本文主要是介绍“众里寻他千百度”-深度学习的本质,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.机器学习的基本概念
2.深度学习的常见任务
2.1回归任务
2.2分类任务
2.3结构化学习任务
3.回归任务的实例分析
3.1定义模型
3.2 定义损失函数
3.3 参数优化
1.机器学习的基本概念
机器学习(Machine Learning)是人工智能(Artificial Intelligence)的一个分支,旨在让计算机能够在没有明确编程的情况下学习。它通过分析数据并从中学习模式来完成任务,而不是通过明确编写规则来完成。在机器学习中,我们使用称为算法的程序来处理数据。这些算法通过不断学习来改进自己的性能,从而能够自动执行各种任务,例如识别图像中的对象、识别语音命令、预测股票价格等。机器学习在各行各业都有广泛应用,它可以用来预测股票价格、诊断疾病、分析市场趋势、识别欺诈等等。
综上,机器学习的本质是通过模型、参数和算法的设计,让计算机自动寻相对较好的参数,找到较好的函数方程,使其能够在解决实际问题时具有比较的表现(performance)。因此,简单来说,机器学习约等于“寻找函数”。

图1 机器学习的应用场景
图1中展示了机器学习常见的应用场景:(1)语音识别(Speech Recognition),对于语音识别的应用场景,函数的输入就是一段语音,输出就是语音对应的文字。(2)图像识别(Image Recognition),对于图像识别的问题,函数的输入就是一张图像,输出是图像对应的分类。(3)博弈任务(Playing Go),以下围棋为例,解决这一问题的本质就是寻找一个函数,输入一张当前棋局的图像,输出结果是下一步落子的问题。这也是2016年,围棋人机大战中,阿尔法围棋(AlphaGo)机器人所解决的主要问题。
2.深度学习的常见任务
深度学习的常见任务包括:回归任务(Regression)、分类任务(classification)和结构化学习任务(Structured Learning)。
2.1回归任务
对于回归任务来说,输出结果是连续的数值(scalar),在计算机中称为标量,示例见图2。
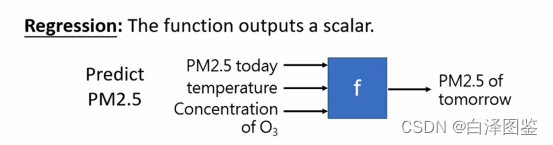
图2 回归任务示例
图2是一个典型的回归任务,主要用于解决未来PM2.5浓度预测的问题。对于这一问题,输入可能是今天PM2.5的浓度、温度和今天臭氧的浓度,输出是是明天PM2.5的浓度。深度学习的解决方案,主要通过寻找表现较好的函数来进行预测。
2.2分类任务
分类任务的输出结果是类别,它是个离散值(classes),按照离散值的个数可以将其划分为二分类任务和多分类任务。 图3和图4展示了二分类任务和多分类任务的典型示例。
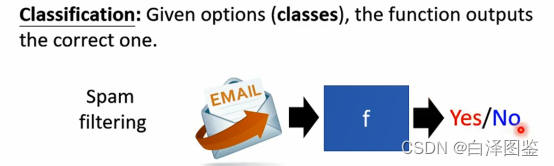
图3 二分类任务
图3是一个二分类任务,它是一个垃圾邮件分类的任务,用户给定了两个选项,需要机器辅助决策一封邮件是否为垃圾邮件。这个任务的输入为一封邮件,输出为“是否是垃圾邮件”的选项。
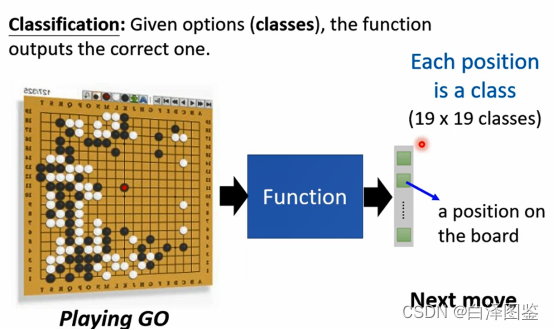
图4 多分类任务
图4是一个典型的多分类任务,也是之前举过的博弈任务的案例。这个任务的输入是棋盘现在的局势(可以是0-1表示的矩阵,也可以是图像),输出为棋盘上下一步机器落子的位置。因为棋盘上有19*19个位置,因此这个输出有19*19个选项。
2.3结构化学习任务
随着深度学习技术的不断发展,一种区别于传统任务的结构化学习任务随之诞生,它的目的是让机器产生结构化的元素,例如给定一段描述,让机器产生文章或者图像。
3.回归任务的实例分析
3.1定义模型
假设,需要使用机器学习模型来对未来一天的youtube频道的观看人数,这是一个典型的回归任务。第一步,需要定义一个带有未知参数(Parameters)的函数(Function),至于函数呈现出何种形式,取决于每个人对于该专业领域问题的认知。这里假定未来一天的观看人数(y)等于前一天的观看人数(x)乘以一个权重(weight),再加上一个偏差(bias),见图5。通常,在机器学习领域中,也将上述函数称之为模型,前一天观看的人数(x)被称为特征。其中,权重和偏差即为未知的参数,这两个参数需要根据数据资料和经验学习得到。

图5 定义函数
3.2 定义损失函数

图6 定义损失函数
解决观看人数预测问题的第二个步骤是需要定义一个损失函数(Loss),见图6。损失函数也是关于参数的函数,它衡量了当前参数所表示的模型离真实的情况有多接近,表达了估计结果与真实结果之间的差异。在给定一组参数的情况下,机器学习将历史数据中每一笔资料估计值与真实值之间的差距称为误差(Error,图6中的)。以图6为例,将前一天的观看人数4.8k,带入到上一步骤定义的函数中,可以得到后一天的估计的观看人数
,拿真实值y减去估计值取绝对值之后得到误差,损失函数为历史数据误差的平均值,这就得到了平均绝对误差(MAE,Mean Absolute Error)。通常计算误差的方式有两种,另外一种是平均方差(MSE,Mean Square Error),即历史数据真实值和估计值相减后取平方,再取平均数。
3.3 参数优化
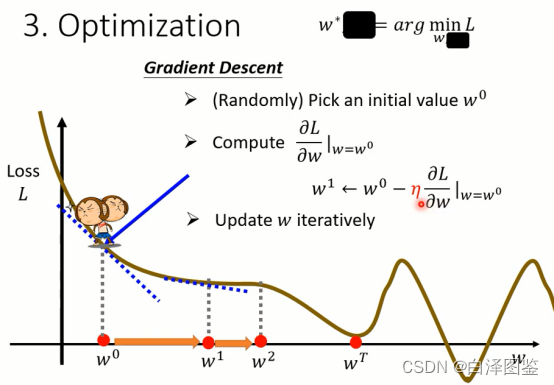
图7 参数优化
参数优化(Optimazation)的过程,本质上是寻找一组最优的参数使得损失函数达到最小值。因为参数优化,通常使用梯度下降(Gradient Descent)方法实现,因此,它也是一个不断迭代和更新的过程。使用梯度下降方法更新参数的过程见图7。首先随机初始化一组参数
,然后计算损失函数关于未知参数的微分(即求导数,由于这里用一元函数举例,也可以视为斜率),将参数
带入微分结果,计算得梯度
。接着利用计算得梯度更新参数,
减去
,即沿着梯度反方向更新参数,能够保证损失不断减小(斜率得同方向函数增加,反方向函数减小),得到当前参数为
。在上述过程中,
决定了参数得更新速度,因此,将其称为学习速率(Learning Rate)。因为它需要事先给定,机器无法通过训练资料学习得到,也称为超参数(Hyperparameter)。这个过程就不断重复,参数会不断得到更新。
梯度下降方法停止的准则有两个。其一,程序事先给定一个参数的迭代次数(如200,也是一个超参数);其二,当梯度为0时,参数的更新会停止。
在理想的情况下,如图7所示,参数会从更新至
,直到更新至
停止更新,将这里梯度为0的点(
)称之为局部最小点(Local Minima)。
在图7中的例子是只包含一个未知参数的情况,按照类似的方法可以拓展到二元甚至多元的情况,更新的过程见公式(1)至公式(2)。相应地,更新的参数增加了一个,由微分改变为求偏微分,更新的过程本质是一样的。
(1)
(2)
这篇关于“众里寻他千百度”-深度学习的本质的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




