本文主要是介绍SelfAttention|自注意力机制ms简单实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自注意力机制学习有感
- 观看b站博主的讲解视频以及跟着他的pytorch代码实现mindspore的自注意力机制:
- up主讲的很好,推荐入门自注意力机制。
import mindspore as ms
import mindspore.nn as nn
from mindspore import Parameter
from mindspore import context
context.set_context(device_target='Ascend',max_device_memory='1GB') class SelfAttention(nn.Cell):def __init__(self, dim):super(SelfAttention, self).__init__()wq_data = [[1.0, 0], [1., 1.]] # wq权重初始化 超参数wk_data = [[0., 1.], [1., 1.]] # wk权重初始化 超参数wv_data = [[0., 1., 1.], [1., 0., 0.]] # wv权重初始化 超参数self.q = nn.Dense(in_channels=dim, out_channels=2, has_bias=False)self.q.weight.set_data(ms.Tensor(wq_data).T)print("wq value:", self.q.weight.value())self.k = nn.Dense(in_channels = dim, out_channels=2, has_bias=False)self.k.weight.set_data(ms.Tensor(wk_data).T)print('wk value:', self.k.weight.value())self.v = nn.Dense(in_channels=dim, out_channels=3, has_bias=False)# print(self.v.weight.shape)self.v.weight.set_data(ms.Tensor(wv_data).T)print('wv value:',self.v.weight.value())print("*********************" * 2)def construct(self, x):q = self.q(x)print('q value:', q)k = self.k(x)print('k value:', k)v = self.v(x)# xx = x.matmul(ms.Tensor([[0., 1., 1.], [1., 0., 0.]]))print('v value:', v, '\n')print('#################################')x = (q @ k.T)/ms.ops.sqrt(ms.tensor(2.))x = ms.ops.softmax(x) @ vprint("result:", x)x = [[1., 1.],[1,0],[2,1],[0, 2.]]
x = ms.Tensor(x)
attn = SelfAttention(2)
attn(x)
结果如下:
wq value: [[1. 1.][0. 1.]]
wk value: [[0. 1.][1. 1.]]
wv value: [[0. 1.][1. 0.][1. 0.]]
******************************************
q value: [[2. 1.][1. 0.][3. 1.][2. 2.]]
k value: [[1. 2.][0. 1.][1. 3.][2. 2.]]
v value: [[1. 1. 1.][0. 1. 1.][1. 2. 2.][2. 0. 0.]] #################################
result: [[1.5499581 0.71284014 0.71284014][1.3395231 0.7726004 0.7726004 ][1.7247156 0.4475609 0.4475609 ][1.4366053 1. 1. ]]
** 吐槽mindspore说明文档,对ms.nn.Dense的说明太过简单了,有对新手真不友好(对我) **
- pytorch的文档:
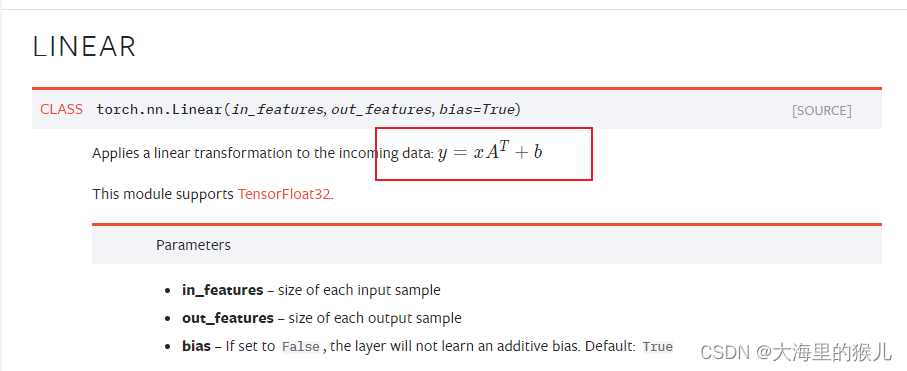
- mindspore的文档:

pytorch有公式,至少提示A的转置有提示。mindspore没有,导致我这步实现的时候输出的结果不对,还是希望mindspore说明问昂也把公式写清楚点。其实mindspore的Dense和pytorch的Linear的公式实现是一样的。
附上pytorch的实现:
#@title Default title text
import torch
import torch_npu
import torch.nn as nn
class Self_Attention(torch.nn.Module):def __init__(self, dim):super(Self_Attention, self).__init__() # 其中qkv代表构建好训练好的wq,wk,wv的权重参数;self.scale = 2 ** -0.5self.q = torch.nn.Linear(dim, 2, bias=False) q_list = [[1., 0.],[1., 1.]]self.q.weight.data = torch.Tensor(q_list).Tprint('q value:', self.q.weight.data)self.k = nn.Linear(dim, 2, bias=False)k_list = [[0., 1.], [1., 1.]]self.k.weight.data = torch.Tensor(k_list).Tprint('k value:', self.k.weight.data)self.v = nn.Linear(dim,3,bias=False)v_list = [[0., 1., 1.],[1., 0., 0.]]# print("origin shape:", self.v.weight.data.shape)self.v.weight.data = torch.Tensor(v_list).Tprint('init shape:',self.v.weight.data)def forward(self, x):q = self.q(x) # 通过训练好的参数生成q参数print("q:", q)k = self.k(x)print("k:", k)v = self.v(x)print("v shape:", v.shape)# Att公式attn = (q.matmul(k.T)) / torch.sqrt(torch.tensor(2.0))print("attn1:", attn)# attn = (q @ k.transpose(-2, -1)) / torch.sqrt(torch.tensor(2.0))# print("attn11:", attn)# attn = (q @ k.transpose(-2, -1)) * self.scale# print("attn2:", attn)attn = attn.softmax(dim=-1)print("softmax attn:", attn)# print(attn.shape) # shape[4,4]x = attn @ vprint(x.shape) #shape[4,3]return x
x = [[1., 1.],[1,0],[2,1],[0, 2.]]
x = torch.Tensor(x)
att = Self_Attention(2)
att(x)
这篇关于SelfAttention|自注意力机制ms简单实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






