本文主要是介绍《Java高并发程序设计》学习 --5.4 高性能的生产者-消费者:无锁的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BlockingQueue实现生产者-消费者是一个不错的选择,它很自然地实现了作为生产者和消费者的内存缓冲区。但是,BlockingQueue并不是一个高性能的实现,它完全使用锁和阻塞等待来实现线程间的同步。在高并发场合,它的性能并不是特别优越。 就像我们之前提过的ConcurrentLinkedQueue是一个高性能的队列,但是BlockingQueue只是为了方便数据共享。而ConcurrentLinkedQueue的秘诀就是大量使用了无锁的CAS操作。同理,如果我们使用了CAS来实现生产者-消费者模式,也同样可以获得可观的性能提升。
1)无锁的缓存框架:Disruptor
Disruptor框架是由于LMAX公司开发的一款高效的无锁内存队列,它使用无锁的方式实现了一个环形队列,非常适合生产者-消费者模式。在Disruptor中,使用了环形队列来代替普通的线性队列,这个环形队列内部实现为一个普通的数组。对于一般的队列,势必要提供队列头部head和尾部tail两个指针,用于出队和入队,这样无疑就增加了线程协作的复杂度。但如果队列的环形的,则只需要提供一个当前队列的位置cursor,利用这个cursor既可以出队也可以入队。由于是环形队列的缘故,队列的总大小必须事先指定,不能动态扩展。为了能够快速从一个序列sequence对应数组的实际位置(每次有元素入队,序列就加1),Disruptor要求我们必须将数组的大小设置为2的整数次方。这样通过sequence&(queueSize-1)就能立即定位到实际的元素位置index。这个要比取余(%)操作快得多。
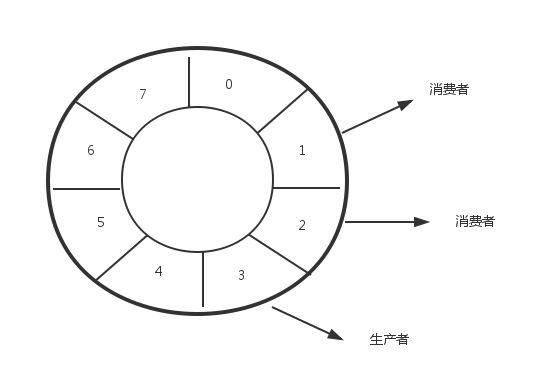
如图所示,显示了RingBuffer的结构,生产者向缓冲区中写入数据,而消费者从中读取数据,生产者写入数据使用CAS操作,消费者读取数据时,为了防止多个消费者处理同一个数据,也使用CAS操作进行保护。
这种固定大小的环形队列的另一个好处就是可以做到完全内存复用。在系统运行过程中,不会有新的空间需要分配或者老的空间需要回收。因此,可以大大减少系统分配空间以及回收空间的额外开销。
2)用Disruptor实现生产者-消费者案例
首先,我们需要一个代表数据的PCData:
public class PCData {private long value;public void set(long value) {this.value = value;}public long get() {return value;}
}消费者实现为WorkHandler接口,它来着Disruptor框架:
public class Consumer implements WorkHandler<PCData> {@Overridepublic void onEvent(PCData event) throws Exception {System.out.println(Thread.currentThread().getId() + ":Event: --" +event.get() * event.get() + "--");}
}消费者的作用是读取数据进行处理。这里,数据的读取已经由Disruptor进行封装,onEvent()方法为框架的回调方法。因此,这个只需要简单地进行数据处理即可。
还需要一个产生PCData的工厂类。它会在Disruptor系统初始化时,构造所有的缓冲区中的对象实例:
public class PCDataFactory implements EventFactory<PCData>{@Overridepublic PCData newInstance() {return new PCData();}
}接下来,看一下生产者:
public class Producer {private final RingBuffer<PCData> ringBuffer;public Producer(RingBuffer<PCData> ringBuffer) {this.ringBuffer = ringBuffer;}public void pushData(ByteBuffer byteBuffer){long sequence = ringBuffer.next();try {PCData event = ringBuffer.get(sequence);event.set(byteBuffer.getLong(0));} finally {ringBuffer.publish(sequence);}}
}生产者需要一个RingBuffer的引用,也就是环形缓冲区。它有一个重要的方法pushData()将产生的数据推入缓冲区。方法pushData()接收一个ByteBuffer对象。在ByteBuffer中可以用来包装任何数据类型。pushData()的功能就是将传入的ByteBuffer中的数据提取出来,并装载到环形缓冲区中。
上述第12行代码,通过next()方法得到下一个可用的序列号。通过序列号,取得下一个空闲可用的PCData,并且将PCData的数据设为期望值,这个值最终会传递给消费者。最后,在第21行,进行数据发布。只有发布后的数据才会真正被消费者看见。
至此,我们的生产者、消费者和数据都已经准备就绪。只差一个统筹规划的主函数将所有内容整合起来:
public static void main(String[] args) throws InterruptedException {Executor executor = Executors.newCachedThreadPool();//PCDataFactory factory = new PCDataFactory();EventFactory<PCData> factory = new EventFactory<PCData>() {@Overridepublic PCData newInstance() {return new PCData();}};//设置缓冲区大小,一定要是2的整数次幂int bufferSize = 1024;WaitStrategy startegy = new BlockingWaitStrategy();//创建disruptor,它封装了整个Disruptor的使用,提供了一些便捷的API.Disruptor<PCData> disruptor = new Disruptor<PCData>(factory, bufferSize, executor, ProducerType.MULTI, startegy);//设置消费者,系统会将每一个消费者实例映射到一个系统中,也就是提供4个消费者线程.disruptor.handleEventsWithWorkerPool(new Consumer(),new Consumer(),new Consumer(),new Consumer());//启动并初始化disruptor系统.disruptor.start();RingBuffer<PCData> ringBuffer = disruptor.getRingBuffer();//创建生产者Producer productor = new Producer(ringBuffer);ByteBuffer byteBuffer = ByteBuffer.allocate(8);//生产者不断向缓冲区中存入数据.for (long l=0;true;l++){byteBuffer.putLong(0,l);productor.pushData(byteBuffer);Thread.sleep(new Random().nextInt(500));System.out.println("add data "+l);}}3)提高消费者的响应时间:选择合适的策略
Disruptor为我们提供了几个策略,这些策略由WaitStrategy接口进行封装。
1. BlockingWaitStrategy:默认策略。和BlockingQueue是非常类似的,他们都使用了Lock(锁)和Condition(条件)进行数据监控和线程唤醒。因为涉及到线程的切换,BlockingWaitStrategy策略是最省CPU的,但在高并发下性能表现是最差的一种等待策略。
2. SleepingWaitStrategy:这个策略也是对CPU非常保守的。它会在循环中不断等待数据。它会先进行自旋等待,如果不成功,则使用Thread.yield()让出CPU,并最终使用LockSupport.parkNanos(1)进行线程休眠,以确保不占用太多的CPU数据。因此,这个策略对于数据处理可能产生比较高的平均延时。适用于对延时要求不是特别高的场合,好处是他对生产者线程的影响最小。典型的场景是异步日志。
3. YieldWaitStrategy:用于低延时场合。消费者线程会不断循环监控缓冲区变化,在循环内部,它会使用Thread.yield()让出CPU给别的线程执行时间。如果需要高性能系统,并且对延迟有较高要求,则可以考虑这种策略。这种策略相当于消费者线程变成了一个内部执行Thread.yield()的死循环,
因此最好有多于消费者线程的逻辑CPU(“双核四线程”中的四线程),否则整个应用会受到影响。
4. BusySpinWaitStrategy:疯狂等待策略。它就是一个死循环,消费者线程会尽最大努力监控缓冲区的变化。它会吃掉CPU所有资源。所以只在非常苛刻的场合使用它。因为这个策略等同于开一个死循环监控。因此,物理CPU数量必须大于消费者线程数。因为如果是逻辑核,那么另外一个逻辑核必然会受到这种超密集计算的影响而不能正常工作。
4)CPU Cache的优化:解决伪共存问题
我们知道,为了提高CPU的速度,CPU有一个高速缓存Cache。在高速缓存中,读写数据的最小单位是缓存行(Cache Line),它是主内存(memory)复制到 缓存(Cache)的最小单位,一般为32~128byte(字节)。
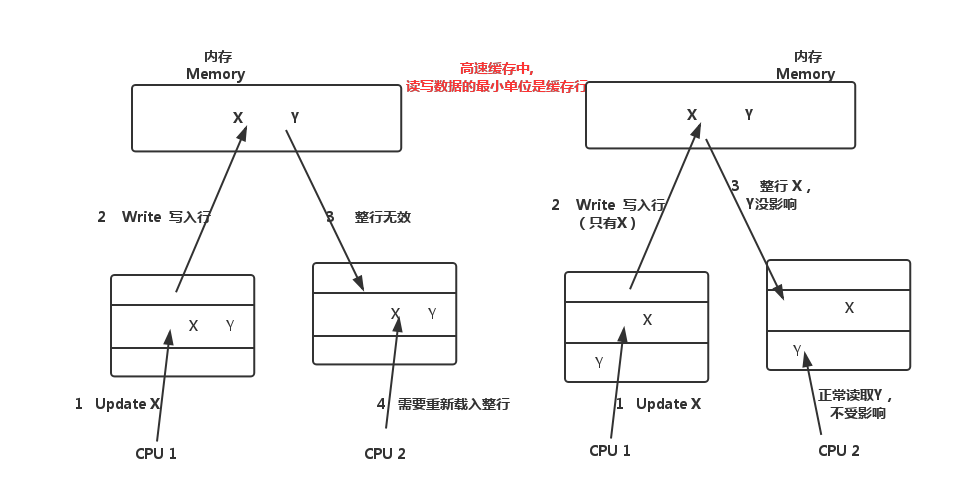
假如两个变量存放在同一个缓存行中,在多线程访问中,可能互相影响彼此的性能。如图,运行在CPU1上的线程更新了X,那么CPU2伤的缓存行就会失效,同一行的Y即使没有修改也会变成无效,导致Cache无法命中。接着,如果在CPU2上的线程更新了Y,则导致CPU1上的缓存行又失效(此时,同一行的X)。这无疑是一个潜在的性能杀手,如果CPU经常不能命中缓存,那么系统的吞吐量会急剧下降。
为了使这种情况不发生,一种可行的做法就是在X变量前后空间都占据一定的位置(暂叫padding,用来填充Cache Line)。这样,当内存被读入缓存中时,这个缓存行中,只有X一个变量实际是有效的,因此就不会发生多个线程同时修改缓存行中不同变量而导致变量全体失效的情况。
public class FalseSharing implements Runnable {public final static int NUM_THREADS = 4;public final static long ITERATIONS = 500L * 1000L * 1000L;private final int arrayIndex;private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];static {for(int i=0; i<longs.length; i++) {longs[i] = new VolatileLong();}}public FalseSharing(final int arrayIndex) {this.arrayIndex = arrayIndex;}public static void main(String[] args) throws Exception {final long start = System.currentTimeMillis();runTest();System.out.println("duration = " + (System.currentTimeMillis() - start));}private static void runTest() throws InterruptedException {Thread[] threads = new Thread[NUM_THREADS];for(int i=0; i<threads.length; i++) {threads[i] = new Thread(new FalseSharing(i));}for(Thread t : threads) {t.start();}for(Thread t : threads) {t.join();}}@Overridepublic void run() {long i = ITERATIONS + 1;while(0 != --i) {longs[arrayIndex].value = i;}}public final static class VolatileLong {public volatile long value = 0L;public long p1, p2, p3, p4, p5, p6, p7;}
}在VolatileLong中,准备了7个long型变量用来填充缓存。实际上,只有VolatileLong.value是会被使用的。而那些p1、p2等仅仅用于将数组中第一个VolatileLong.value是会被使用的。而那些p1、p2等仅仅用于将数组第一个VolatileLong.value和第二个VolatileLong.value分开,防止它们进入同一个缓存行。
Disruptor框架充分考虑了这个问题,它的核心组件Sequence会被非常频繁的访问(每次入队,它都会被加1),其基本结构如下:
class LhsPadding
{protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{protected volatile long value;
}
class RhsPadding extends Value
{protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding {
//省略具体实现
}虽然在Sequence中,主要使用的只有value。但是,通过LhsPadding和RhsPadding,在这个value的前后安置了一些占位空间,使得value可以无冲突的存在于缓存中。
此外,对于Disruptor的环形缓冲区RingBuffer,它内部的数组是通过以下语句构造的:
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
实际产生的数组大小是缓冲区实际大小再加上两倍的BUFFER_PAD。这就相当于在这个数组的头部和尾部两段各增加了BUFFER_PAD个填充,使得整个数组被载入Cache时不会受到其他变量的影响而失效。
注:本篇博客内容摘自《Java高并发程序设计》
这篇关于《Java高并发程序设计》学习 --5.4 高性能的生产者-消费者:无锁的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




