据库知识(大数据分析挖掘方向)
P4(了解)
数据库原理基础扎实,了解大数据相关的数据库原理知识
P5(掌握)
1、理解大数据相关的数据库基本原理,熟练掌握数据库原理
2、能根据业务目标设计出数据库的表结构和索引大数据应用方向:
3、掌握ES/HBase/Redis等存储引擎其中一种或多种大数据仓库方向:
4、熟悉SQL优化;
P6(熟练)
1、数据库基础扎实(增删改查、各字段类型、权限控制、事务控制),熟悉大数据相关的数据库基础知识
2、能根据业务目标设计出数据库的表结构和索引,大数据应用方向:
3、熟悉大数据流程调度;
4、熟悉SQI,NoSQL,DSL其中一种及以上
大数据仓库方向:
5、掌握SQL优化技巧;
P7(精通)
1、精通数据库基础(增删改查、各字段类型、权限控制、事务控制),精通大数据相关的数据库基础知识
2、精通数据库分布式、备份、恢复原理
3、对流行的NoSQL数据库、列式数据库、图数据库等有一定了解;
4、熟练根据业务目标设计出数据库的表结构和索引;
大数据应用方向:
5、精通大数据流程调度;
6、精通SQI,NoSQL,DSL其中二种语言及以上
7、精通2种以上及的数据库调优能力
8、具备一定能力的复杂应用场景的数据设计能力
数据仓库方向:
9、精通数据库优化,包括SQL优化、索引及其他优化手段;
P8(全局)
1、精通数据库基础(增删改查、各字段类型、权限控制、事务控制),精通大数据相关的数据库基础知识
2、精通SQL优化;
3、精通数据库分布式、备份、恢复原理
4、掌握流行的NoSQL数据库、列式数据库、图数据库等
5、精通传统数据仓库或hadoop类数据库至少一类数据库
6、精通根据业务目标设计出高性能的数据库的表结构和索引
大数据应用方向:
7、精通大数据流程调度;
8、精通SQI,NOSQL,DSL其中三种语言及以上
9、精通3种以上及的数据库调优能力
10、具体复杂应用场景的数据设计能力
数据处理及分析(仅大数据分析挖掘方向)
P4(了解)
会简单的数据查询、数据提取、数据处理
P5(掌握)
1、熟练的提取数据、数据处理
2、能够应用统计分析方法分析数据
P6(熟练)
1、熟练的提取数据、数据处理
2、掌握常用的数据分析方法,对数据进行深层分析
P7(精通)
1、熟练的提取数据、数据处理
2、掌握更多的数据分析方法,对数据进行深层的综合分析
P8(全局)
1、熟练的提取数据、数据处理
2、具备完整的数据分析体系建设能力,对多维度数据进行综合分析
项目经验
P4(了解)
P5(掌握)
有参与过项目并能讲清楚自己做的项
P6(熟练)
1、有一定的项目经验,承担开发工作,能画清流程图,并且了解技术细节,有想法,能对目前项目提出一些改进意见,有过性能优化or项目重构经验
2、参与大数据应用项目,熟悉大数据离线、实时处理
大数据仓库方向:
3、有一定的项目经验,并且参与数据仓库建设,优化基础数据架构,并且了解技术细节,有自主想法。
大数据分析挖掘方向:
4、有一定的项目经验,承担主要模块的开发工作,并且了解技术细节,有自主想法.
P7(精通)
1、较丰富的项目经验,并且对项目进行设计和任务分解,能画清流程图,并且了解技术细节,有想法,能对目前项目提出一些改进意见,有过性能优化or业务重构经验
2、主要参与大数据平台建设项目,熟悉实时流处理、数据etl处理、数据建模理论,对平台建设有一定的见解和把控能力
大数据仓库方向:
3、有较丰富的的项目经验,并且承担数据仓库建设,在海量数据下,确保数据质量,安全,效率等,并且有丰富的性能优化实战,能够对项目提出建设性意见或建议
大数据分析挖掘方向:
4、有较丰富的项目经验,承担主要模块的开发工作,并且熟悉技术细节,能对目前项目提出一些改进意见,具有需求分析、建模等能力。
P8(全局)
1、丰富的项目经验,并且对项目进行设计和任务分解,带领团队成员承担开发工作,能画清流程图,并且掌握技术细节,有想法,能对目前项目有深入的理解,有丰富的性能优化or业务重构经验
2、主导过大数据平台建设项目,对大数据开发工作有深刻理解,熟悉实时流处理、数据etl处理、数据建模理论,对平台建设有较深的见解和把控能力
大数据仓库方向:
3、有丰富的项目经验,能够对复杂数据仓库建设项目进行设计和任务分解,带领团队成员完成开发工作,精通性能优化,并和、和其他团队的工程师协同制定相关策略
大数据分析挖掘方向:
4、有丰富的项目经验,并且对复杂项目进行设计和任务分解,带领团队成员完成开发工作,精通技术细节,主导和推进项目,有过性能优化或重构经验.

专业技能
编码规范
P4(了解)
在团队成员指导下能够按照团队的编码规范编写代码
P5(掌握)
1、能够按照团队的编码规范编写代码
2、对自己编写的代码进行测试
P6(熟练)
1、能够按照团队的编码规范编写代码
2、对自己编写的代码进行测试
3、给予同事技术和编码规范的指导
4、有自己的编程思想,能够整体编写可维护性高的脚本
5、能够承担开发工作中较重要的部分,并且有较好的设计和高效的实现
P7(精通)
1、能够按照团队的编码规范编写代码
2、对自己编写的代码进行测试
3、给予同事技术和编码规范的指导
4、有自己的编程思想,能够整体编写可维护性高的脚本
5、能够承担开发工作中较重要的部分,并且有较好的设计和高效的实现
6、能够性能优化,减少重复代码和低效代码
P8(全局)
1、能够按照团队的编码规范编写代码
2、对自己编写的代码进行测试
3、给予同事技术和编码规范的指导
4、有自己的编程思想,能够整体编写可维护性高的脚本
5、能够作为项目总体负责人,承担主持项目的整体工作并负责核心业务的实现,有优秀的设计和高效的实现
6、能够性能优化,搭建小范围架构,减少重复代码和低效代码
开发工具
P4(了解)
能够使用1种IDE或ETL工具
P5(掌握)
1、熟练使用数据库工具
2、熟练使用1种及以上当前流程的IDE或ETL工具
P6(熟练)
1、熟练使用数据库工具
2、熟练使用1种及以上IDE或ETL工具
3、熟练使用项目中使用的其他客户端工具
P7(精通)
1、熟练使用数据库工具
2、熟练使用1种及以上IDE或ETL工具
3、熟练使用项目中使用的其他客户端工
4、掌握各种工具的使用,用于提高项目的开发和运行效率(包括监控、优化等工具)
P8(全局)
1、熟练使用数据库工具
2、熟练使用1种及以上IDE或ETL工具
3、熟练使用项目中使用的其他客户端工具
4、掌握各种工具的使用,用于提高项目的开发和运行效率(包括监控、优化等工具)
5、熟练安装、配置各种工具,以及利用这些工具提高团队的整体开发和运行效率(包括监控、优化等工具)
项目框架
P4(了解)
了解项目中使用的框架
P5(掌握)
1、理解项目中使用的框架;
2、熟练应用项目中使用的框架
P6(熟练)
1、掌握项目中使用的框架;熟练掌握应用项目中使用的框架
2、根据应用场景,具备一定的框架选型能力
P7(精通)
1、熟练掌握项目中使用的框架;熟练掌握应用项目中使用的框架
2、根据应用场景,具备较高的框架选型能力与适配能力
3、具备一定的框架对比与优化能力
P8(全局)
1、熟练掌握项目中使用的框架;熟练掌握应用项目中使用的框架
2、根据应用场景,具备丰富的框架选型能力与适配能力
3、具备丰富的框架对比与优化能力
团队协作
分享协作
P4(了解)
积极学习,接受团队的协助,与团队快速成长
P5(掌握)
积极学习,接受团队的协助,与团队快速成长
P6(熟练)
在团队内部提供协助和分享,并且产生明显提高效果
P7(精通)
1、对团队整体进行协助和分享,提升团队整体能力
2、对团队遇到的问题和困难能够牵头攻坚,并分享成果
P8(全局)
1、对团队整体进行协助和分享,提升团队整体能力
2、对团队遇到的问题和困难能够牵头攻坚,并分享成果
3、打破团队和部门之间的壁垒,提供协助和分享
目标合作
P4(了解)
1、对团队目标有清晰的认识
2、能够积极参与团队
P5(掌握)
1、对团队目标有清晰的认识
2、高度认同团队的目标
3、能够融入团队
P6(熟练)
1、对团队目标有清晰的认识
2、高度认同团队的目标
3、能够融入团队
4、在团队中有积极的表现
P7(精通)
1.对团队目标有清晰的认识
2.高度认同团队的目标
3.在团队中有积极的表现并能影响身边的人,带动团队成员
P8(全局)
1、对团队目标有清晰的认识
2、高度认同团队的目标
3、在团队中表现出重要的影响力,带领团队向目标冲击
4、在团队中有积极的表现并能影响身边的人,带动团队成员
主观能动性
自驱力
P4(了解)
1、对待自己的工作有责任心
2、有端正的工作态度,能够自我驱动,积极工作
3、对领导交办的任务能够按时完成
P5(掌握)
1、对待自己的工作有责任心
2、有端正的工作态度,能够自我驱动,积极工作
3、对领导交办的任务能够按时完成
4、主动学习业务和技术知识
P6(熟练)
1、对待自己的工作有责任心
2、有端正的工作态度,主动提出承担更多任务
3、对领导交办的任务能够按时完成
4、主动学习业务和技术知识
5、结合知识和业务,能够在工作中积极思考,有自己的想法
6、主动与上级和伙伴部门沟通,推进项目发展
7、主动为团队做出贡献
P7(精通)
1、对待自己的工作有责任心
2、有端正的工作态度,主动提出承担更多任务
3、对领导交办的任务能够按时完成
4、主动学习业务和技术知识
5、结合知识和业务,能够在工作中积极思考,有自己的想法
6、主动与上级和伙伴部门沟通,推进项目发展
7、主动承担团队中有风险有困难的工作,积极克服解决问题
P8(全局)
1、对待自己的工作有责任心
2、有端正的工作态度,主动提出承担更多任务
3、对领导交办的任务能够按时完成
4、主动学习业务和技术知识
5、结合知识和业务,能够在工作中积极思考,有自己的想法
6、主动与上级和伙伴部门沟通,推进项目发展
7、主动承担团队中有风险有困难的工作,积极克服解决问题
沟通交流
P4(了解)
表达逻辑清晰,有条理地表达自己的观点且能快速理解对方表达的意思
P5(掌握)
表达逻辑清晰,有条理地表达自己的观点且能快速理解对方表达的意思
P6(熟练)
优秀的沟通表达能力,表达逻辑清晰,有条理地表达自己的观点且能快速理解对方表达的意思
P7(精通)
1.优秀的沟通表达能力,表达逻辑清晰;
2.优秀的总结和概括能力;
3.优秀的理解和分析描述能力;
P8(全局)
1.优秀的沟通表达能力,表达逻辑清晰;
2.优秀的总结和概括能力;
3.优秀的理解和分析描述能力;

这篇关于【知识整理】产研中心岗位评定标准之大数据岗位的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






