本文主要是介绍关于平均数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于平均数
根据国家统计局发布的信息,2019年全国城镇非私营单位在岗职工社会年平均工资提高到了82461元,比2018年名义增长11%,实际增长8.7%。城镇私营单位在岗职工社会平均工资达到了49575元,比2018年上涨8.3%,扣除价格因素后,实际增长6.1%。
这些数据引起了广大网友的质疑,有人说自己拖了社会主义的后腿,自己又“被平均了”;也有土豪表示“没拖后腿,自己不差钱”。很多人调侃国家统计局的平均数计算方式:“张家有财一千万,九个邻居穷光蛋,平均起来算一算,个个都是张百万”。国家统计局的计算方式可不是简单地“平均起来算一算”,这种平均数仅仅是算数平均数,也叫均值。
均值
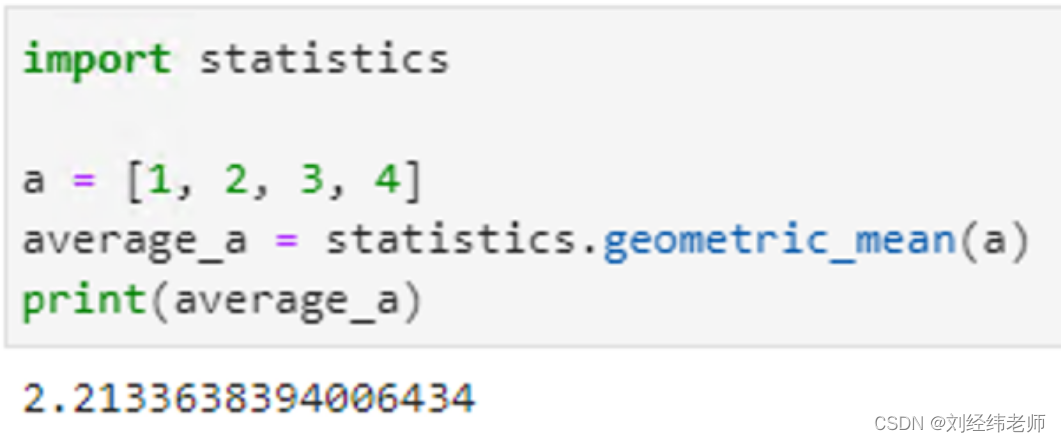
均值大家都清楚,就是求和平均,这是最深入人心的一种平均数。
在正态分布的假设下,均值也是数学期望,用μ表示,它位于倒钟的中心位置:
均值并不总是能反应数据的信息,有时很还会给人误导。下表是某个企业的月薪情况:
该企业的月薪均值是:
看起来是个待遇不错的公司,但实际情况是工程师和项目经理们天天要求加薪,原因是两位高管的月薪远远超过了其他人,他们是数据中的“异常值”。下面的代码绘制了月薪表的直方图:
import numpy as np
import matplotlib.pyplot as plt4 salary = np.array([4, 4, 4, 5, 5, 6, 6, 7, 7, 7, 6, 6, 25, 35])
miu = np.mean(salary) # 均值
print('μ =', miu)8 plt.hist(salary, bins=40)
plt.xlabel('月薪(千元)')
plt.ylabel('频度')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.show()两位高管被孤立了,他们的月薪将影响计算结果的准确性,此时我们说数据是偏斜的,确切地说,由于异常值在右侧,均值向右偏斜,形成了右偏态分布。
这种扭曲的倒钟曲线成为偏态分布,根据尾巴的位置,分为左偏态(负偏态)和右偏态(正偏态):
左偏态将把均值拉向左侧,此时均值小于大部分数值;右偏态把均值拉向右侧,此时均值大于大部分数值。工资表的数据是右偏态。
异常值可以通过一些异常检测算法来剔除,比如基于正态分布的异常检测和使用局部异常因子的无监督学习算法。
中位数
当异常数据对均值产生误导时,不妨试试中位数,这是另一种平均数。
正如它的名字一样,中位数永远在数据的中间位置。先把数据按大小排序,如果是奇数个,那么中位数正好是中间那个;如果是偶数个,那么中位数是中间两个数据的平均值。
按照中位数的算法把工资表展开:
共有14个数,位于中间的恰好都是6,因此中位数也是6。
1 salary = np.array([4, 4, 4, 5, 5, 6, 6, 7, 7, 7, 6, 6, 25, 35])
2 median = np.median(salary)
3 print('median =', median) # median = 6.0
中位数也有抓瞎的时候。
为了提升游乐园的竞争力,管理者决定根据游客的年龄来适当增加或减少一些项目。游乐园采取网上售票,所有游客在购票时都需要填写年龄。经过三个月的数据采集,计算出游客年龄的中位数是20,这可是个追求刺激的年龄,于是游乐园下架了旋转木马这类温柔的项目,添加了更大规模的过山车和大钟摆。在下一个周末:
游客中的大多数是家长带着小朋友,一大加一小的模式,假设某个项目正好有14个人参加,他们的年龄如下:
好了,现在中位数是20,结论是这个项目适合20岁的年轻人参加,于是:
ages = np.array([5, 5, 5, 6, 6, 7, 8, 32, 32, 32, 34, 35, 36, 36])
print('μ =', ages.mean()) # 均值,等同于np.mean(ages)
print('median =', np.median(ages)) # 中位数
plt.hist(ages, bins=40)
plt.xlabel('年龄')
plt.ylabel('频度')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.show()μ = 19.928571428571427,median = 20.0,直方图如下:
数据呈驼峰形,均值和中位数都在峰谷,其原因是数据应该划分为两批,一批是孩子,另一批是父母。这种情况下均值和中位数都不靠谱了,需要使用“众数”。
众数
众数也是一种平均数,是一组数据中频数最大的数值。与前两种平均数不同,一组数据的众数可能有多个。如果数据呈现出多种趋势,我们可以为每种趋势给出一个众数。游乐场年龄数据可以分为两批,称这种数据是双峰数据。
求得众数的方法很多,比如观察法,金氏插入法,皮尔逊经验法等。这里简单地介绍一下观察法。观察法大致分为2步:先将数据按照数值分组统计频数,再把频数最高的一个或几个挑选出来作为众数。可以使用pandas求得众数:
1 import pandas as pd 2 df = pd.DataFrame(ages) 3 print(df.mode()) # 众数
结果是5和32。
众数是唯一自带分组属性的平均数,但是如果一组数据的众数太多,则只会混淆视听,此时的众数将没有任何用处。
最后附上不同分布下均值、中位数、众数的关系:
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公作者众号“我是8位的”
这篇关于关于平均数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!