本文主要是介绍在Linux中搭建Pentaho Server集群,并使用MySQL作为存储库、Nginx做反向代理与负载均衡,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、准备工作
1、本文环境
| 名称 | CentOS | JDK | MySQL | Pentaho Server | Nginx |
|---|---|---|---|---|---|
| 版本 | 7.9 | 1.8 | 5.7 | 9.1 | 1.20.1 |
2、集群规划
| 主机名 | IP | 应用 |
|---|---|---|
| pentaho-server1 | 192.168.198.31 | Pentaho Server |
| pentaho-server2 | 192.168.198.32 | Pentaho Server |
| pentaho-server3 | 192.168.198.33 | Pentaho Server |
| nginx-mysql | 192.168.198.34 | Nginx、MySQL |
二、部署Pentaho Server集群
注意:本文所搭建的Pentaho Server集群是基于之前安装的Pentaho Server单机版对配置文件的进一步修改,若未搭建过单机版请参考《Pentaho Server单机版部署文档》进行基础的配置
1、将单机版的Pentaho Server拷贝至pentaho-server1节点中
[root@pentaho-server ~]# scp -r /opt/module/pentaho-server root@pentaho-server1:/opt/module/
2、在pentaho-server1节点中修改MySQL脚本文件
修改MySQL脚本中默认的密码、字符集编码以及赋予用户远程连接的权限
[root@pentaho-server1 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server1 pentaho-server]# vim data/mysql/create_jcr_mysql.sql

[root@pentaho-server1 pentaho-server]# vim data/mysql/create_quartz_mysql.sql
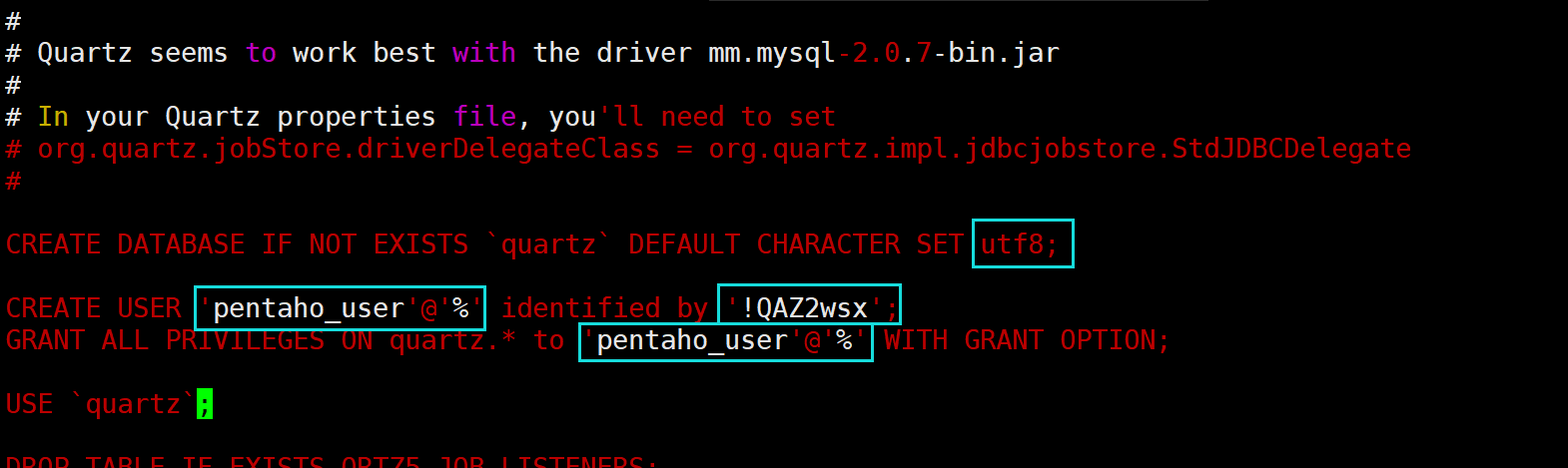
[root@pentaho-server1 pentaho-server]# vim data/mysql/create_repository_mysql.sql

3、在nginx-mysql节点中执行MySQL脚本
3.1、拷贝脚本至MySQL所在服务器中
[root@pentaho-server1 pentaho-server]# scp -r data/mysql/* root@nginx-mysql:/root/software

3.2、执行脚本
在安装MySQL的服务器(本文MySQL安装在nginx-mysql主机中)上登录MySQL,执行以上脚本创建Pentaho Server所需的用户以及数据库
# 查看脚本是否拷贝成功
[root@nginx-mysql ~]# cd /root/software/
[root@nginx-mysql software]# ll

# 登录MySQL
[root@nginx-mysql ~]# mysql -uroot -p
# 执行脚本文件
mysql> source /root/software/create_jcr_mysql.sql;
mysql> source /root/software/create_quartz_mysql.sql;
mysql> source /root/software/create_repository_mysql.sql;
4、在pentaho-server1节点中清理单机版运行后产生的一些文件
[root@pentaho-server1 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server1 pentaho-server]# rm -rf tomcat/temp/*
[root@pentaho-server1 pentaho-server]# rm -rf tomcat/work/*
[root@pentaho-server1 pentaho-server]# rm -rf pentaho-solutions/system/jackrabbit/repository/*
5、在pentaho-server1节点中修改配置文件
5.1、配置 Jackrabbit 日志(修改repository.xml配置文件)
[root@pentaho-server1 pentaho-server]# vim pentaho-solutions/system/jackrabbit/repository.xml
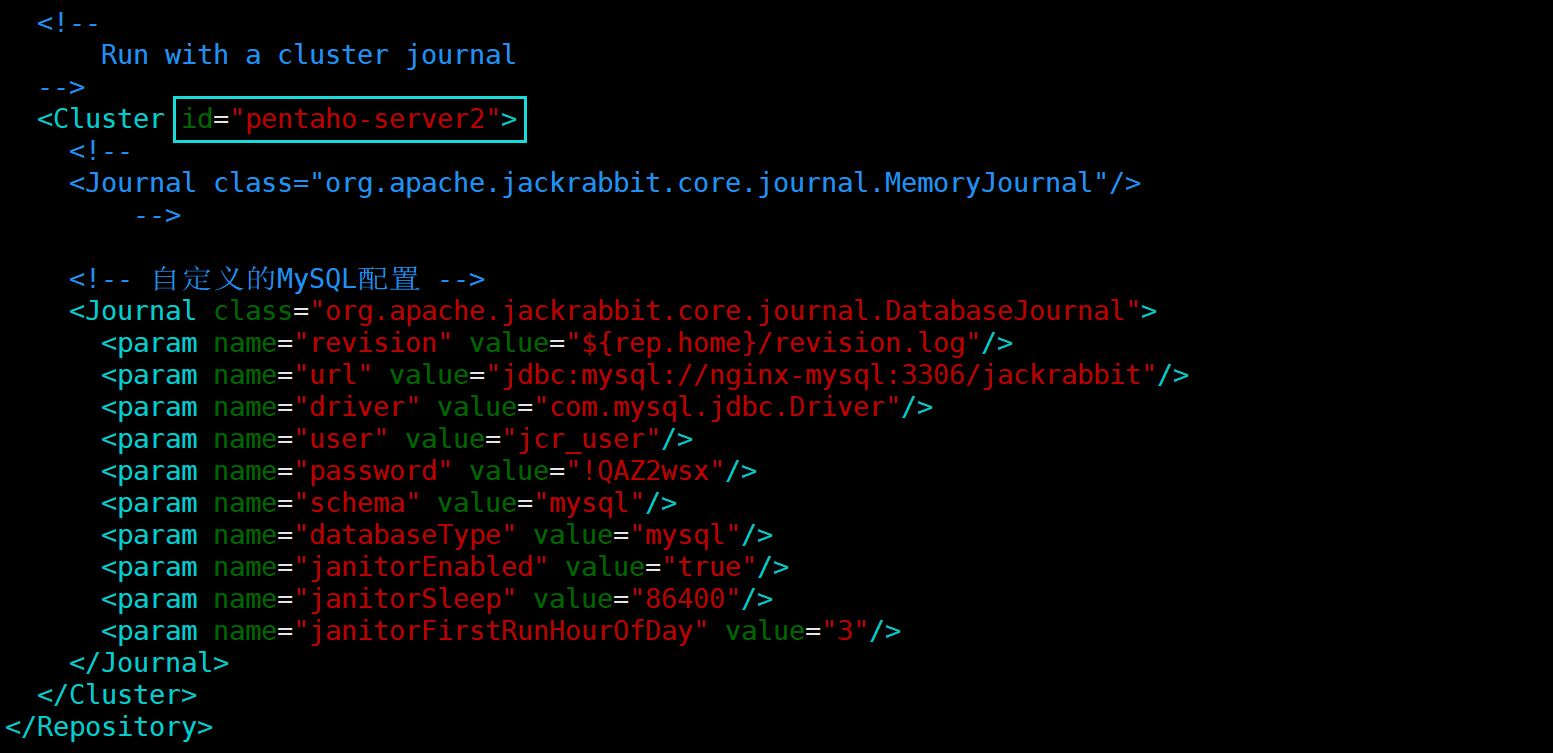
注意:修改集群id时,请确保集群每个节点的id是唯一
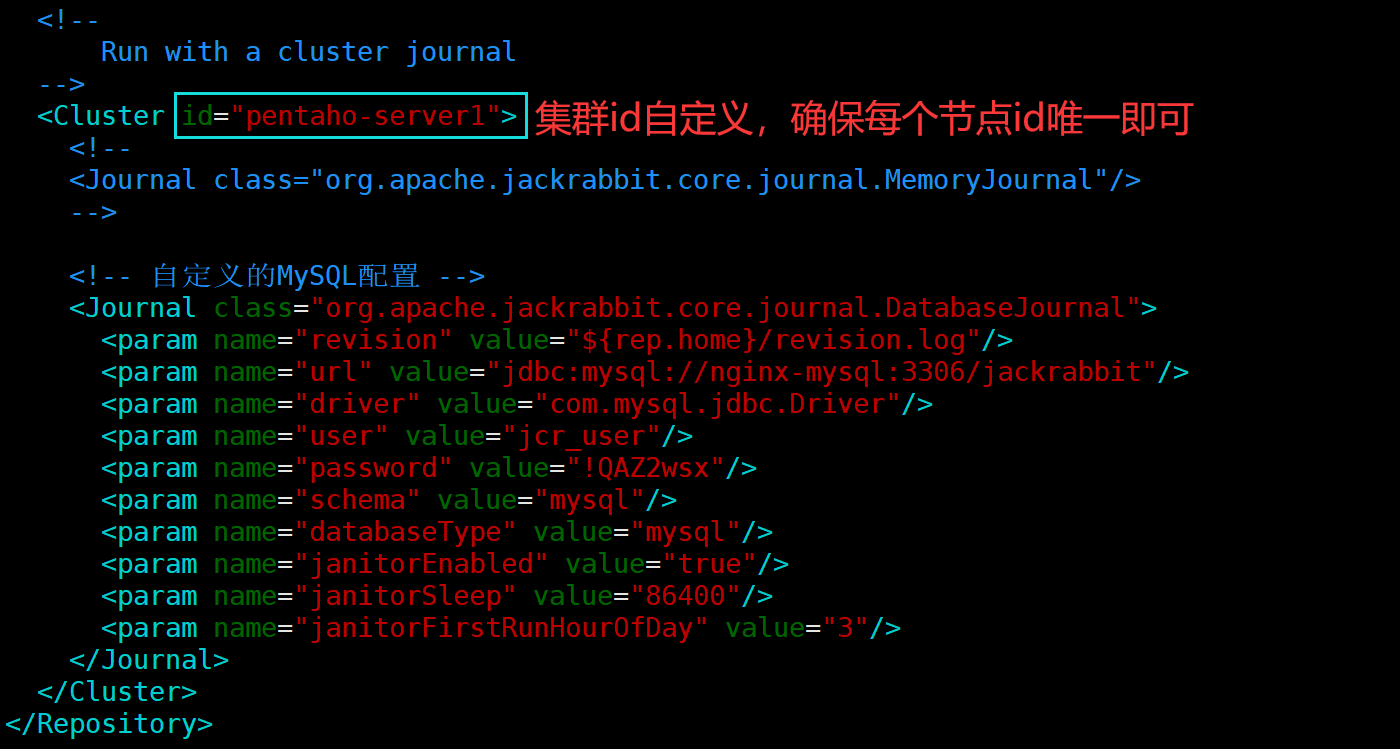
5.2、配置 Quartz 调度(修改quartz.properties配置文件)
[root@pentaho-server1 pentaho-server]# vim pentaho-solutions/system/quartz/quartz.properties
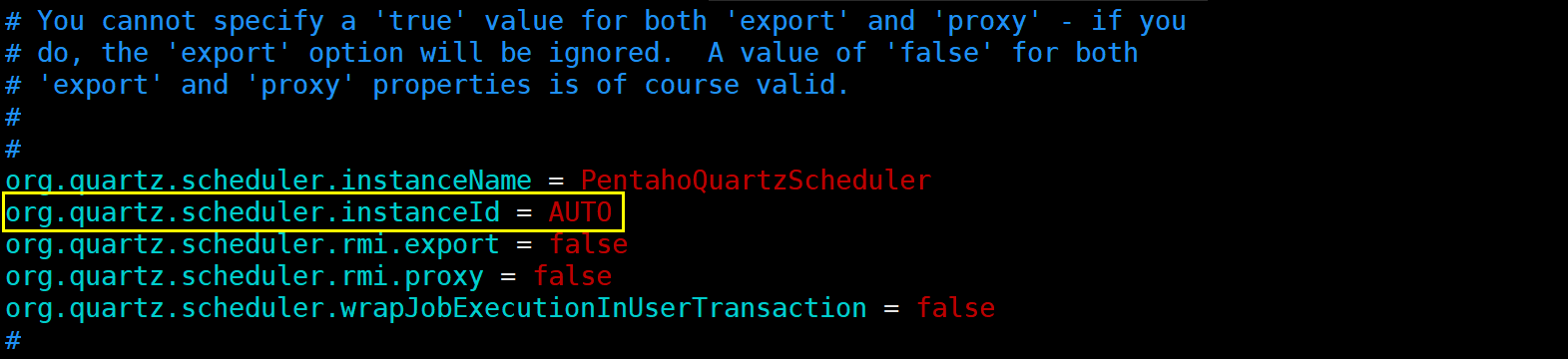
5.2.1、找到org.quartz.scheduler.instanceId = 1配置项,并将 1 改为 AUTO
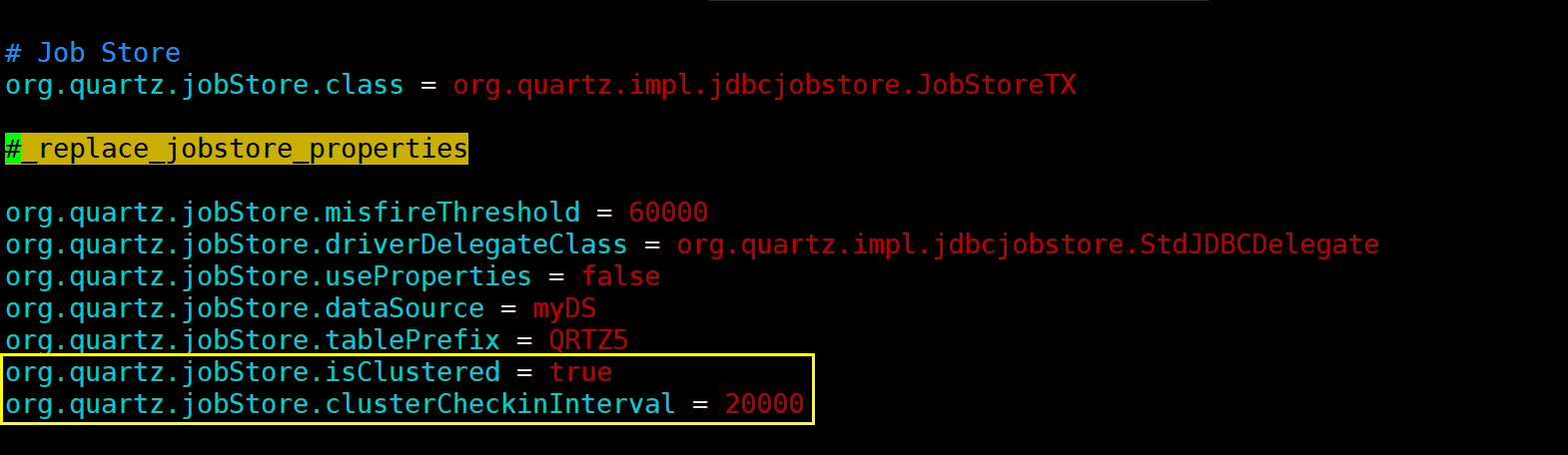
5.2.2、找到#_replace_jobstore_properties部分的org.quartz.jobStore.isClustered配置项,将其值设置为true,并在其下面添加org.quartz.jobStore.clusterCheckinInterval = 20000配置内容
6、将pentaho-server1节点上修改好配置的Pentaho Server拷贝至集群的其他节点
# 将Pentaho Server拷贝至pentaho-server2中
[root@pentaho-server1 ~]# scp -r /opt/module/pentaho-server root@pentaho-server2:/opt/module/
# 将Pentaho Server拷贝至pentaho-server3中
[root@pentaho-server1 ~]# scp -r /opt/module/pentaho-server root@pentaho-server3:/opt/module/
7、修改集群其他节点repository.xml配置文件中的集群id
7.1、修改pentaho-server2中的配置文件
[root@pentaho-server2 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server2 pentaho-server]# vim pentaho-solutions/system/jackrabbit/repository.xml
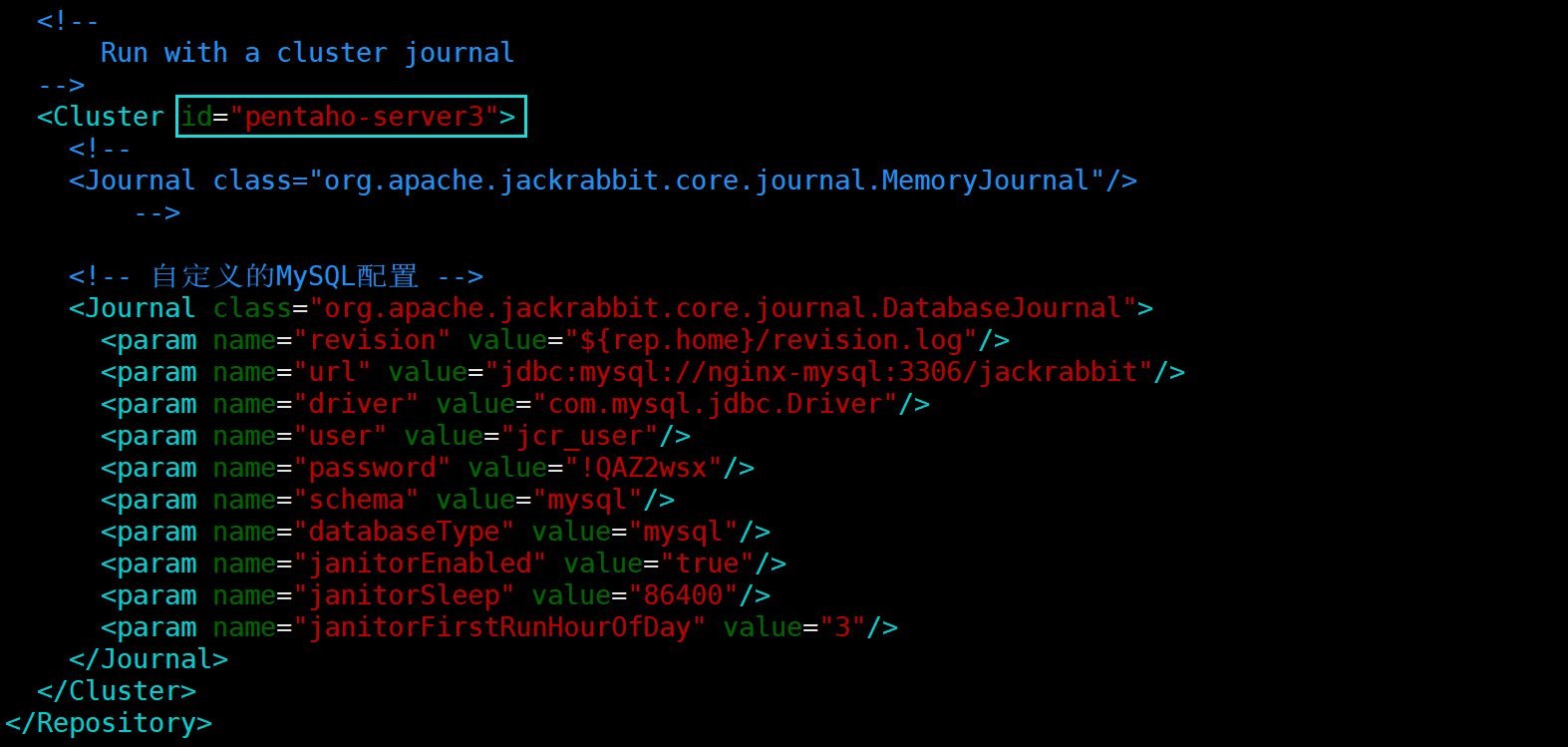
7.1、修改pentaho-server3中的配置文件
[root@pentaho-server3 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server3 pentaho-server]# vim pentaho-solutions/system/jackrabbit/repository.xml
8、分别在集群的各个节点启动Pentaho Server并监听日志
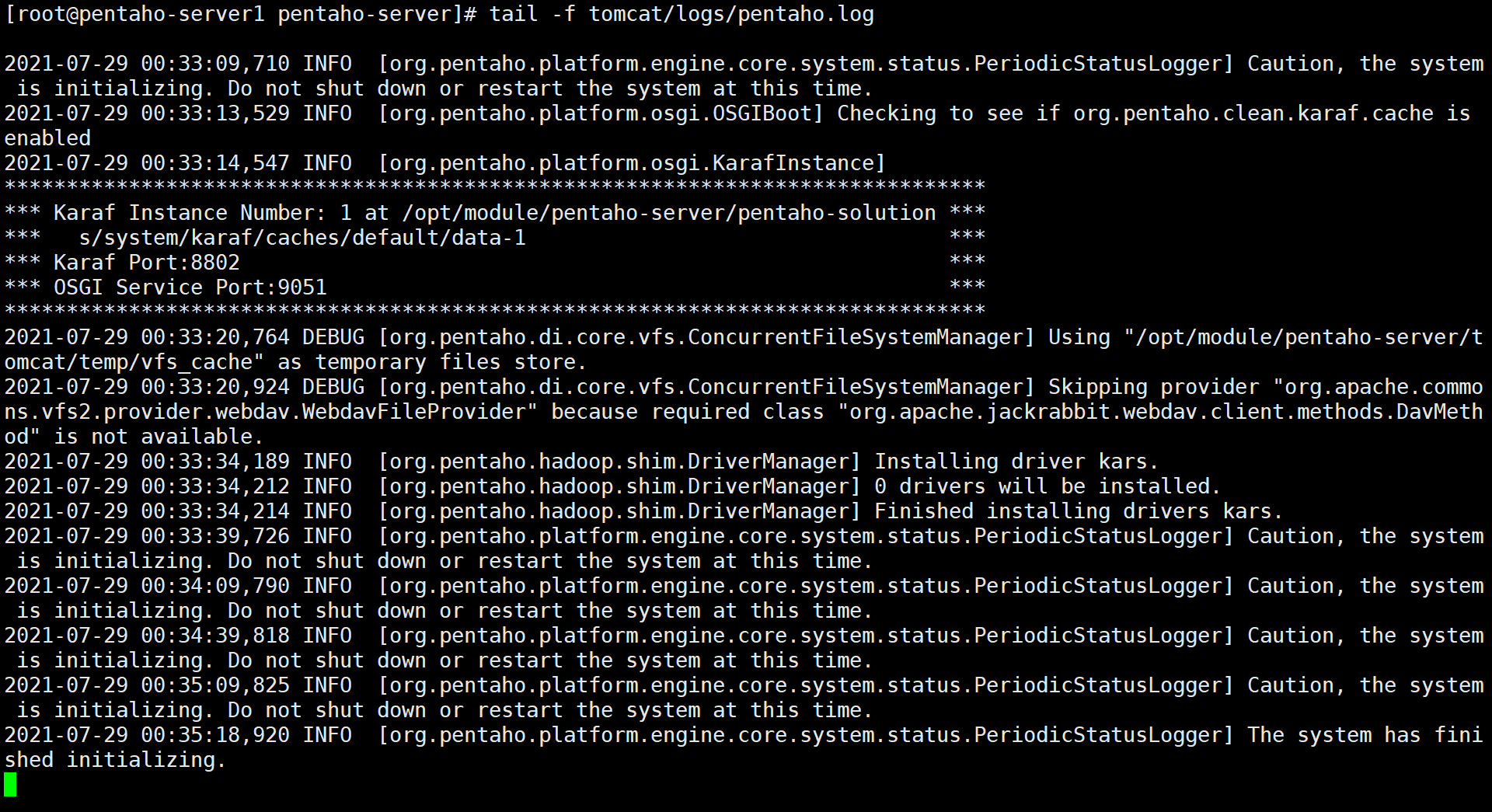
8.1、在pentaho-server1中启动并监听日志信息是否有报错
[root@pentaho-server1 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server1 pentaho-server]# ./start-pentaho.sh
[root@pentaho-server1 pentaho-server]# tail -f tomcat/logs/pentaho.log
8.2、在pentaho-server2中启动并监听日志信息是否有报错
[root@pentaho-server2 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server2 pentaho-server]# ./start-pentaho.sh
[root@pentaho-server2 pentaho-server]# tail -f tomcat/logs/pentaho.log
8.3、在pentaho-server3中启动并监听日志信息是否有报错
[root@pentaho-server3 ~]# cd /opt/module/pentaho-server/
[root@pentaho-server3 pentaho-server]# ./start-pentaho.sh
[root@pentaho-server3 pentaho-server]# tail -f tomcat/logs/pentaho.log
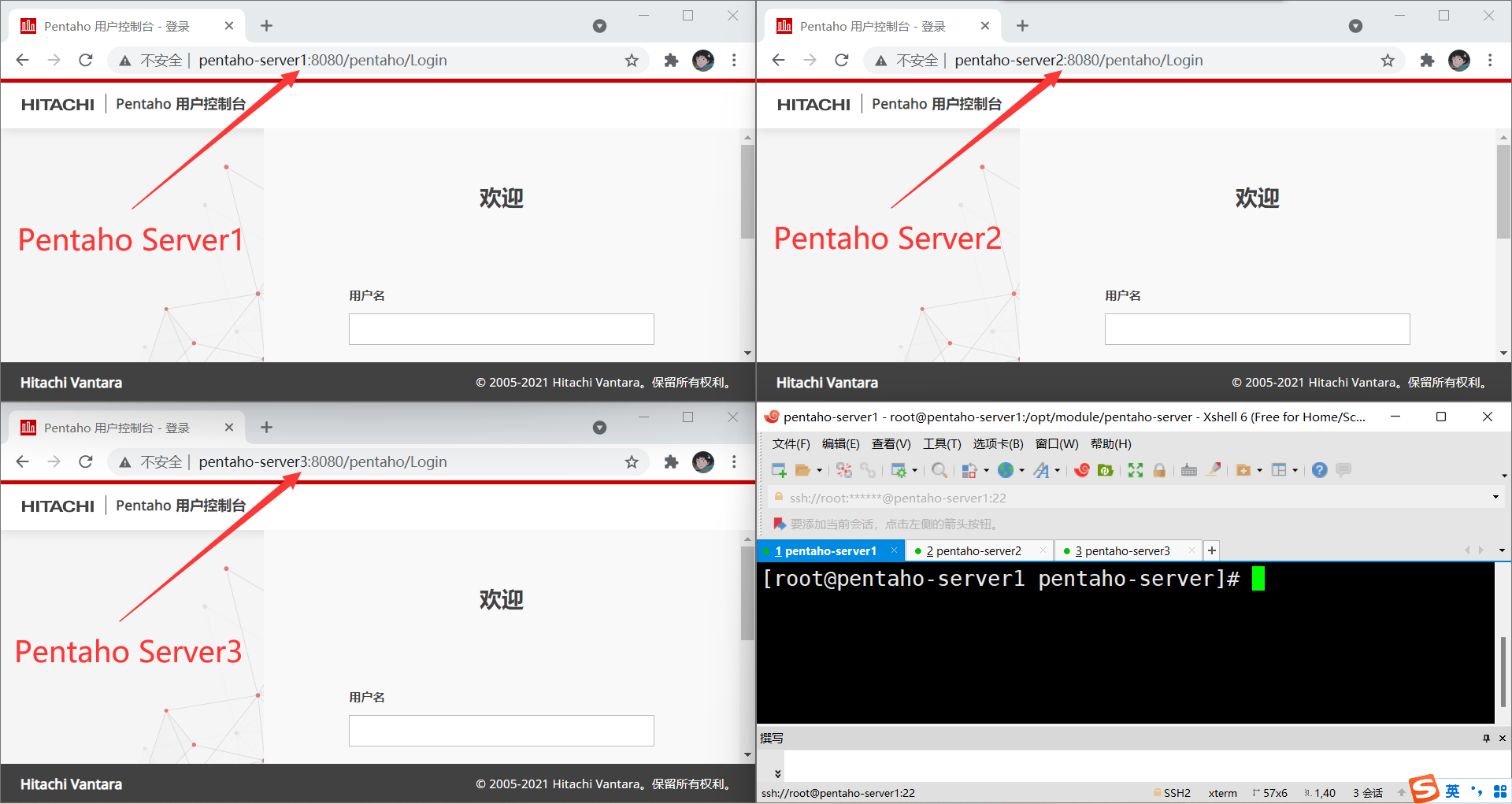
9、在浏览器中测试各服务节点是否能正常访问,用户名:admin、默认密码:password
三、配置Nginx反向代理与负载均衡(nginx-mysql节点)
1、添加pentaho.conf的Nginx配置文件
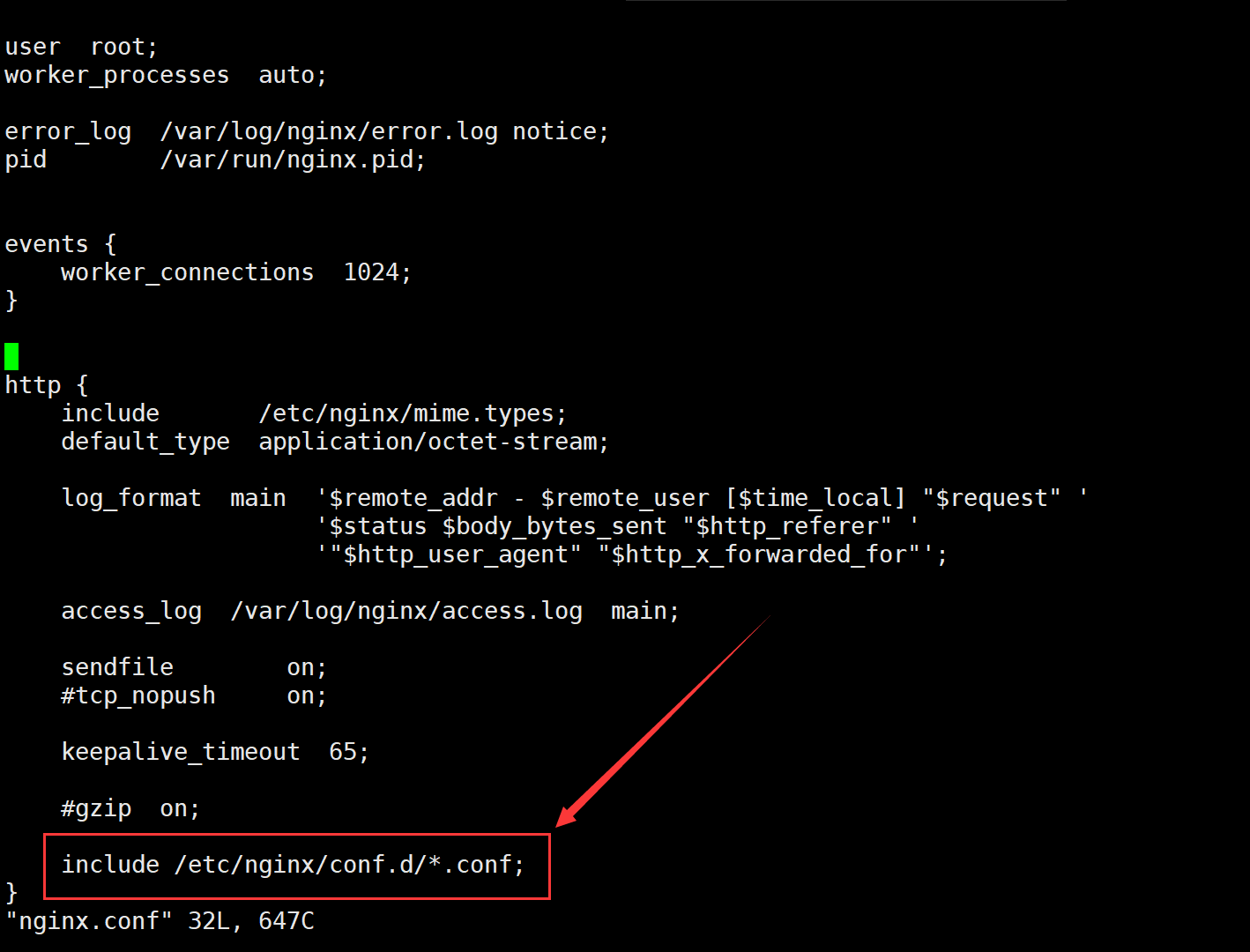
1.1、通过查看Nginx的主配置文件可知,Nginx会将/etc/nginx/conf.d/目录下的所有.conf结尾的配置文件导入主配置文件中
[root@nginx-mysql ~]# cd /etc/nginx/
[root@nginx-mysql nginx]# vim nginx.conf
1.2、在/etc/nginx/conf.d/目录下新建pentaho.conf配置文件,并加入如下配置内容
[root@nginx-mysql nginx]# cd conf.d/
[root@nginx-mysql conf.d]# vim pentaho.conf
upstream pentaho {server pentaho-server1:8080;server pentaho-server2:8080;server pentaho-server3:8080;ip_hash;
}server {listen 8080;server_name localhost;access_log /tmp/logs/nginx/pentaho-access.log;error_log /tmp/logs/nginx/pentaho-error.log;location / {proxy_pass http://pentaho;proxy_set_header Host $host:8080;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;}
}
2、检查配置文件是否有误并重启nginx
[root@nginx-mysql ~]# nginx -t
[root@nginx-mysql ~]# nginx -s reload

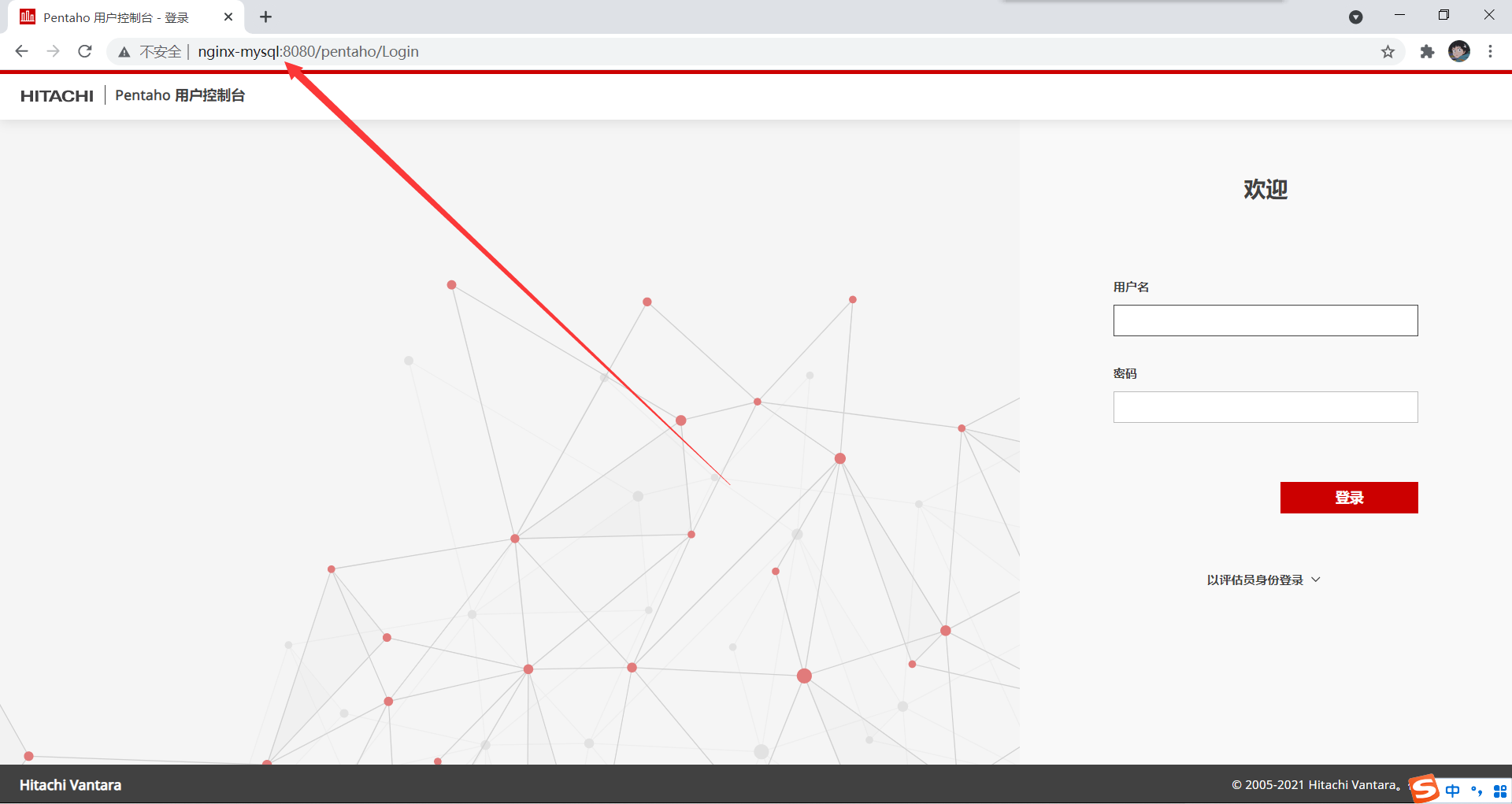
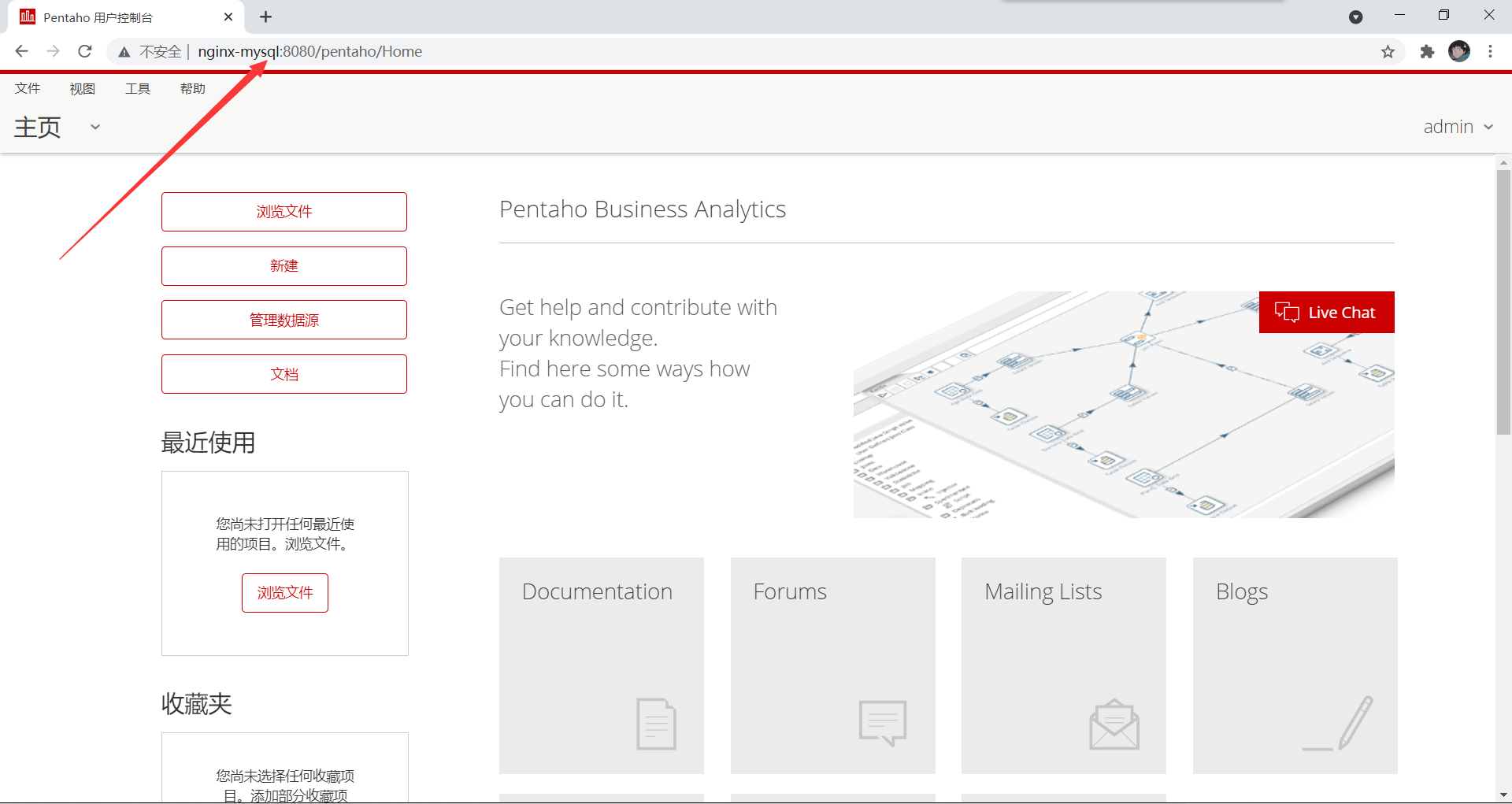
3、配置好并重启nginx后,测试是否能正常访问
四、客户端连接测试
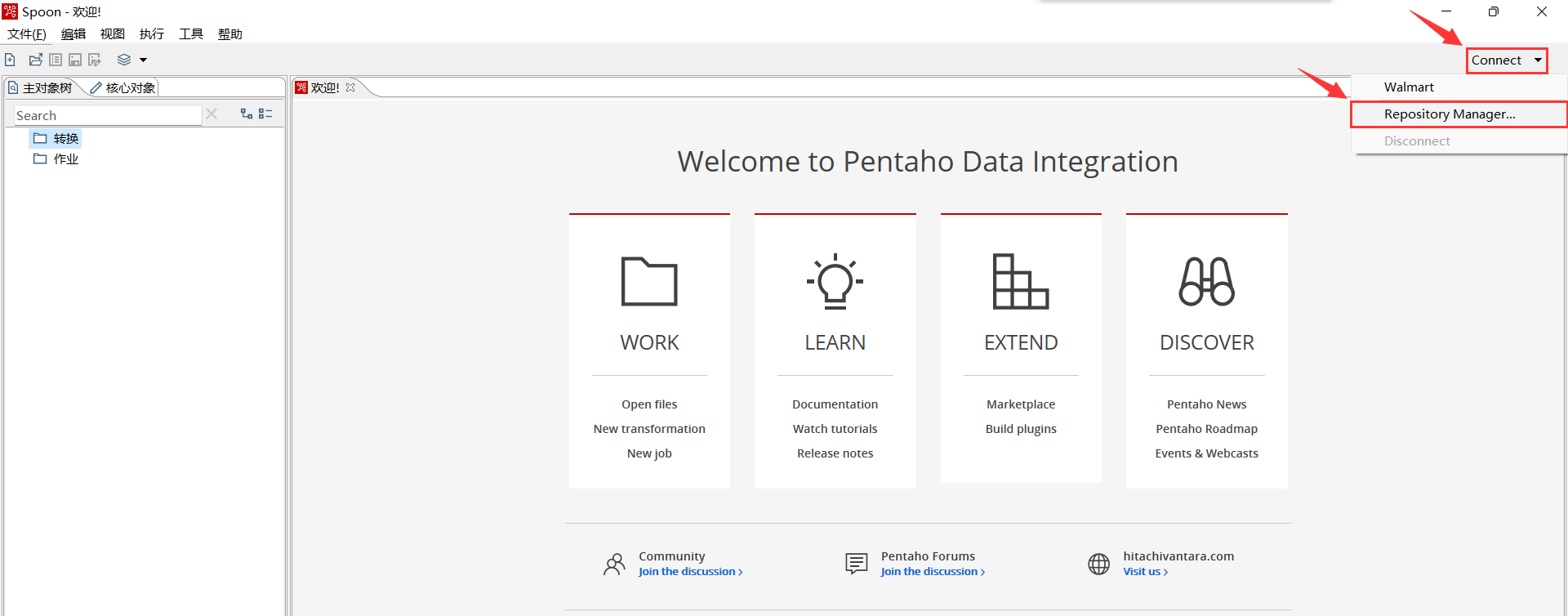
1、打开客户端工具,点击右上角的Connect、接着点击Repository Manager
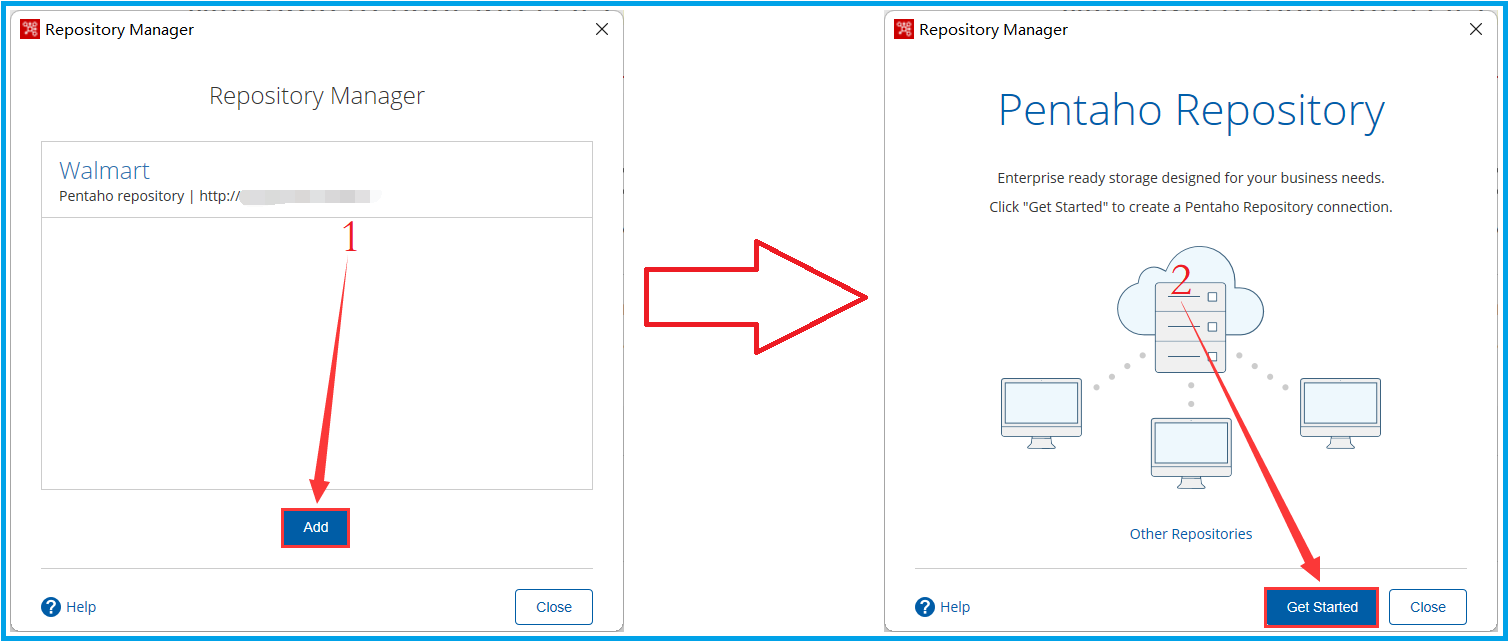
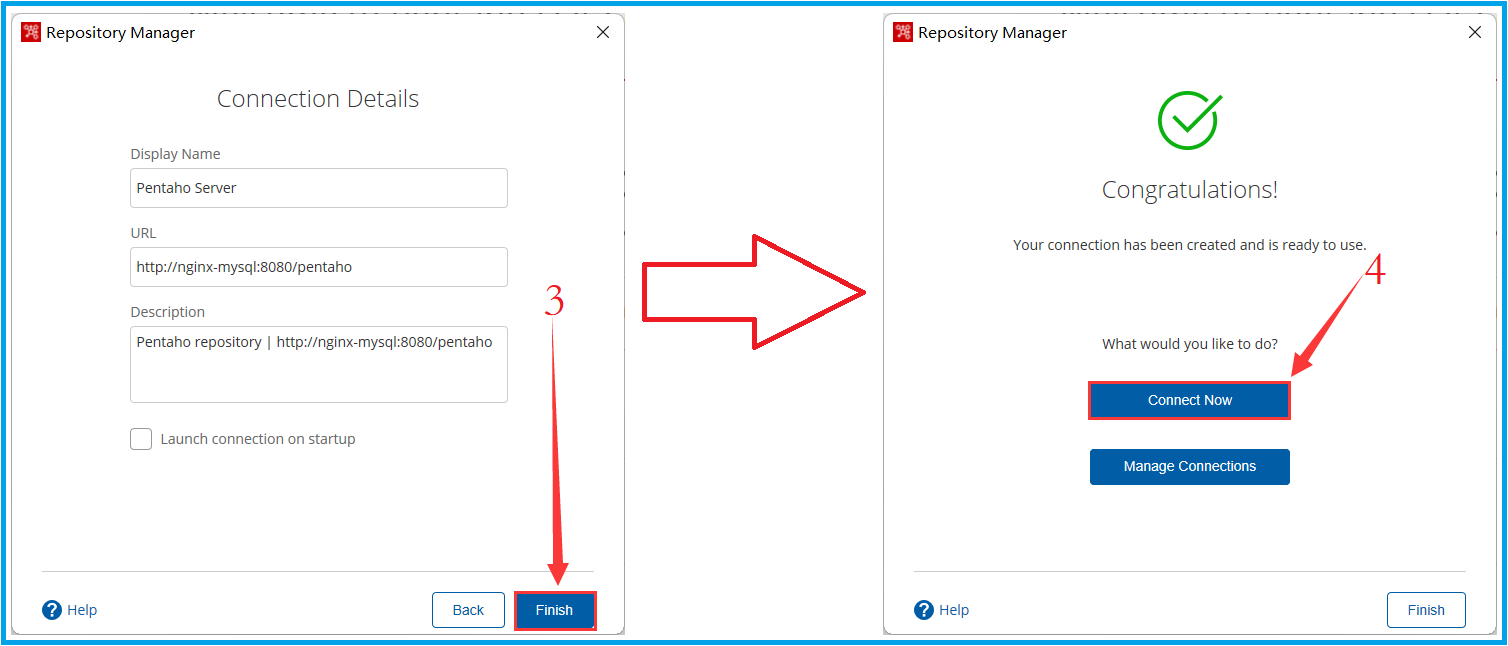
2、根据下图步骤,填写连接信息
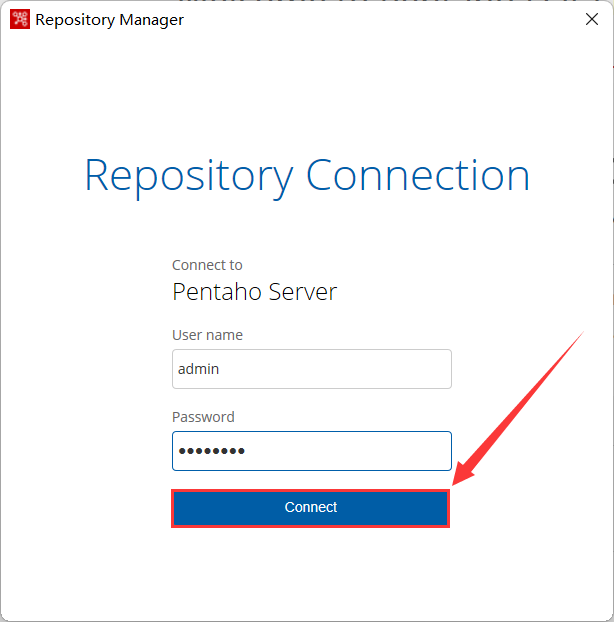
3、输入用户名和密码后点击Connect即可连接到Pentaho Server
4、测试创建一个 作业或者转换 并将其保存到合适的位置
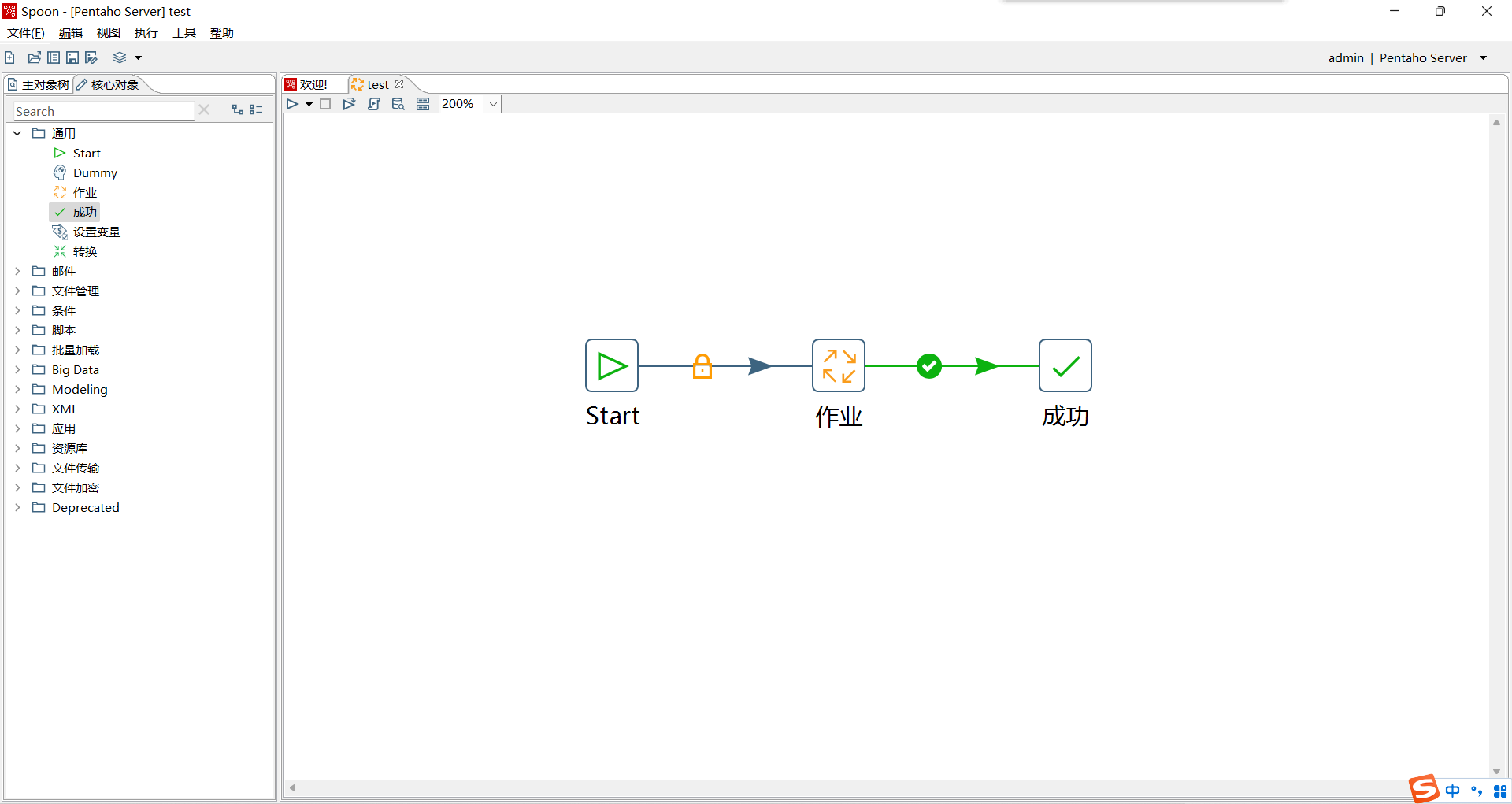
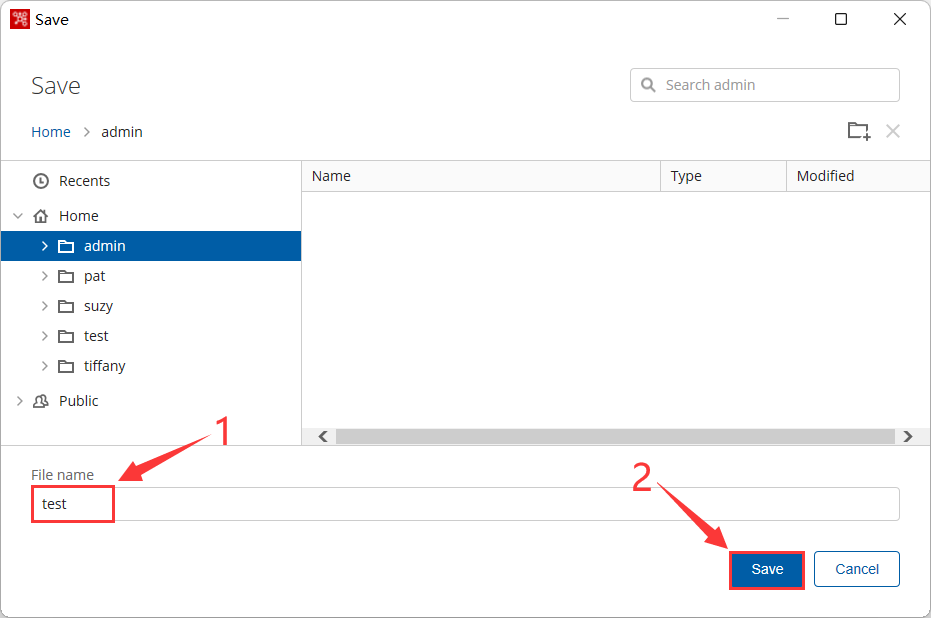
5、访问WEB端浏览文件存储的对应位置即可查看到上一步保存的 作业
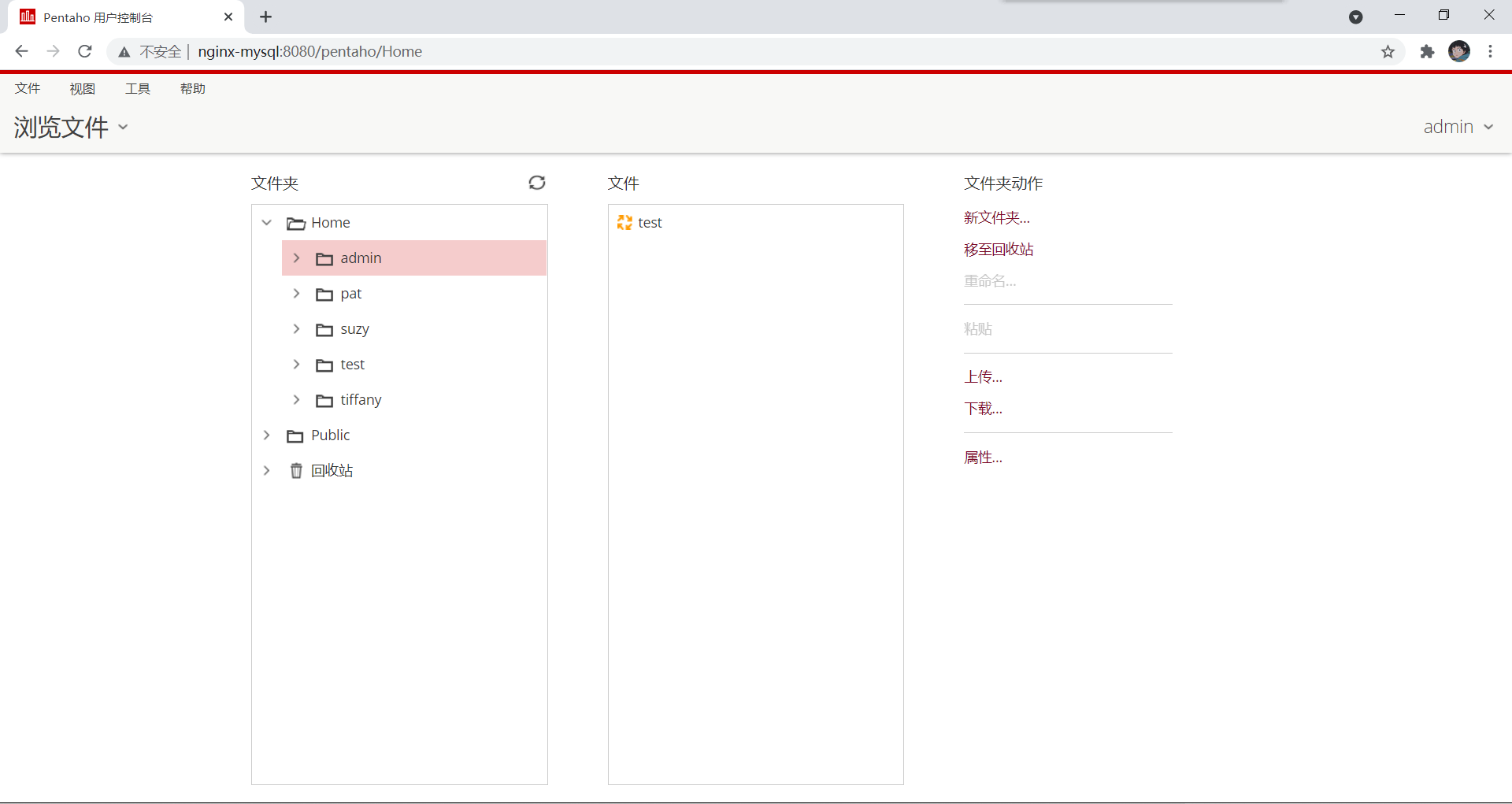
以上为Pentaho Server集群部署教程!
这篇关于在Linux中搭建Pentaho Server集群,并使用MySQL作为存储库、Nginx做反向代理与负载均衡的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



