本文主要是介绍MQ四大消费问题一锅端:消息不丢失 + 消息积压 + 重复消费 + 消费顺序性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RabbitMQ-如何保证消息不丢失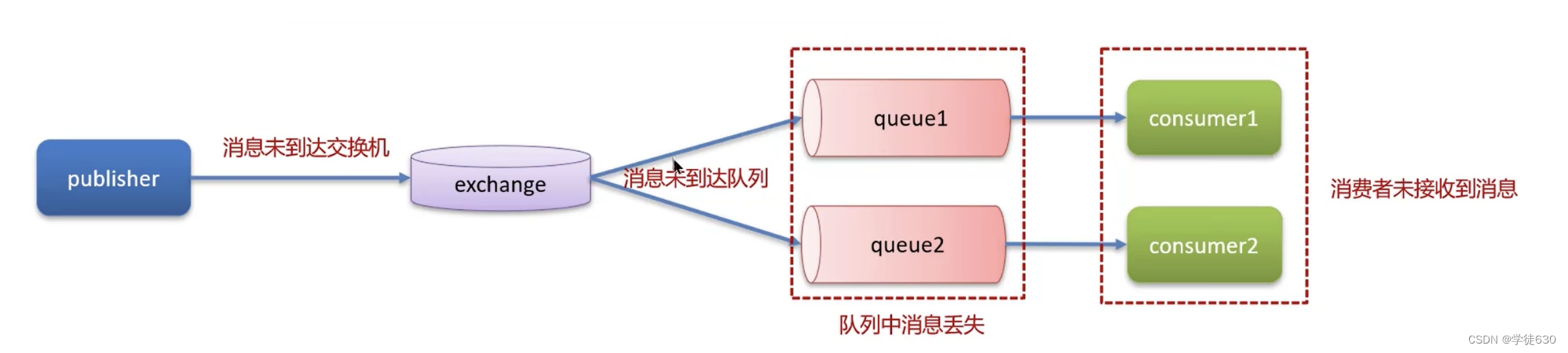
-
生产者把消息发送到 RabbitMQ Server 的过程中丢失
-
从生产者发送消息的角度来说,RabbitMQ 提供了一个 Confirm(消息确认)机制,生产者发送消息到 Server 端以后,如果消息处理成功,Server 端会返回一个 ack 消息。客户端可以根据消息的处理结果来决定是否要做消息的重新发送,从而确保消息一定到达 RabbitMQ Server 上。
-
-
RabbitMQ Server 收到消息后在持久化之前宕机,数据未到达队列导致数据丢失
-
在发布消息时,你可以设置消息的持久化属性,使其在 RabbitMQ 服务器宕机后仍然保存在磁盘上。这样即使服务器宕机,消息仍然会被保存,并在服务器重新启动后恢复。使用事务来确保消息的持久化和发送的原子性。在开启事务模式后,RabbitMQ 会等待消息被完全写入磁盘后才确认发布成功
-
-
队列中的数据还未被消费就宕机,队列中的数据消息丢失
-
在创建队列时,可以将队列设置为持久化,这样在 RabbitMQ 服务宕机时,所有未被消费的消息也将被持久化保存在磁盘中,并在服务恢复时重新加载到队列中。
-
-
消费端收到消息还没来得及处理宕机,导致 RabbitMQ Server 认为这个消息已签收
-
把消息的自动确认机制修改成手动确认,也就是说消费端只有手动调用消息确认方法才表示消息已经被签收。确保消息被成功的业务调用后才发起确认信号来删除队列中的消息。
-
MQ百万消息持续积压问题
消息积压的原因是生产者的消息生产速度大于消费者的消费速度,遇到这个问题的时候,需要排查具体的原因再提出解决方案
-
流量变大,而RabbitMQ服务器配置偏低,导致消息产生速度大于消费速度;
-
扩容即可。可以纵向扩容,即增加服务器资源,该加内存加内存,该加CPU加CPU。如果纵向扩容不方便,那就横向扩容,即将单机改为集群模式,增加集群节点,并且增加消费者数量,让消费速度快起来!原来是5个消费者,现在变成50个消费者!
-
通过异步的方式来处理消息、或者通过批量处理的方式来消费。
-
采用惰性队列扩大交换器和消费者之间的消息可积压空间,正常队列把消息存放在内存中,可利用空间较小,惰性队列接收到消息后直接存入磁盘而非内存,要消费消息时才会从磁盘中读取并加载到内存,支持数百万数据的存储

-
-
消费者故障,从而消息只增不减;
-
通过查看日志搞清楚为什么消费者会故障,据我多年经验,发生此类问题大概率是程序代码写的不够完美,跑着跑着导致内存溢出,然后消费者进程被杀。要想永久解决此问题,需要结合日志分析程序代码,优化代码。临时解决方法是写监控脚本,如果发现消费者进程中断,需要重启服务!
-
-
程序逻辑设计有问题,导致生产者持续生产消息,而消费者不消费或者消费慢;
-
种情况发生的概率其实并不高,总之就是程序逻辑问题,判断的方法也很简单,持续观察服务器的资源耗费情况,如果内存、CPU一切都正常,但就是队列持续增长,而消费速度非常慢。此时,就需要好好查查程序代码了。当然,可以尝试增加消费者数量,看看是否有好转。
-
业务考虑
相信,当我们发现消息积压时,想必问题已经比较严重了,或者说已经影响到业务正常运转了,那么当务之急肯定是需要先将业务恢复正常。对于上面第二种情况,直接重启相关服务,让消费者恢复正常,定是首当其冲。
除此之外,还有一种“断尾求生”的骚操作,就是新开一个队列,将新产生的消息到新队列里,消费者也到新队列里消费。而老的队列,则需要做一个异步处理,慢慢消费掉即可。
当然,如果积压的消息不怎么重要,可有可无的话,那干脆直接删除掉,这样大家都省事不是。
RabbitMQ消息的重复消费问题
消息去重:在消费者端对接收到的消息进行去重操作,可以通过维护一个消息ID的集合(去重表)或者使用唯一标识(查数据库)来判断是否已经消费过该消息。如果已经消费过,则不进行处理,避免重复消费。
消息确认机制:RabbitMQ提供了消息确认机制,可以确保消息被正确地消费。消费者在消费完消息之后,可以手动向RabbitMQ发送确认消息,告知RabbitMQ该消息已经成功消费,RabbitMQ会将该消息标记为已确认,然后删除消息队列中的该消息。
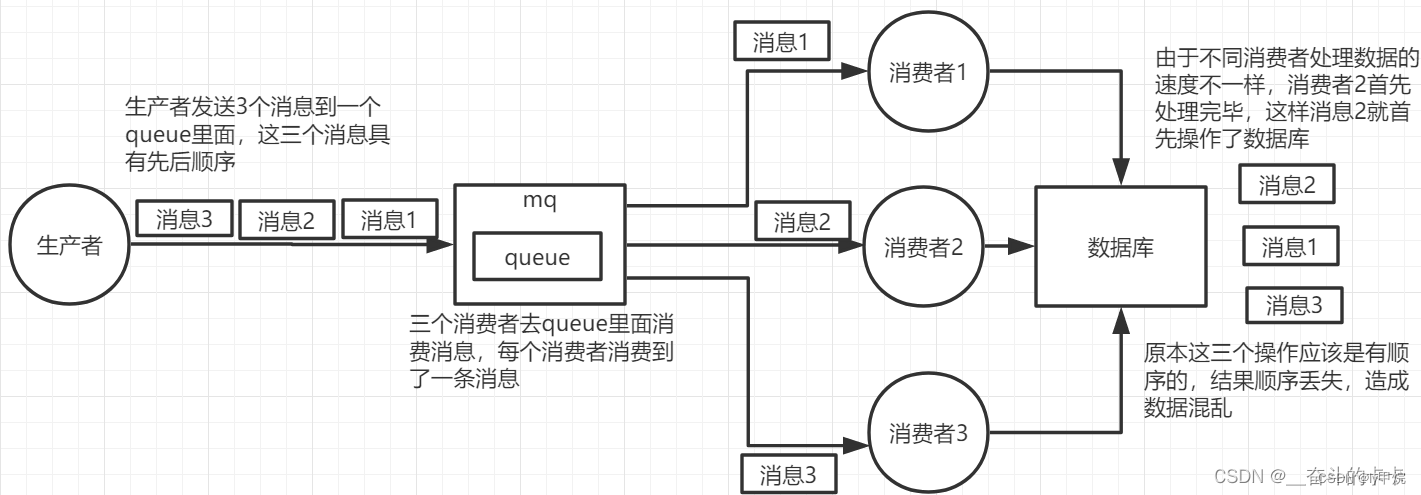
RabbitMQ消息的消费顺序性问题
业务中可能会存在多个消息需要顺序处理的情况,比如生成订单和扣减库存消息,那肯定先执行生成订单的操作,再执行扣减库存操作。
但我们的项目一般都是集群部署的,一个队列就会有多个消费者,怎么实现一个队列中所有顺序消息只能有一个消费者消费呢?
RabbitMQ本身并不能直接保证消息的消费顺序,因为其是基于 AMQP 协议 的,它使用多个消费者在多个线程上并行地消费消息。但是可以采取以下方法间接实现消息的有序消费:
解决方法
-
单消费者对单队列:可以给 RabbitMQ 创建多个queue, 每个消费者只消费一个queue, 生产者根据订单号,把订单号相同的消息放入一个同一个queue。这样同一个订单号的消息就只会被同一个消费者顺序消费。
-
使用多个队列和分区键:可以将相同类型的消息发送到多个队列,并使用分区键
routingKey(例如基于消息的某个属性)决定消息要发送到哪个队列。然后,在消费者端,针对每个队列都使用单个消费者来保证消息的消费顺序。 -
消费者内部排序:为了减少网络延迟、消费者运行速度等影响,在消费者端,可以对接收到的消息进行排序,以确保按照特定的顺序进行处理。消费者可以在内部维护一个消息缓冲区,按照某个属性或序列号对消息进行排序后再进行处理。
这篇关于MQ四大消费问题一锅端:消息不丢失 + 消息积压 + 重复消费 + 消费顺序性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



