本文主要是介绍桑基图/Sankey图/标签流转图/特征流转,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
桑基图/Sankey图/标签流转图/特征流转
目录
- 1、数据准备
- 2、画图
- 4个特征3层流转
- 2个特征1层流转
- 附录
- 附录1
- 附录2
- 附录3
1、数据准备
selectwk11,wk15,wk19,wk23,count(distinct xx_id) xx_cnt
from
(
selectxx_id,max(if(week = 11,new_type,null)) as wk11,max(if(week = 15,new_type,null)) as wk15,max(if(week = 19,new_type,null)) as wk19,max(if(week = 23,new_type,null)) as wk23
from
(
selectxx_id,weekofyear(concat_ws('-',substr(pt, 1, 4),substr(pt, 5, 2),substr(pt, 7, 2))) week,type as new_type
fromtable_a
wherept between '20220314' and '20220612'and weekofyear(concat_ws('-',substr(pt, 1, 4),substr(pt, 5, 2),substr(pt, 7, 2))) in (11,15,19,23)and pmod(datediff(concat_ws('-',substr(pt, 1, 4),substr(pt, 5, 2),substr(pt, 7, 2)), '2019-06-30'), 7) = '2'
group byxx_id,weekofyear(concat_ws('-',substr(pt, 1, 4),substr(pt, 5, 2),substr(pt, 7, 2))),type
) dr1 group by xx_id
) re
group by wk11 ,wk15 ,wk19 ,wk23
数据样式
| wk11 | wk15 | wk19 | wk23 | cnt |
|---|---|---|---|---|
| a | a | b | c | cnt1 |
| a | b | b | c | cnt2 |
| a | d | c | d | cnt3 |
| a | c | b | a | cnt4 |
| … | … | … | … | … |
2、画图
4个特征3层流转
桑基图结果见附录1,输出为html格式,鼠标停留展示数据。
import requests
import json
import numpy as np
import pandas as pd
import datetime
from datetime import datetime,timedelta
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
from matplotlib import ticker
from pyecharts.charts import Sankey
from pyecharts import options as opts# 关闭科学输入法
pd.set_option('display.float_format',lambda x : '%.6f' % x)
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']df0 = pd.read_csv('./y0_dr_tran.csv',encoding = 'utf-8-sig')
df0.info()
data0 = df0.fillna('new')data0.iloc[:,0] = ['wk11-%s' % j for j in data0.iloc[:,0]]
data0.iloc[:,1] = ['wk15-%s' % j for j in data0.iloc[:,1]]
data0.iloc[:,2] = ['wk19-%s' % j for j in data0.iloc[:,2]]
data0.iloc[:,3] = ['wk23-%s' % j for j in data0.iloc[:,3]]
data0
# 附录2nodes = []
for i in range(4):vales = data0.iloc[:, i].unique()for value in vales:dic = {}dic['name'] = valuenodes.append(dic)first = data0.groupby(['wk11', 'wk15'])['dr_cnt'].sum().reset_index()
second = data0.groupby(['wk15', 'wk19'])['dr_cnt'].sum().reset_index()
third = data0.groupby(['wk19', 'wk23'])['dr_cnt'].sum().reset_index()
first.columns = ['source', 'target', 'value']
second.columns = ['source', 'target', 'value']
third.columns = ['source', 'target', 'value']
result = pd.concat([first, second, third]).reset_index(drop=True)
result
# 附录3linkes=[]
for i in result.values:dic={}dic['source']=i[0]dic['target']=i[1]dic['value']=i[2]linkes.append(dic)
linkespic=(Sankey().add('', # 图例名称nodes, # 传入节点数据linkes, # 传入边和流量数据# 设置透明度、弯曲度、颜色linestyle_opt=opts.LineStyleOpts(opacity=0.3,curve=0.5,color='source'),# 标签显示位置label_opts=opts.LabelOpts(position='right'),# 节点之间的距离node_gap=30,# orient="vertical",#查看垂直图片的操作).set_global_opts(title_opts=opts.TitleOpts(title='司机标签流转记录(全量)'))
)
pic.render('dr_tran_sankey_all.html')
# 附录1
2个特征1层流转
data1 = df0.fillna('loss')
data1 = data1[data1['wk08']!='loss']
data1data1.iloc[:,0] = ['wk08-%s' % j for j in data1.iloc[:,0]]
# data1.iloc[:,1] = ['wk15-%s' % j for j in data1.iloc[:,1]]
# data1.iloc[:,2] = ['wk19-%s' % j for j in data1.iloc[:,2]]
data1.iloc[:,1] = ['wk23-%s' % j for j in data1.iloc[:,1]]
data1nodes = []
for i in range(2):vales = data1.iloc[:, i].unique()for value in vales:dic = {}dic['name'] = valuenodes.append(dic)first = data1.groupby(['wk08', 'wk23'])['dr_cnt'].sum().reset_index()
# second = data1.groupby(['wk15', 'wk19'])['dr_cnt'].sum().reset_index()
# third = data1.groupby(['wk19', 'wk23'])['dr_cnt'].sum().reset_index()
first.columns = ['source', 'target', 'value']
# second.columns = ['source', 'target', 'value']
# third.columns = ['source', 'target', 'value']
result = pd.concat([first]).reset_index(drop=True)linkes=[]
for i in result.values:dic={}dic['source']=i[0]dic['target']=i[1]dic['value']=i[2]linkes.append(dic)pic=(Sankey().add('', # 图例名称nodes, # 传入节点数据linkes, # 传入边和流量数据# 设置透明度、弯曲度、颜色linestyle_opt=opts.LineStyleOpts(opacity=0.3,curve=0.5,color='source'),# 标签显示位置label_opts=opts.LabelOpts(position='right'),# 节点之间的距离node_gap=30,# orient="vertical",#查看垂直图片的操作).set_global_opts(title_opts=opts.TitleOpts(title='司机标签流转记录(锁定第8周)'))
)
pic.render('流转记录(锁定第8周).html')
附录
附录1
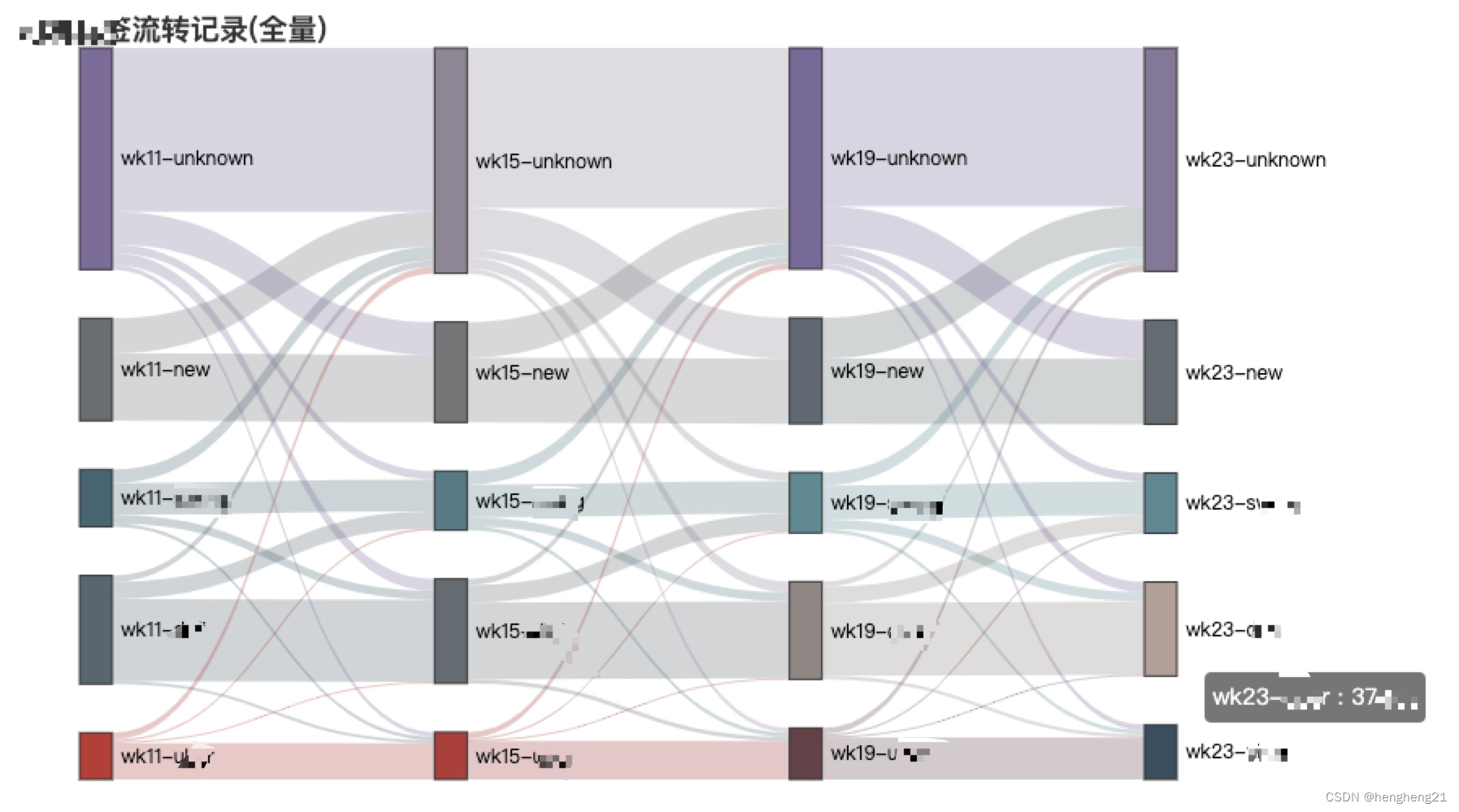
附录2
| wk11 | wk15 | wk19 | wk23 | cnt |
|---|---|---|---|---|
| wk11-a | wk15-a | wk19-b | wk23-c | cnt1 |
| wk11-a | wk15-b | wk19-b | wk23-c | cnt2 |
| wk11-a | wk15-d | wk19-c | wk23-d | cnt3 |
| wk11-a | wk15-c | wk19-b | wk23-a | cnt4 |
| … | … | … | … | … |
附录3
| source | target | value |
|---|---|---|
| wk11-a | wk15-a | cn11 |
| wk11-a | wk15-b | cn12 |
| … | … | … |
| wk15-a | wk19-a | cn21 |
| wk15-a | wk19-b | cn22 |
| … | … | … |
这篇关于桑基图/Sankey图/标签流转图/特征流转的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







