本文主要是介绍上市公司实证2011-2019数字化转型的市场绩效数字并购能提升制造业企业市场势力吗含原始数据及计算结果、计算代码、参考文献,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 上市公司实证2011-2019数字化转型的市场绩效数字并购能提升制造业企业市场势力吗
|


数字化转型的市场绩效:数字并购能提升制造业企业市场势力吗?附录
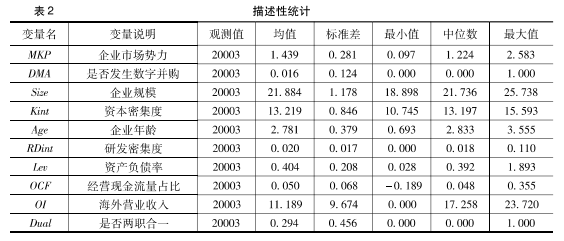
附录A:被解释变量企业市场势力的具体测算方法
本文借鉴产业组织领域相关研究的常用做法,以企业加成率衡量企业的市场势力(Blonigen和Pierce,2016;Stiebale和Vencappa,2018;李世刚等,2016;蒋冠宏,2021)。具体地,本文采用De Loecker和Warzynski(2012)的方法计算企业加成率,其优势在于既不依赖于难以获得的企业资本成本数据,也放松了生产函数规模报酬不变的假定。假设企业生产函数为:

其中,

表示企业

在

期的产出,

表示资本,

表示劳动投入,

表示中间品投入,

表示企业生产率。分行业的生产函数

连续并对所有元素均二次可微。考虑如下企业成本最小化问题:

其中,

、

和

分别表示各生产要素的价格水平。根据一阶条件可得:

。其中,

表示企业最终品的价格水平;

表示中间投入占企业产出的份额,可以通过数据直接计算得到;

表示企业产出对中间品投入的弹性,需要通过估计生产函数参数来计算。本文具体假定超越对数形式的生产函数,并借鉴Ackerberg等(2015)的做法估计生产函数参数。最终,企业加成率的表达式为:

具体计算过程中,企业产出采用营业收入的对数值衡量,资本采用固定资产净额的对数值衡量,劳动投入采用员工数量的对数值衡量;中间投入采用中间投入合计的对数值衡量[①]。其中,中间投入合计采用以下会计恒等式计算:中间投入合计=营业成本+销售费用+管理费用+财务费用-折旧摊销-支付给职工以及为职工支付的现金。
附录B:匹配后样本的平衡性和代表性检验结果及分析
为进一步缓解样本选择偏误,我们借鉴Brucal等(2019)的做法,以“2位码行业-年份”为匹配单元对处理组企业进行了1:1倾向得分最近邻匹配[②]。在使用匹配后样本进行回归之前,我们需要对匹配后样本的平衡性和代表性进行检验,具体检验结果见附表B。首先,如第(3)列的估计结果显示,在一些企业特征上匹配前的处理组与对照组存在明显差异。发生数字并购的企业(处理组)的规模、年龄和资本密集度均显著小于未发生数字并购的企业(对照组),而研发密集度和海外营业收入却显著高于对照组企业,表明选择进行数字并购的企业相对来说往往规模较小、更年轻、轻资产、重研发,海外业务也更多。这其实十分符合经济直觉:一般来说,规模较小的年轻制造业上市企业往往制造业基础相对薄弱,它们渴求实现技术追赶而大力研发,同时为降低研发风险,充分发挥“船小好调头”的竞争优势,也更倾向于直接收购数字企业,加快实现数字资产的内部化;而那些大规模的老牌制造业上市企业往往数字化转型起步更早,前期在企业内部数字化转型上投入的成本也较多,数字化程度已经较高,因而进行数字并购的意愿相对较低,即便进行数字并购也多是为了巩固自身已经形成的数字竞争力或是开拓新的数字业务(如前文提到的美的集团收购机器人企业,便是在自身优越的制造业基础上加码智能制造业务)。其次,观察第(6)列的检验结果可知,匹配后处理组与对照组的企业特征变量均值差异不具有统计显著性,表明经过1:1倾向得分匹配(PSM)后,处理组与对照组之间不再具有显著差异,样本平衡性良好。由于匹配过程中损失了三个企业样本,因此我们还进一步对匹配前后处理组样本的差异进行了检验。第(9)列估计结果显示,尽管样本有所损失,但匹配后的处理组样本仍具有较好的代表性。
附表B 匹配前后样本的平衡性和代表性检验
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | |
| 变量 | 匹配前处理组 | 匹配前对照组 | 均值差异t检验 | 匹配后处理组 | 匹配后对照组 | 均值差异t检验 | 匹配后处理组 | 匹配前处理组 | 均值差异t检验 |
| Size | 21.390 | 21.839 | -0.449*** | 22.111 | 22.028 | 0.083 | 22.111 | 21.390 | 0.720 |
| Kint | 12.611 | 13.177 | -0.567*** | 13.241 | 13.119 | 0.122 | 13.241 | 12.611 | 0.631 |
| Age | 2.606 | 2.756 | -0.150*** | 2.695 | 2.740 | -0.045 | 2.695 | 2.606 | 0.089 |
| RDint | 0.024 | 0.020 | 0.004** | 0.025 | 0.029 | -0.004 | 0.025 | 0.024 | 0.001 |
| Lev | 0.371 | 0.403 | -0.032 | 0.388 | 0.405 | -0.017 | 0.388 | 0.371 | 0.017 |
| OCF | 0.044 | 0.048 | -0.004 | 0.046 | 0.033 | 0.013 | 0.046 | 0.044 | 0.002 |
| OI | 14.443 | 10.998 | 3.445*** | 14.835 | 14.347 | 0.488 | 14.835 | 14.443 | 0.392 |
| Dual | 0.333 | 0.289 | 0.045 | 0.333 | 0.400 | -0.067 | 0.333 | 0.333 | 0.000 |
| 样本量 | 63 | 16937 | 60 | 60 | 60 | 63 |
注:*、**和***分别表示在10%、5%和1%的水平下显著。
附录C:稳健性检验
在前文基础上,我们还进行了一系列稳健性检验:(1)改变控制组。考虑到已发生并购的企业与从未发生并购的企业在并购倾向上可能存在差异,我们进一步仅以发生过非数字并购的企业作为控制组,并在此基础上重新进行匹配后再次回归。(2)剔除ICT相关行业。在企业进行数字并购及其数字化转型过程中,处于信息与通讯技术(Information and Communications Technology,ICT)行业的企业具有天然的数字资产获取需求以及数字化转型与发展的先天优势,因而可能使得估计结果受潜在内生性影响而有偏。为缓解这一影响,我们在基准回归的基础上进一步剔除样本中的ICT相关行业(即计算机、通信和电子设备制造行业),并重新进行匹配后样本回归。(3)增加控制变量。我们在回归中进一步加入当期的匹配协变量作为额外的控制变量,以控制当期的企业特征对估计结果的影响。(4)控制行业时间趋势。考虑到企业的市场势力可能会受到其所在行业某些非观测特定因素的影响,导致在不同行业的企业市场势力呈现出不同的时间趋势,进而影响估计结果的准确性。为此,我们借鉴Liu和Qiu(2016)的做法,将行业特定的时间趋势项(即

,其中

为2位码行业

的虚拟变量,当行业为

时取值为1,否则取值为0)作为额外的控制变量加入基准回归中再次进行估计。(5)更换估计方法。截止目前,本文采用了多种匹配方法验证核心结论,虽然PSM等匹配方法有助于实现因果识别,但其合理性依赖于处理方程或结果方程设置的准确性。因此,本文还采用逆概率加权回归调整(Inverse Probability Weighting Regression Adjustment,IPWRA)的方法识别因果效应,该方法通过将倾向得分方法与回归调整方法相结合,降低了误设参数引起估计错误的可能性(Wooldridge,2010)。(6)剔除发生多次数字并购的企业样本。在基准估计部分,我们以企业第一次发生数字并购的年份为处理年份的做法虽然可以避免在不同年份发生多次数字并购的企业被重复“处理”而造成处理效应重叠的问题,但也可能在一定程度上影响平均处理效应的准确估计。为此,我们也仅保留了发生过一次数字并购的企业,并将其作为处理组再次进行了检验。
前述各类稳健性检验的结果依次展示于附表C第(1)列至第(6)列。可以看到,核心解释变量DMA的估计系数均至少在5%显著性水平下显著为正,很好地验证了本文核心结论的稳健性。
附表C 稳健性检验结果
| 变量 | (1) | (2) | (3) | (4) | (5) | (6) |
| 改变控制组 | 剔除ICT相关行业 | 增加控制变量 | 控制行业时间趋势 | IPWRA | 剔除多次数字并购 | |
| DMA | 0.042** | 0.080** | 0.053*** | 0.031** | 0.031** | 0.042** |
| (0.019) | (0.039) | (0.019) | (0.015) | (0.013) | (0.016) | |
| 企业固定效应 | 是 | 是 | 是 | 是 | 是 | 是 |
| 年份固定效应 | 是 | 是 | 是 | 是 | 是 | 是 |
| 调整R2值 | 0.889 | 0.842 | 0.917 | 0.946 | 0.914 | 0.866 |
| 样本量 | 1051 | 813 | 1244 | 1244 | 17309 | 1046 |
注:括号中为聚类到企业层面的标准误,*、**和***分别表示在10%、5%和1%的水平下显著。
附录涉及的参考文献:
- Ackerberg D. A., Caves K., Frazer G., 2015, Identification Properties of Recent Production Function Estimators [J], Econometrica, 83(6),2411-2451.
- Blonigen B. A., Pierce J. R., 2016, Evidence for the Effects of Mergers on Market Power and Efficiency [R], Finance and Economics Discussion Series, No. 2016(082).
- Brucal A., Javorcik B., Love I., 2019, Good for the Environment, Good for Business: Foreign Acquisitions and Energy Intensity [J], Journal of International Economics, 121,103247.
- De Loecker J., Warzynski F., 2012, Markups and Firm-Level Export Status [J], American Economic Review, 102(6),2437-2471.
- Liu Q., Qiu L. D., 2016, Intermediate Input Imports and Innovations: Evidence from Chinese Firms’ Patent Filings [J], Journal of International Economics, 103,166-183.
- Stiebale J., Vencappa D., 2018, Acquisitions, Markups, Efficiency, and Product Quality: Evidence from India [J], Journal of International Economics, 112,70-87.
- Wooldridge J. M., 2010, Econometric Analysis of Cross Section and Panel Data [M], Cambridge, MA: 2nd ed, MIT Press.
- 蒋冠宏.并购如何提升企业市场势力——来自中国企业的证据[J].中国工业经济,2021(5):170-188.
- 李世刚,杨龙见,尹恒.异质性企业市场势力的测算及其影响因素分析[J].经济学报,2016,3(2):69-89.
- 肖曙光,彭文浩,黄晓凤.当前制造业企业的融资约束是过度抑或不足——基于高质量发展要求的审视与评判[J].南开管理评论,2020,23(2):85-97.
[①] 为了剔除价格因素对测算的影响,借鉴肖曙光等(2020)的做法,营业收入、中间投入合计和固定资产净额均以2008年为基年,分别按照国家统计局公布的工业品出厂价格指数、工业生产者购进价格指数和固定资产投资价格指数进行平减。
[②] 行业分类参照证监会发布的《上市公司行业分类指引(2012年修订)》。
数字化转型的市场绩效:数字并购能提升制造业企业市场势力吗?附录
附录A:被解释变量企业市场势力的具体测算方法
本文借鉴产业组织领域相关研究的常用做法,以企业加成率衡量企业的市场势力(Blonigen和Pierce,2016;Stiebale和Vencappa,2018;李世刚等,2016;蒋冠宏,2021)。具体地,本文采用De Loecker和Warzynski(2012)的方法计算企业加成率,其优势在于既不依赖于难以获得的企业资本成本数据,也放松了生产函数规模报酬不变的假定。假设企业生产函数为:

其中,

表示企业

在

期的产出,

表示资本,

表示劳动投入,

表示中间品投入,

表示企业生产率。分行业的生产函数

连续并对所有元素均二次可微。考虑如下企业成本最小化问题:

其中,

、

和

分别表示各生产要素的价格水平。根据一阶条件可得:

。其中,

表示企业最终品的价格水平;

表示中间投入占企业产出的份额,可以通过数据直接计算得到;

表示企业产出对中间品投入的弹性,需要通过估计生产函数参数来计算。本文具体假定超越对数形式的生产函数,并借鉴Ackerberg等(2015)的做法估计生产函数参数。最终,企业加成率的表达式为:

具体计算过程中,企业产出采用营业收入的对数值衡量,资本采用固定资产净额的对数值衡量,劳动投入采用员工数量的对数值衡量;中间投入采用中间投入合计的对数值衡量[①]。其中,中间投入合计采用以下会计恒等式计算:中间投入合计=营业成本+销售费用+管理费用+财务费用-折旧摊销-支付给职工以及为职工支付的现金。
附录B:匹配后样本的平衡性和代表性检验结果及分析
为进一步缓解样本选择偏误,我们借鉴Brucal等(2019)的做法,以“2位码行业-年份”为匹配单元对处理组企业进行了1:1倾向得分最近邻匹配[②]。在使用匹配后样本进行回归之前,我们需要对匹配后样本的平衡性和代表性进行检验,具体检验结果见附表B。首先,如第(3)列的估计结果显示,在一些企业特征上匹配前的处理组与对照组存在明显差异。发生数字并购的企业(处理组)的规模、年龄和资本密集度均显著小于未发生数字并购的企业(对照组),而研发密集度和海外营业收入却显著高于对照组企业,表明选择进行数字并购的企业相对来说往往规模较小、更年轻、轻资产、重研发,海外业务也更多。这其实十分符合经济直觉:一般来说,规模较小的年轻制造业上市企业往往制造业基础相对薄弱,它们渴求实现技术追赶而大力研发,同时为降低研发风险,充分发挥“船小好调头”的竞争优势,也更倾向于直接收购数字企业,加快实现数字资产的内部化;而那些大规模的老牌制造业上市企业往往数字化转型起步更早,前期在企业内部数字化转型上投入的成本也较多,数字化程度已经较高,因而进行数字并购的意愿相对较低,即便进行数字并购也多是为了巩固自身已经形成的数字竞争力或是开拓新的数字业务(如前文提到的美的集团收购机器人企业,便是在自身优越的制造业基础上加码智能制造业务)。其次,观察第(6)列的检验结果可知,匹配后处理组与对照组的企业特征变量均值差异不具有统计显著性,表明经过1:1倾向得分匹配(PSM)后,处理组与对照组之间不再具有显著差异,样本平衡性良好。由于匹配过程中损失了三个企业样本,因此我们还进一步对匹配前后处理组样本的差异进行了检验。第(9)列估计结果显示,尽管样本有所损失,但匹配后的处理组样本仍具有较好的代表性。
附表B 匹配前后样本的平衡性和代表性检验
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | |
| 变量 | 匹配前处理组 | 匹配前对照组 | 均值差异t检验 | 匹配后处理组 | 匹配后对照组 | 均值差异t检验 | 匹配后处理组 | 匹配前处理组 | 均值差异t检验 |
| Size | 21.390 | 21.839 | -0.449*** | 22.111 | 22.028 | 0.083 | 22.111 | 21.390 | 0.720 |
| Kint | 12.611 | 13.177 | -0.567*** | 13.241 | 13.119 | 0.122 | 13.241 | 12.611 | 0.631 |
| Age | 2.606 | 2.756 | -0.150*** | 2.695 | 2.740 | -0.045 | 2.695 | 2.606 | 0.089 |
| RDint | 0.024 | 0.020 | 0.004** | 0.025 | 0.029 | -0.004 | 0.025 | 0.024 | 0.001 |
| Lev | 0.371 | 0.403 | -0.032 | 0.388 | 0.405 | -0.017 | 0.388 | 0.371 | 0.017 |
| OCF | 0.044 | 0.048 | -0.004 | 0.046 | 0.033 | 0.013 | 0.046 | 0.044 | 0.002 |
| OI | 14.443 | 10.998 | 3.445*** | 14.835 | 14.347 | 0.488 | 14.835 | 14.443 | 0.392 |
| Dual | 0.333 | 0.289 | 0.045 | 0.333 | 0.400 | -0.067 | 0.333 | 0.333 | 0.000 |
| 样本量 | 63 | 16937 | 60 | 60 | 60 | 63 |
注:*、**和***分别表示在10%、5%和1%的水平下显著。
附录C:稳健性检验
在前文基础上,我们还进行了一系列稳健性检验:(1)改变控制组。考虑到已发生并购的企业与从未发生并购的企业在并购倾向上可能存在差异,我们进一步仅以发生过非数字并购的企业作为控制组,并在此基础上重新进行匹配后再次回归。(2)剔除ICT相关行业。在企业进行数字并购及其数字化转型过程中,处于信息与通讯技术(Information and Communications Technology,ICT)行业的企业具有天然的数字资产获取需求以及数字化转型与发展的先天优势,因而可能使得估计结果受潜在内生性影响而有偏。为缓解这一影响,我们在基准回归的基础上进一步剔除样本中的ICT相关行业(即计算机、通信和电子设备制造行业),并重新进行匹配后样本回归。(3)增加控制变量。我们在回归中进一步加入当期的匹配协变量作为额外的控制变量,以控制当期的企业特征对估计结果的影响。(4)控制行业时间趋势。考虑到企业的市场势力可能会受到其所在行业某些非观测特定因素的影响,导致在不同行业的企业市场势力呈现出不同的时间趋势,进而影响估计结果的准确性。为此,我们借鉴Liu和Qiu(2016)的做法,将行业特定的时间趋势项(即

,其中

为2位码行业

的虚拟变量,当行业为

时取值为1,否则取值为0)作为额外的控制变量加入基准回归中再次进行估计。(5)更换估计方法。截止目前,本文采用了多种匹配方法验证核心结论,虽然PSM等匹配方法有助于实现因果识别,但其合理性依赖于处理方程或结果方程设置的准确性。因此,本文还采用逆概率加权回归调整(Inverse Probability Weighting Regression Adjustment,IPWRA)的方法识别因果效应,该方法通过将倾向得分方法与回归调整方法相结合,降低了误设参数引起估计错误的可能性(Wooldridge,2010)。(6)剔除发生多次数字并购的企业样本。在基准估计部分,我们以企业第一次发生数字并购的年份为处理年份的做法虽然可以避免在不同年份发生多次数字并购的企业被重复“处理”而造成处理效应重叠的问题,但也可能在一定程度上影响平均处理效应的准确估计。为此,我们也仅保留了发生过一次数字并购的企业,并将其作为处理组再次进行了检验。
前述各类稳健性检验的结果依次展示于附表C第(1)列至第(6)列。可以看到,核心解释变量DMA的估计系数均至少在5%显著性水平下显著为正,很好地验证了本文核心结论的稳健性。
附表C 稳健性检验结果
| 变量 | (1) | (2) | (3) | (4) | (5) | (6) |
| 改变控制组 | 剔除ICT相关行业 | 增加控制变量 | 控制行业时间趋势 | IPWRA | 剔除多次数字并购 | |
| DMA | 0.042** | 0.080** | 0.053*** | 0.031** | 0.031** | 0.042** |
| (0.019) | (0.039) | (0.019) | (0.015) | (0.013) | (0.016) | |
| 企业固定效应 | 是 | 是 | 是 | 是 | 是 | 是 |
| 年份固定效应 | 是 | 是 | 是 | 是 | 是 | 是 |
| 调整R2值 | 0.889 | 0.842 | 0.917 | 0.946 | 0.914 | 0.866 |
| 样本量 | 1051 | 813 | 1244 | 1244 | 17309 | 1046 |
注:括号中为聚类到企业层面的标准误,*、**和***分别表示在10%、5%和1%的水平下显著。
附录涉及的参考文献:
- Ackerberg D. A., Caves K., Frazer G., 2015, Identification Properties of Recent Production Function Estimators [J], Econometrica, 83(6),2411-2451.
- Blonigen B. A., Pierce J. R., 2016, Evidence for the Effects of Mergers on Market Power and Efficiency [R], Finance and Economics Discussion Series, No. 2016(082).
- Brucal A., Javorcik B., Love I., 2019, Good for the Environment, Good for Business: Foreign Acquisitions and Energy Intensity [J], Journal of International Economics, 121,103247.
- De Loecker J., Warzynski F., 2012, Markups and Firm-Level Export Status [J], American Economic Review, 102(6),2437-2471.
- Liu Q., Qiu L. D., 2016, Intermediate Input Imports and Innovations: Evidence from Chinese Firms’ Patent Filings [J], Journal of International Economics, 103,166-183.
- Stiebale J., Vencappa D., 2018, Acquisitions, Markups, Efficiency, and Product Quality: Evidence from India [J], Journal of International Economics, 112,70-87.
- Wooldridge J. M., 2010, Econometric Analysis of Cross Section and Panel Data [M], Cambridge, MA: 2nd ed, MIT Press.
- 蒋冠宏.并购如何提升企业市场势力——来自中国企业的证据[J].中国工业经济,2021(5):170-188.
- 李世刚,杨龙见,尹恒.异质性企业市场势力的测算及其影响因素分析[J].经济学报,2016,3(2):69-89.
- 肖曙光,彭文浩,黄晓凤.当前制造业企业的融资约束是过度抑或不足——基于高质量发展要求的审视与评判[J].南开管理评论,2020,23(2):85-97.
[①] 为了剔除价格因素对测算的影响,借鉴肖曙光等(2020)的做法,营业收入、中间投入合计和固定资产净额均以2008年为基年,分别按照国家统计局公布的工业品出厂价格指数、工业生产者购进价格指数和固定资产投资价格指数进行平减。
[②] 行业分类参照证监会发布的《上市公司行业分类指引(2012年修订)》。
数字化转型的市场绩效:数字并购能提升制造业企业市场势力吗?附录
附录A:被解释变量企业市场势力的具体测算方法
本文借鉴产业组织领域相关研究的常用做法,以企业加成率衡量企业的市场势力(Blonigen和Pierce,2016;Stiebale和Vencappa,2018;李世刚等,2016;蒋冠宏,2021)。具体地,本文采用De Loecker和Warzynski(2012)的方法计算企业加成率,其优势在于既不依赖于难以获得的企业资本成本数据,也放松了生产函数规模报酬不变的假定。假设企业生产函数为:

其中,

表示企业

在

期的产出,

表示资本,

表示劳动投入,

表示中间品投入,

表示企业生产率。分行业的生产函数

连续并对所有元素均二次可微。考虑如下企业成本最小化问题:

其中,

、

和

分别表示各生产要素的价格水平。根据一阶条件可得:

。其中,

表示企业最终品的价格水平;

表示中间投入占企业产出的份额,可以通过数据直接计算得到;

表示企业产出对中间品投入的弹性,需要通过估计生产函数参数来计算。本文具体假定超越对数形式的生产函数,并借鉴Ackerberg等(2015)的做法估计生产函数参数。最终,企业加成率的表达式为:

具体计算过程中,企业产出采用营业收入的对数值衡量,资本采用固定资产净额的对数值衡量,劳动投入采用员工数量的对数值衡量;中间投入采用中间投入合计的对数值衡量[①]。其中,中间投入合计采用以下会计恒等式计算:中间投入合计=营业成本+销售费用+管理费用+财务费用-折旧摊销-支付给职工以及为职工支付的现金。
附录B:匹配后样本的平衡性和代表性检验结果及分析
为进一步缓解样本选择偏误,我们借鉴Brucal等(2019)的做法,以“2位码行业-年份”为匹配单元对处理组企业进行了1:1倾向得分最近邻匹配[②]。在使用匹配后样本进行回归之前,我们需要对匹配后样本的平衡性和代表性进行检验,具体检验结果见附表B。首先,如第(3)列的估计结果显示,在一些企业特征上匹配前的处理组与对照组存在明显差异。发生数字并购的企业(处理组)的规模、年龄和资本密集度均显著小于未发生数字并购的企业(对照组),而研发密集度和海外营业收入却显著高于对照组企业,表明选择进行数字并购的企业相对来说往往规模较小、更年轻、轻资产、重研发,海外业务也更多。这其实十分符合经济直觉:一般来说,规模较小的年轻制造业上市企业往往制造业基础相对薄弱,它们渴求实现技术追赶而大力研发,同时为降低研发风险,充分发挥“船小好调头”的竞争优势,也更倾向于直接收购数字企业,加快实现数字资产的内部化;而那些大规模的老牌制造业上市企业往往数字化转型起步更早,前期在企业内部数字化转型上投入的成本也较多,数字化程度已经较高,因而进行数字并购的意愿相对较低,即便进行数字并购也多是为了巩固自身已经形成的数字竞争力或是开拓新的数字业务(如前文提到的美的集团收购机器人企业,便是在自身优越的制造业基础上加码智能制造业务)。其次,观察第(6)列的检验结果可知,匹配后处理组与对照组的企业特征变量均值差异不具有统计显著性,表明经过1:1倾向得分匹配(PSM)后,处理组与对照组之间不再具有显著差异,样本平衡性良好。由于匹配过程中损失了三个企业样本,因此我们还进一步对匹配前后处理组样本的差异进行了检验。第(9)列估计结果显示,尽管样本有所损失,但匹配后的处理组样本仍具有较好的代表性。
附表B 匹配前后样本的平衡性和代表性检验
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | |
| 变量 | 匹配前处理组 | 匹配前对照组 | 均值差异t检验 | 匹配后处理组 | 匹配后对照组 | 均值差异t检验 | 匹配后处理组 | 匹配前处理组 | 均值差异t检验 |
| Size | 21.390 | 21.839 | -0.449*** | 22.111 | 22.028 | 0.083 | 22.111 | 21.390 | 0.720 |
| Kint | 12.611 | 13.177 | -0.567*** | 13.241 | 13.119 | 0.122 | 13.241 | 12.611 | 0.631 |
| Age | 2.606 | 2.756 | -0.150*** | 2.695 | 2.740 | -0.045 | 2.695 | 2.606 | 0.089 |
| RDint | 0.024 | 0.020 | 0.004** | 0.025 | 0.029 | -0.004 | 0.025 | 0.024 | 0.001 |
| Lev | 0.371 | 0.403 | -0.032 | 0.388 | 0.405 | -0.017 | 0.388 | 0.371 | 0.017 |
| OCF | 0.044 | 0.048 | -0.004 | 0.046 | 0.033 | 0.013 | 0.046 | 0.044 | 0.002 |
| OI | 14.443 | 10.998 | 3.445*** | 14.835 | 14.347 | 0.488 | 14.835 | 14.443 | 0.392 |
| Dual | 0.333 | 0.289 | 0.045 | 0.333 | 0.400 | -0.067 | 0.333 | 0.333 | 0.000 |
| 样本量 | 63 | 16937 | 60 | 60 | 60 | 63 |
注:*、**和***分别表示在10%、5%和1%的水平下显著。
附录C:稳健性检验
在前文基础上,我们还进行了一系列稳健性检验:(1)改变控制组。考虑到已发生并购的企业与从未发生并购的企业在并购倾向上可能存在差异,我们进一步仅以发生过非数字并购的企业作为控制组,并在此基础上重新进行匹配后再次回归。(2)剔除ICT相关行业。在企业进行数字并购及其数字化转型过程中,处于信息与通讯技术(Information and Communications Technology,ICT)行业的企业具有天然的数字资产获取需求以及数字化转型与发展的先天优势,因而可能使得估计结果受潜在内生性影响而有偏。为缓解这一影响,我们在基准回归的基础上进一步剔除样本中的ICT相关行业(即计算机、通信和电子设备制造行业),并重新进行匹配后样本回归。(3)增加控制变量。我们在回归中进一步加入当期的匹配协变量作为额外的控制变量,以控制当期的企业特征对估计结果的影响。(4)控制行业时间趋势。考虑到企业的市场势力可能会受到其所在行业某些非观测特定因素的影响,导致在不同行业的企业市场势力呈现出不同的时间趋势,进而影响估计结果的准确性。为此,我们借鉴Liu和Qiu(2016)的做法,将行业特定的时间趋势项(即

,其中

为2位码行业

的虚拟变量,当行业为

时取值为1,否则取值为0)作为额外的控制变量加入基准回归中再次进行估计。(5)更换估计方法。截止目前,本文采用了多种匹配方法验证核心结论,虽然PSM等匹配方法有助于实现因果识别,但其合理性依赖于处理方程或结果方程设置的准确性。因此,本文还采用逆概率加权回归调整(Inverse Probability Weighting Regression Adjustment,IPWRA)的方法识别因果效应,该方法通过将倾向得分方法与回归调整方法相结合,降低了误设参数引起估计错误的可能性(Wooldridge,2010)。(6)剔除发生多次数字并购的企业样本。在基准估计部分,我们以企业第一次发生数字并购的年份为处理年份的做法虽然可以避免在不同年份发生多次数字并购的企业被重复“处理”而造成处理效应重叠的问题,但也可能在一定程度上影响平均处理效应的准确估计。为此,我们也仅保留了发生过一次数字并购的企业,并将其作为处理组再次进行了检验。
前述各类稳健性检验的结果依次展示于附表C第(1)列至第(6)列。可以看到,核心解释变量DMA的估计系数均至少在5%显著性水平下显著为正,很好地验证了本文核心结论的稳健性。
附表C 稳健性检验结果
| 变量 | (1) | (2) | (3) | (4) | (5) | (6) |
| 改变控制组 | 剔除ICT相关行业 | 增加控制变量 | 控制行业时间趋势 | IPWRA | 剔除多次数字并购 | |
| DMA | 0.042** | 0.080** | 0.053*** | 0.031** | 0.031** | 0.042** |
| (0.019) | (0.039) | (0.019) | (0.015) | (0.013) | (0.016) | |
| 企业固定效应 | 是 | 是 | 是 | 是 | 是 | 是 |
| 年份固定效应 | 是 | 是 | 是 | 是 | 是 | 是 |
| 调整R2值 | 0.889 | 0.842 | 0.917 | 0.946 | 0.914 | 0.866 |
| 样本量 | 1051 | 813 | 1244 | 1244 | 17309 | 1046 |
注:括号中为聚类到企业层面的标准误,*、**和***分别表示在10%、5%和1%的水平下显著。
附录涉及的参考文献:
- Ackerberg D. A., Caves K., Frazer G., 2015, Identification Properties of Recent Production Function Estimators [J], Econometrica, 83(6),2411-2451.
- Blonigen B. A., Pierce J. R., 2016, Evidence for the Effects of Mergers on Market Power and Efficiency [R], Finance and Economics Discussion Series, No. 2016(082).
- Brucal A., Javorcik B., Love I., 2019, Good for the Environment, Good for Business: Foreign Acquisitions and Energy Intensity [J], Journal of International Economics, 121,103247.
- De Loecker J., Warzynski F., 2012, Markups and Firm-Level Export Status [J], American Economic Review, 102(6),2437-2471.
- Liu Q., Qiu L. D., 2016, Intermediate Input Imports and Innovations: Evidence from Chinese Firms’ Patent Filings [J], Journal of International Economics, 103,166-183.
- Stiebale J., Vencappa D., 2018, Acquisitions, Markups, Efficiency, and Product Quality: Evidence from India [J], Journal of International Economics, 112,70-87.
- Wooldridge J. M., 2010, Econometric Analysis of Cross Section and Panel Data [M], Cambridge, MA: 2nd ed, MIT Press.
- 蒋冠宏.并购如何提升企业市场势力——来自中国企业的证据[J].中国工业经济,2021(5):170-188.
- 李世刚,杨龙见,尹恒.异质性企业市场势力的测算及其影响因素分析[J].经济学报,2016,3(2):69-89.
- 肖曙光,彭文浩,黄晓凤.当前制造业企业的融资约束是过度抑或不足——基于高质量发展要求的审视与评判[J].南开管理评论,2020,23(2):85-97.
[①] 为了剔除价格因素对测算的影响,借鉴肖曙光等(2020)的做法,营业收入、中间投入合计和固定资产净额均以2008年为基年,分别按照国家统计局公布的工业品出厂价格指数、工业生产者购进价格指数和固定资产投资价格指数进行平减。
[②] 行业分类参照证监会发布的《上市公司行业分类指引(2012年修订)》。
这篇关于上市公司实证2011-2019数字化转型的市场绩效数字并购能提升制造业企业市场势力吗含原始数据及计算结果、计算代码、参考文献的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






