本文主要是介绍Hive SQL编译成MapReduce任务的过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 Hive 底层执行架构
1.1 Hive底层架构

1.2 Hive与Hadoop交互过程
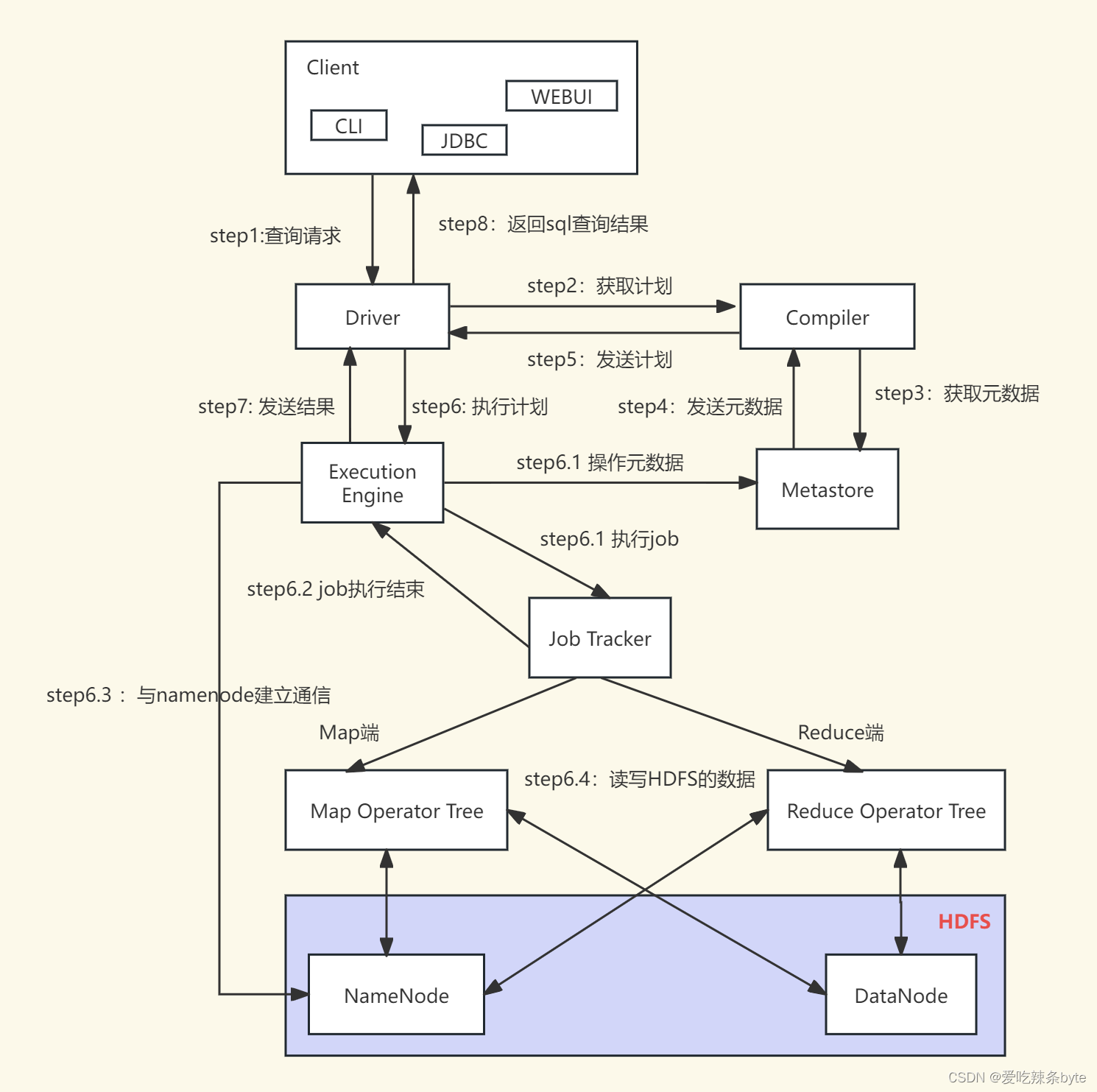
上图的基本流程是:
- 步骤1:Client 客户端调用 Driver的接口;
- 步骤2:Driver驱动器为查询创建会话句柄,并将查询发送到 Compiler(编译器组件)生成执行计划;
- 步骤3和4:编译器从元数据存储库中获取本次查询所需要的元数据;
- 步骤5:编译器生成各个阶段Stage的执行计划,如果是一个MR任务,该执行计划分为两部分:Map Operator Tree(map端的执行计划树)和Reduce Operator Tree(reduce端的执行计划树),再将生成的计划发给Driver;
- 步骤6:Driver将执行计划发给执行引擎Execution Engine;
步骤6.1 / 6.2 /6.3 /6.4:执行引擎将这些阶段Stage的具体执行内容提交给对应的组件。在每个 Task(mapper/reducer) 任务中,从HDFS文件中读取与表相关的数据,并通过算子树依次传递。最终的数据集借助序列化器写入到临时的HDFS文件中。
- 步骤7、8:临时HDFS文件的内容由执行引擎读取后,通过Driver驱动器发送给Client 客户端
二、Hive SQL 编译成MR任务的流程
2.1 HQL转换为MR源码整体流程介绍

2.2 程序入口—CliDriver
我们执行一个 HQL 语句通常有以下几种方式:1 ) $HIVE_HOME/bin/hive 进入客户端,然后执行 HQL ;2 ) $HIVE_HOME/bin/hive -e “hql” ;3 ) $HIVE_HOME/bin/hive -fhive.sql ;4 )先开启 hivesever2 服务端,然后通过 JDBC 方式连接远程提交 HQL 。可以知道我们执行 HQL 主要依赖于 $HIVE_HOME/bin/hive 和 $HIVE_HOME/bin/而在这两个脚本中,最终启动的 JAVA 程序的主类为“ org.apache.hadoop.hive.cli.CliDriver ” ,所以其实 Hive程序的入口就是“CliDriver ”这个类。
2.3 HQL编译成MR任务的详细过程—Driver

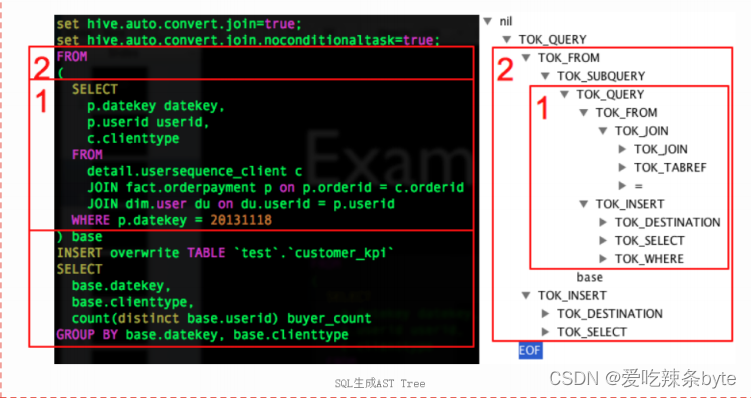
2.3.1 将HQL语句转换成AST抽象语法树
- 词法、语法解析: Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
例如:AST如下图:
2.3.2 将AST转换成TaskTree
语义解析: 遍历 AST Tree,抽象出一条SQL最基本组成单元 QueryBlock(查询块),该块包括三个部分:输入源,计算过程,输出。简单而言一个QueryBlock就是一个子查询。
生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树 OperatorTree(操作树,也就是逻辑执行计划);Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。基本的操作符包括:
TableScanOperator
SelectOperator
FilterOperator
JoinOperator
GroupByOperator
ReduceSinkOperator
Operator操作算子在Map Reduce阶段之间的数据传递是一个流式的过程。每一个Operator对一行数据操作之后将数据传递给childOperator计算。
由于Join/GroupBy需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce KeyReduce /value, Partition Key。
优化逻辑执行计划: 逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少数据传输及 shuffle 数据量;
Hive中的逻辑查询优化可以大致分为以下几类:
投影修剪
谓词下推
多路 Join
生成物理执行计划: 遍历 OperatorTree,转换成MR任务。生成物理执行计划即是将逻辑执行计划生成的OperatorTree转化为MapReduce Job的过程。
HQL编译成MapReduce具体原理:
以下面这个SQL为例,阐述join的实现过程:
select u.name, o.orderid
from order o
join user u on o.uid = u.uid;
执行流程图: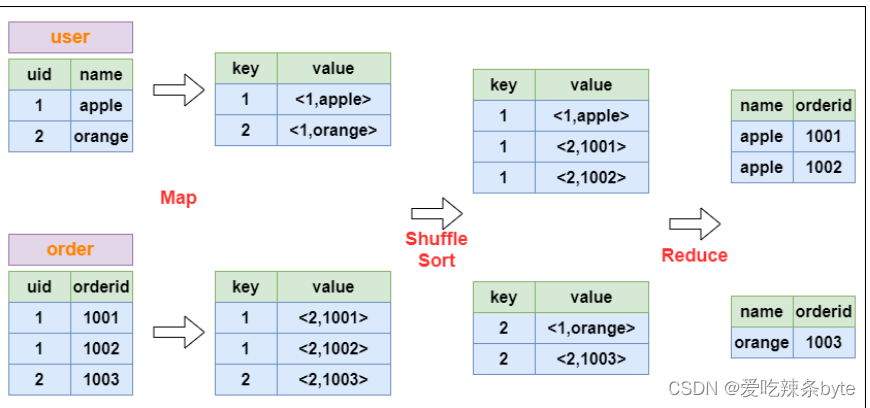
- 优化物理执行计划:物理优化器对进行TaskTree进行物理优化;
Hive中的物理优化可以大致分为以下几类:
分区修剪(Partition Pruning)
基于分区和桶的扫描修剪(Scan pruning)
在某些情况下,在 mapper端进行 Group By分组的预聚合
在 mapper端执行Join(map join)
如果是简单的select查询,可以设置为本地执行,避免使用MapReduce作业
经过2.3.1 及2.3.2 这六个阶段,HQL就被解析映射成了集群上的 MR任务。
2.3.3 提交任务并执行
- 获取MR临时工作目录
- 定义Partitioner
- 定义Mapper和Reducer
- 实例化Job任务
- 提交Job任务并执行
这篇关于Hive SQL编译成MapReduce任务的过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







