本文主要是介绍SBT编译spark-redis-master,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
spark-redis-master是用来让spark更简单地操作redis
将源码下载后解压缩到E盘,运行sbt,下载依赖jar包
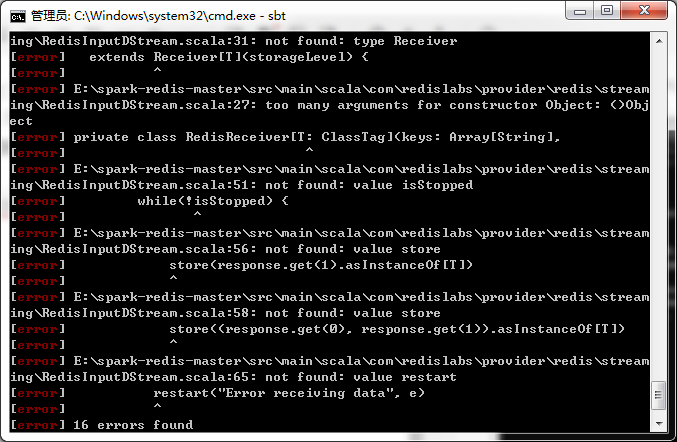
run结果出错
采用官方教程
第一步:配置git,mvn命令
yum -y install git
git --versionvim /etc/profile
export PATH=/usr/local/git/bin:$PATH
source /etc/profilegit --versionmaven安装包下载
tar -xvf apache-maven-2.2.1-bin.tar.gzmv -rf apache-maven-3.0.3 /usr/local/MAVEN_HOME=/usr/local/apache-maven-3.0.3
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/binsource /etc/profilemvn -v环境变量:etc/profile是所有用户系统环境变量,而bashrc是对单个用户而言的,环境变量就相当于东西在四楼,每次都要到四楼取,但是配置了环境变量,就即使在一楼也可以取四楼的东西
第二步:下载jar包
git clone https://github.com/RedisLabs/spark-redis.git
cd spark-redis
mvn clean package -DskipTests编译完之后会产生两个jar包,spark-redis-0.1.1.jar和spark-redis-0.1.1-jar-with-dependencies
只读redis slave节点数据
git checkout with-slaves启动spark,读入相应的jar包
$ bin/spark-shell --jars <path-to>/spark-redis-<version>.jar,<path-to>/jedis-<version>.jar之后可以用spark-redis.jar了
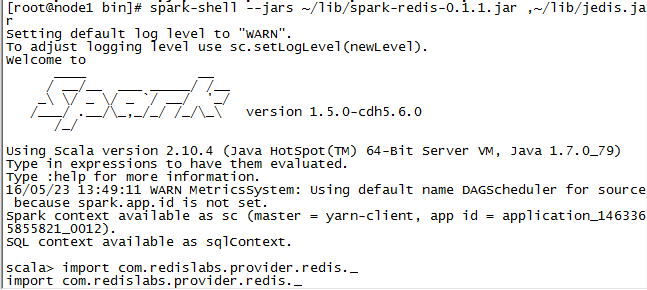
其实从redis读取数据,直接读就可以了,spark也是基于jvm的
因为创建RDD的方式有两种(1)读取外部数据集textFile(2)在驱动程序中对一个集合进行并行化,即parallelize()方法
e.g.val lines=sc.parallelize(Lisst("panda","i like panda"),4)
在下面一节博客中会详细介绍spark读取redis数据
这篇关于SBT编译spark-redis-master的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





